Slackware Linux Essentials
Segunda Ediçăo
Publicaçăo: Maio 2005
isbn: 1-57176-338-4
Slackware Linux Essentials, Second Edition
Copyright © 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005 Slackware Linux, Inc.
All rights reserved. Printed in Canada.
Published by Slackware Linux, Inc., 1164 Claremont Drive, Brentwood, CA 94513
Lead Author, Second Edition: Alan Hicks.
Editors, Second Edition: Murray Stokely and FuKang Chen.
Authors, First Edition: Chris Lumens, David Cantrell, and Logan Johnson.
Print History:
June, 2000 First Edition
May, 2005 Second Edition
Slackware Linux is a registered trademark of Patrick Volkerding and Slackware Linux, Inc.
Linux is a registered trademark of Linus Torvalds.
America Online and AOL are registered trademarks of America Online, Inc. in the United States and/or other countries.
Apple, FireWire, Mac, Macintosh, Mac OS, Quicktime, and TrueType are trademarks of Apple Computer, Inc., registered in the United States and other countries.
IBM, AIX, EtherJet, Net?nity, OS/2, PowerPC, PS/2, S/390, and ThinkPad are trademarks of International Business Machines Corporation in the United States, other countries, or both.
IEEE, POSIX, and 802 are registered trademarks of Institute of Electrical and Electronics Engineers, Inc. in the United States. Intel, Celeron, EtherExpress, i386, i486, Itanium, Pentium, and Xeon are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries.
Microsoft, IntelliMouse, MS-DOS, Outlook, Windows, Windows Media and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Netscape and the Netscape Navigator are registered trademarks of Netscape Communications Corporation in the U.S. and other countries.
Red Hat, RPM, are trademarks or registered trademarks of Red Hat, Inc. in the United States and other countries.
XFree86 is a trademark of The XFree86 Project, Inc.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this document, and Slackware Linux, Inc. was aware of the trademark claim, the designations have been followed by the '''tm''' or the ® symbol.
Prefácio
Público Alvo
O sistema operacional Slackware Linux é uma poderosa plataforma baseada em computadores i386. Ele foi projetado para ser estável, seguro e funcional como servidor, e também uma poderosa estaçăo de trabalho.
Este livro foi feito para que vocę comece com o sistema operacional Slackware Linux. Isto năo siginifica que iremos abordar cada detalhezinho da distribuiçăo, mas mostraremos rapidamente do que ela é capaz dando o conhecimento para trabalhar com o básico do sistema.
Como vocę ganhará experięncia com o Slackware, esperamos que vocę busque este livro para ser uma referęncia acessível. Nós também esperamos que o empreste para os seus amigos quando eles vierem perguntar sobre o sistema operacional Linux que vocę está usando.
Mesmo que esse livro năo vá fazer vocę pular de emoçăo, nós certamente tentamos fazę-lo o mais interessante possível. Com alguma sorte dará um filme. Claro, nós esperamos também que vocę possa aprender com ele e o ache útil.
E agora, comecemos com o show.
Mudanças da Primeira Ediçăo
Esta é a segunda ediçăo, resultado de vários anos de trabalho duro dos membros dedicados do Projeto de Documentaçăo do Slackware. A seguir estăo as mudanças de maior valor nesta nova ediçăo:
Organizaçăo deste Livro
Capítulo 1, Introduçăo
Capítulo 2, Ajuda
Capítulo 3, Instalaçăo
Capítulo 4, Configuraçăo do Sistema
Capítulo 5, Configuraçăo da Rede
Capítulo 6, O Sistema de Janelas X
Capítulo 7, Inicializaçăo
Capítulo 8, O Shell
Capítulo 9, Estrutura do Sistema de Arquivos
Capítulo 10, Manipulando Arquivos e Diretórios
Capítulo 11, Controle de Processos
Capítulo 12, Fundamentos para Administraçăo do Sistema
Capítulo 13, Comandos Básicos de Rede
Capítulo 14, Segurança
Capítulo 15, Arquivos Compactados
Capítulo 16, vi
Capítulo 17, Emacs
Capítulo 18, Gerenciamento de Pacotes do Slackware
Capítulo 19, ZipSlack
Appendix A, Licença Pública Geral GNU
Convençőes usadas neste livro
Para fornecer uma consistente e fácil leitura do texto, diversas convençőes foram seguidas durante todo o livro.
Convençőes Tipográficas
- Fontes em itálico săo usada para comandos, texto enfatizado, e os termos técnicos de primeiro uso.
Entrada do Usuário
Teclas săo mostradas em negrito para se destacarem de outros textos. Combinaçőes de teclas que possuem certo objetivo por serem digitadas simultaneamente, săo mostradas com `+' entre as teclas, como:
Ctrl + Alt + Del
Desse modo o usuário deve digitar as teclas Ctrl, Alt, e Del ao mesmo tempo.
Teclas que possuem certo objetivo por serem digitadas em sequęncia que irăo ser separadas por vírgulas, por exemplo:
Ctrl+X, Ctrl+S
Significaria que é esperado que o usuário digite as teclas Ctrl e X simultaneamente e entăo digite as teclas Ctrl e S simultaneamente.
Exemplos
Exemplos começando com \\ E:>\\ indica um comando \\MS-DOS\\. A menos que seja conhecido de outra forma, estes comandos podem ser executados de uma janela de "Prompt de Comandos" do ambiente moderno do Microsoft Windows.
D:> rawrite a: bare.i
Exemplos começando com &prompt.root; indica que o comando que deve ser usado pelo super-usuário no Slackware. Vocę pode iniciar uma sessăo como root para digitar o comando, ou iniciar com uma conta normal e usar &man.su.1; para ganhar privilégio de super-usuário.
# dd if=bare.i of=/dev/fd0
Exemplos começando com &prompt.user; indicam que o comando pode ser usado em uma conta de usuário normal. A menos que seja conhecido de outra forma, a sintaxe C-shell é usada para ajustar as variáveis de ambiente e outros comandos de shell.
$ top
Agradecimentos
Este projeto é o acumulo de meses de trabalho de muitas pessoas dedicadas. Năo seria possível para mim produzir este trabalho do zero. Muitas pessoas merecem nossos agradecimentos por seus atos de ajuda: Keith Keller por seu trabalho em rede wireless, Joost Kremers por seu maravilhoso trabalho escrito sem colaboradores da seçăo Emacs, Simon Williams por seu capítulo sobre segurança, Jurgen Phillippaerts pelos comandos básicos de rede, Cibao Cu Ali G Colibri pela inspiraçăo e o ponta-pé inicial. Sem contar outros que nos enviaram sugestőes e reparos. Uma lista incompleta inclui: Jacob Anhoej, John Yast, Sally Welch, Morgan Landry, e Charlie Law. Tenho também de agradecer Keith Keller por hospedar a lista de emails desse projeto, bem como Carl Inglis pela hospedagem inicial do site. Por último mas năo menos importante, tenho que agradecer a Patrick J. Volkerding pelo Slackware, e David Cantrell, Logan Johnson, e Chris Lumens pelo Fundamentos do Slackware Linux 1Ş Ediçao. Sem sua estrutura inicial, nada disso teria acontecido. Muitos outros contribuiram com pequenas e grandes partes desse projeto e năo foram listadas. Espero que me perdoem por minha memória fraca.
Alan Hicks, Maio 2005
Linus Torvalds criou o Linux, o núcleo do sistema operacional, como um projeto pessoal em 1991. Ele iniciou o projeto porque procurava rodar um sistema operacional baseado em Unix mas năo possuia muito dinheiro. além disso, Ele procurava aprender sobre a arquitetura do processador 386. O Linux é liberado livre de cobrança para o público assim qualquer pessoa pode ajudar estudando-o e fazendo melhorias sobre a licença pública geral. (veja Código Aberto e Software Livre e Apęndice A para uma explicaçăo da licença.) Hoje o linux cresceu como um dos principais jogadores no mercado de sistema operacional. Ele foi portado para rodar em uma variedade de arquiteturas, incluindo HP/Compaq's Alpha, Sun's SPARC e UltraSPARC, e Motorola's PowerPC chips (através Apple Macintosh e computadores IBM RS/6000.) centenas, se năo milhares, de programadores em todo o mundo desenvolve o Linux. Ele roda programas como Sendmail, Apache, e BIND, que săo softwares bastante populares usado em servidores de internet. É importante lembrar que o termo "Linux" realmente se refere ao kernel - o núcleo do sistema operacional. Este núcleo é responsável por controlar o processador do seu computador, memória, discos rígidos e periféricos. Aquilo tudo é realmente o Linux: Controla as operaçőes do seu computador e certifica-se de que todos os seus programas se comportam. Existem várias companhias e indivíduos que empacotam o kernel e vários programas juntos para fazer um sistema operacional. Nós chamamos cada pacote de uma distribuiçăo Linux.
O projeto do Kernel Linux começou com um esforço pessoal de Linus Torvalds em 1991, mas como Isaac Newton disse uma vez, "Se consegui enxergar mais longe, é porque estava apoiado sobre ombros de gigantes.". Quando Linus Torvalds criou o Kernel a Free Software Foundation tinha estabelecido já a idéia do software colaborativo. Intitularam seu esforço GNU, um acrônimo recursivo que significa simplesmente GNU's Not Unix. O Software da GNU funciona sobre o kernel do Linux desde o 1ş dia. O compilador gcc foi usado usado para compilar o kernel. Hoje muitas ferramentas da GNU, do gcc ao gnutar estăo ainda na base de cada distribuiçăo principal do Linux. Por esta razăo muitos dos membros da Free Software Foundation sugerem fervorosamente que seu trabalho deve ser dado o mesmo crédito que o kernel Linux e ainda que todas as distribuiçőes de Linux devem se referir a ele como distribuiçőes de GNU/Linux.
O prefixo "GNU" em "GNU/Linux" é o tema de inúmeras flamewars; só a guerra santa entre Emacs e vi gera mais brigas. O objetivo deste livro năo é alimentar as chamas da discussăo, e sim esclarecer a terminologia para os neófito. Quando vemos "GNU/Linux" isso quer dizer uma distribuiçăo Linux; quando vemos "Linux" o termo pode estar se referindo tanto ao kernel quanto ŕ distribuiçăo inteira, o que pode ser um pouco confuso; e o termo "GNU/Linux" muitas vezes năo é usado por ser longo demais.
O Slackware, criado por Patrick Volkerding no fim de 1992, e inicialmente lançado para o mundo em 17 de Julho de 1993, foi a primeira distribuiçăo Linux a alcançar um uso bastante difundido.
Volkerding iniciou o aprendizado no linux quando precisou de um interpretador de LISP para um projeto. Uma das poucas distribuiçőes disponíveis naquele tempo era a SLS Linux de Soft Landing Systems. Volkerding usou o SLS Linux, corringindo os bugs que encontrava.
Eventualmente, decidiu juntar todos estes bugfixes em sua própria distribuiçăo privada que ele e seus amigos poderiam usar. Esta distribuiçăo privada ganhou rapidamente a popularidade, assim que Volkerding decidiu nomeá-lo para Slackware e distribui-lo publicamente. Ao longo, Patrick adicionou coisas novas ao Slackware; um programa de instalaçăo amigável para o usuário e baseado em um sistema de menu, também com o conceito de geręnciamento de pacote, na qual permite que os usuários facilmente adicionem, removam ou atualizem um programa ou o seu sistema inteiro.
Há muitas razőes porque o Slackware é a distribuiçăo Linux mais antiga em atividade. Năo tenta imitar o Windows, tenta ser o mais similar ao Unix possível. Ele năo esconde seus processos atrás de uma interface gráfica de apontar e clicar; ao invés disso ele pőe os usuários no controle e mostra para eles exatamente o que está acontecendo. Seu desenvolvimento năo é acelerado artificialmente para cumprir prazos - cada versăo só é lançada quando realmente está pronta.
O Slackware é para as pessoas que gostam de aprender e fazer com o sistema exatamente o que quer. O que permite que o Slackware será usado por vários anos é a sua simplicidade e estabilidade. O Slackware atualmente possui uma reputaçăo de um servidor estável e uma rápida estaçăo de trabalho, Vocę poderá encontrar desktops com Slackware funcionando quase todos com um gerenciador de janelas ou com ambiente de trabalho, ou sem nenhum. Os Servidores Slackware aumentam os negócios, aumentando a capacidade para os usuários do servidor, Os usuários de Slackware săo entre todos usuários os mais satisfeitos com o Linux. Naturalmente, nós diríamos isso. :^)
Dentro da comunidade Linux, existem dois principais movimentos ideológicos em atividade. O movimento de Software livre (nós começaremos em instantes) que está trabalhando com o objetivo de fazer todo o software livre das restriçőes da propriedade intelectual. Os seguidores deste movimento acreditam que as restriçoes impedem as melhorias tecnicas e o trabalho contrário ao bem da comunidade. O movimento de código aberto está trabalhando praticamente com os mesmos objetivos, mas tomadas uma aproximaçăo mais pragmática a elas. Os seguidores deste movimento preferem basear seus argumentos nos méritos econômicos e técnicos de fazer o código fonte livremente disponível, melhor que os princípios morais e éticos que dirigem o movimento de Software Livre, No extremo oposto da visăo estăo os grupos que desejam manter um controle em exesso sobre seus softwares.
O movimento de software livre é dirigido pela Free Software Foundation, uma organizaçăo de levantamento de fundos para o projeto GNU. O software livre é mais que uma ideologia. A expressăo usada com frequęncia é livre como um discurso, mas năo como cerveja grátis. Essencialmente, o software livre é uma tentativa de garantir determinados direitos para os usuários e desenvolvedores. Esta liberdade incluem a liberdade para executar o programa sem uma razăo, para estudar e modificar o código fonte, para redistribuir o código fonte e para compartilhar de quaisquer modificaçőes que vocę fizer. A fim de garantir esta liberdade, a licença pública geral da GNU (GPL) foi criado. A GPL, sendo breve, prover que qualquer um que distribui um programa compilado que seja licenciado sob a GPL deve também fornecer o código fonte, e é livre para fazer modificacőes no programa e aquelas modificaçőes feitas também estarăo disponíveis na forma de código fonte. Isto garante que uma vez que um programa é aberto ŕ comunidade, năo pode ser fechado exceto pelo consentimento de cada autor de cada parte do código (mesmo as modificaçőes) dentro dele. A maioria dos programas para o Linux estăo licenciados sob a GPL.
É importante notar que a GPL năo diz qualquer coisa sobre o preço. Tăo ímpar como pode soar, vocę pode cobrar pelo software livre. A parte livre está na liberdade que vocę tem com o código fonte, năo no preço que vocę paga pelo software. (entretanto, uma vez que alguém o vendeu, ou tenha dado um programa compilado licenciado sob a GPL săo obrigados a fornecer também o código fonte.)
Outra licença popular é a licença BSD. Em contraste com a GPL, a licença BSD năo impőe nenhuma exigęncia para a liberaçăo do código fonte de um programa. Os Softwares lançado sobre a licença BSD permitem redistribuir em código fonte ou em binário uma forma de providenciar apenas algumas condiçőes. O crédito do autor năo pode ser usados como um caráter de propaganda para o programa. Imuniza também o autor da responsabilidade para os danos que podem se levados pelo uso do software. Muito dos softwares incluído no Slackware Linux săo licenciados pela BSD.
Na linha de frente do jovem movimento de código aberto, A OSI é uma organizaçăo que existe unicamente para avançar a sustentaçăo para o software de código aberto, isto é, o software ter o código aberto disponivel perfeitamente para ler e executar o programa. Năo oferecem uma licença específica, mas em substituiçăo suportam os vários tipos de licenças de códigos abertos.
A ideia atrás da OSI é trazer mais companhias para o código aberto permitindo que escrevam suas próprias licenças de código aberto e tenham aquelas licenças certificadas pela Open Source Initiative. Muitas companhias querem liberar o código fonte, mas năo querem usar a GPL. Desde que năo podem radicalmente mudar a GPL, săo oferecidas a oportunidade de fornecer sua própria licença e de tę-la certificada por esta organizaçăo.
Quando a Free Software Foundation e a Open Source Initiative trabalharem para se ajudarem, elas năo săo a mesma coisa. A Free Software Foundation usa uma licença específica e fornece o software sob esta licença, A Open Source Initiative busca dar suporte para todas a licenças abertas, incluindo uma para a Free Software Foundation. Toda a sustentaçăo aberta das buscas da Open Source Initiative para abrir o código fonte, inluindo a Free Software Foundation. As regiőes em que cada uma discute fazendo o código fonte livremente disponível dividem ŕs vezes os dois movimentos, mas o fato de que dois grupos ideologicamente diferentes estăo trabalhando para o mesmo objetivo, isso dar crédito aos esforços de cada um.
Muitas vezes vocę precisa de ajuda para um comando específico, para iniciar um programa, ou simplesmente saber como um hardware trabalha. Talvez vocę queira saber mais opçőes que possam ser utilizadas em um determinado comando, ou apenas verificar quais opçőes estăo disponíveis para serem utilizadas em um determinado comando. Felizmente, existem várias maneiras de vocę obter ajuda para o que está procurando. Quando vocę instala o Slackware vocę tem a opçăo de instalar os pacotes da série F que inclui FAQs e HOWTOs. Alguns programas também possuem ajuda sobre outras opçőes, arquivos de configuraçăo e uso.
O comando man (abreviaçăo de manual) é a forma tradicional de documentaçăo online dos sistemas operacionais Unix e Linux. Composto de Linhas formatadas especialmente, as man page, săo escritas para a grande maioria dos programas e săo distribuídas com o próprio software. Executando man comando será mostrada a man page para o programa especificado, em nosso exemplo esse seria o comando imaginário comando.
Vocę deve imaginar a grande quantidade de páginas de manual que podem ser rapidamente criadas, tornaria-se confuso e complicado até mesmo para um usuário avançado. Devido a isso, ŕs páginas de manual săo divididas em seçőes numeradas. Este sistema esteve disponível por um longo tempo; vocę verá bastante comandos, programas e referęncias de funçőes de bibliotecas referęnciadas pelo número da seçăo do man.
Por exemplo:
Vocę pode fazer uma referęncia ao man(1). O número especifica que a man é documentada na seçăo 1 (comandos de usuários); vocę pode especificar que vocę quer a documentaçăo da seçăo 1 do man com o comando man 1 man. Especificar a seçăo é útil quando existe manuais em várias seçőes com o mesmo nome.
| Seçăo | Conteúdo |
| Seçăo 1 | Comandos de usuários (somente introduçăo) |
| Seçăo 2 | Chamadas do Sistema |
| Seçăo 3 | Chamadas de bibliotecas C |
| Seçăo 4 | Dispositivos (ex., hd, sd) |
| Seçăo 5 | Formatos de Arquivos e protocolos (ex., wtmp, /etc/passwd//, nfs) |
| Seçăo 6 | Jogos (somente introduçăo) |
| Seçăo 7 | Convençőes, pacotes macro, etc. (ex., nroff, ascii) |
| Seçăo 8 | Administraçăo do sistema (somente introduçăo) |
Em adicional ao comando man(1), existem os comandos whatis(1) e apropos(1) que estăo disponíveis para vocę, com a finalidade de encontrar uma informaçăo mais fácil no sistema.
O comando whatis dá uma descriçăo muito breve dos comandos do sistema, uma espécie de referęncia.
Exemplo:
% whatis whatis
whatis (1) - search the whatis database for complete words
O comando apropos é usado para procurar a página de manual que contęm uma determinada palavra..
Exemplo
$ apropos wav
cdda2wav (1) - a sampling utility that dumps CD audio data into wav sound files
netwave_cs (4) - Xircom Creditcard Netwave device driver
oggdec (1) - simple decoder, Ogg Vorbis file to PCM audio file (WAV or RAW)
wavelan (4) - AT&T GIS WaveLAN ISA device driver
wavelan_cs (4) - AT&T GIS WaveLAN PCMCIA device driver
wvlan_cs (4) - Lucent WaveLAN/IEEE 802.11 device driver
Caso queira alguma informaçăo adicional para algum destes comandos, leia a página de manual para maiores detalhes. ;)
A grande maioria dos softwares que instalamos vem com algum tipo de documentaçăo: arquivos README, instruçőes de uso, arquivos de licença, etc. Geralmente toda documentaçao que vęm com o software é instalada no sistema no diretório /usr/doc/. Cada programa geralmente instala sua documentaçăo na seguinte ordem:
/usr/doc/$programa-$versăo/
Onde $programa// é o nome do programa que vocę está querendo obter informaçőes, e $versăo// é (obviamente) a versăo do software que está instalado em seu sistema.
Por exemplo, para ler a documentaçăo do comando man(1) vocę digitaria cd no:
$ cd /usr/doc/man-$versăo/
Caso ao ler as informaçőes da página de manual vocę năo encontre informaçőes apropriadas o próximo passo é buscar informaçőes no diretório /usr/doc/.
O verdadeiro espírito da comunidade de Código Aberto cria uma grande coleçăo de HOWTO/mini-HOWTO. Esses arquivos săo exatamente - documentos e guias descrevendo como deve ser feito algo. Caso vocę decida instalar os HOWTO, eles serăo instalados no diretório /usr/doc/Linux-HOWTOs/ e os mini-HOWTOs em /usr/doc/Linux-mini-HOWTOs/.
A mesma série de pacotes inclui uma coleçăo de pacotes de FAQs, que é uma abreviaçăo para Frequently Asked Questions (em portuguęs seria Perguntas mais Frequentes)
Estes documentos săo escritos no estilo de Perguntas e Respostas. Os FAQs podem ser muito útil quando se procura algo onde se queira ter respostas rápidas para algo. Caso vocę decida instalar os FAQs durante a instalaçăo, vocę os encontrará instalados do diretótio /usr/doc/Linux-FAQs/.
Esses arquivos săo muito úteis quando vocę está com alguma dúvida e năo sabe como resolver o problema. Cobrem uma grande variedade de assuntos, mas năo cobrem os assuntos de maneira detalhada. Bom material!
Além da documentaçăo que é fornecida com a instalaçăo do Sistema Operacional Slackware Linux, existe uma grande variedade de documentaçăo disponível que vocę pode obter para aprender.
A todos que compram o conjunto oficial de CDs do projeto é oferecido suporte livre via e-mail pelo desenvolvedor. Por favor, isso que está sendo dito, deve ser mantido entre os colaboradores (e a grande maioria dos usuários) do Slackware A velha escola. Isso significa que nós preferimos ajudar ŕqueles que tęm um interesse sincero e estăo dispostos a ajudar no processo. Nós faremos sempre o melhor para ajudar quem nos envia um e-mail. Entretanto, Por favor verifique a documentaçăo e o site (especialmente os FAQs e talvez algum fórum listado abaixo) antes de enviar um e-mail. Vocę pode iniciar sua busca nas respostas simples, seria menos e-mail que teríamos que responder, obviamente nós ajudamos de uma forma melhor ŕqueles que precisam de nossa ajuda.
O endereço de e-mail para suporte técnico é: <support (a) slackware com>. Outros endereços de e-mail e informaçőes de contato săo listados no site oficial.
Existem algumas listas de e-mail disponíveis em forma de sumário ou formulário normal. Verifique as instruçőes para saber como se inscrever.
Para inscrever em uma lista de e-mail, envie uma mensagem para:
<majordomo (a) slackware com>
com a frase subscribe [nome da lista] no corpo da mensagem. A descriçăo das listas está abaixo (use o nome abaixo para o inscrever-se na lista).
Os arquivos da lista de e-mail podem ser encontrador no site do Slackware em:
http://slackware.com/lists/archive/
slackware-announce
A lista de e-mail slackware-announce é utilizada para anunciar novas versőes, principais atualizaçőes e outras informaçőes em geral.
slackware-security
A lista de e-mail slackware-security informa assuntos relacionados ŕ segurança. Exploits e outras vulnerabilidades que pertençam diretamente ao Slackware săo postadas na lista imediatamente.
As listas estăo disponiveis no formato de sumário. Isto é, ao invés de vocę receber várias mensagens durante o dia, vocę receberá apenas uma mensagem com todo o conteúdo criado no dia. A lista de e-mail do Slackware năo permite que usuários postem mensagem, e as listas possuem um tráfego baixo, muitos usuários encontram pouca vantagem em receber o sumário da lista. Caso vocę queira, ainda estăo disponíveis para inscriçăo a lista slackware-announce-digest ou slackware-security-digest.
O mestre do Kung-Fu para sites de busca. Absolutamente vocę, encontra as últimas informaçőes sobre o kernel com o título: Năo aceite substitutos.
Google:Linux (www.google.com/linux)
Procura especificamente por Linux
Google:BSD (www.google.com/bsd)
Procura especificamente por BSD. Slackware também é um sistema operacional genérico, assim como o Unix funciona, por isso, vocę também pode encontrar muitas informaçőes sobre Slackware. Muitas vezes uma busca, em BSD, pode trazer informaçőes técnicas relacionadas com o Linux.
Google:Groups (groups.google.com)
Busca por informaçőes nas mensagens de décadas da Usenet.
Um tesouro virtual de conhecimento, bom conselheiro, experięncias em primeira măo e artigos interessantes. O primeiro lugar que vocę ouvirá com freqüęncia sobre o desenvolvimento de Slackware no mundo.
O fórum oficial de usuários de Slackware.
"Um local para efetuar download e obter ajuda sobre Linux."
[alt.os.linux.slackware wombat.san-francisco.ca.us/perl/fom] FAQ
Outras FAQ
A USENET tem sido por muito tempo o lugar onde os geeks buscam ajuda e ajudem uns aos outros. Existem poucos grupos dedicados ao Slackware Linux, mas tendem a serem preenchidos com as grandes base de conhecimento de outras pessoas.
alt.os.linux.slackware
alt.os.linux.slackware, mais conhecida como aols, (năo confunda com a AOL!) é um dos lugares mais ativos para encontrar ajuda sobre problemas com o Slackware. Como cada grupo, alguns participam (ativamente) com experięncia pelo fato de ajudar bastante. Aprenda a ignorar trolls e identifique ajuda de pessoas que realmente utilizam esse recurso.
Antes que vocę possa usar o Slackware Linux, será necessário vocę obtę-lo e instalá-lo. Obter o Slackware é fácil, vocę pode compra-lo ou efetuar o download gratuíto através da Internet. A instalaçăo também é muito fácil, desde que vocę tenha conhecimento básico sobre seu computador e esteja disposto a aprender algumas coisas. O programa de instalaçăo o conduzirá passo-a-passo. Devido ao programa de instalçao vocę instalará rapidamente o sistema. O fato é que o Slackware possui um programa de instalaçăo mais rápido em relaçăo ŕ qualquer outra distribuiçăo Linux.
O conjunto de CDs oficial do Slackware Linux CD está disponível na Slackware Linux, Inc. O jogo consiste em 4 discos. O primeiro disco contęm todo o software necessários para um sistema básico e o gerenciados de janelas X. O segundo CD é um disco adicional; isto é, um CD bootável que instala na RAM uma instalaçăo provisória, caso seja necessário efetuar uma manutençăo de reparo na máquina. Este CD possui alguns pacotes, tais como os ambienes gráficos KDE e GNOME. Alguns pacotes novos săo inclusos no segundo CD incluindo a série de pacotes extra, que săo pacotes năo essenciais ao sistema. O terceiro e o quarto CD inclui todos os códigos fontes de todos os programas do Slackware, junto com a ediçăo original desse livro.
Também é possível comprar um kit contendo os 4 discos e uma cópia deste Livro, dessa forma vocę poderá se exibir como um verdadeiro geek. A compra dos CDs estăo disponíveis a um custo bem acessível.
A maneira preferida para a compra desses produtos é na loja oficial do Slackware.
Informaçőes de Contato na Slackware Linux, Inc.
| Method | Contact Details |
| Telephone | 1-(925) 674-0783 |
| Site | http://store.slackware.com |
| <orders (a) slackware com> | |
| Postal | 1164 Claremont Drive, Brentwood, CA 94513 |
Slackware Linux está totalmente Livre na Internet. Vocę pode enviar suas perguntas por email, mas a prioridade será ŕs perguntas referentes ŕ compras do kit oficial. Como dito anteriormente, nós recebemos muitos e-mails, e o tempo é muito limitado para poder atender a todos. Antes de enviar um e-mail para suporte primeiramente leia a ajuda.
O site oficial do Projeto Slackware Linux Project é o endereço:
A localizaçăo do FTP primário para o Slackware Linux é:
ftp://ftp.slackware.com/pub/slackware/
O ftp disponível no site, está aberto para uso geral, năo existe limite de banda. Mas por favor, considere a opçăo de utilizar um mirror mais próximo ŕ vocę para efetuar o download do Slackware. A lista completa dos mirros podem ser encontradas no site http://www.slackware.com/getslack.
Uma instalaçăo mínima do Slackware, necessita da seguinte configuraçăo:
| Hardware | Necessário |
| Processador | 586 |
| Memória | 32 MB RAM |
| Espaço em Disco | 1GB |
| Drive de CD | 4x CD-ROM |
Caso vocę tenha um CD bootável, vocę năo irá precisar de um disquete. É claro que se vocę năo possuir uma unidade de CD-ROM, vocę precisará de um disquete e uma unidade de disquete para fazer a instalaçăo via NFS através de uma rede. Além disso também é necessário uma placa de rede para esse tipo de instalaçăo. Para maiores informaçőes consulte a seçăo NFS.
O espaço em disco necessário, é um pouco complicado especificar. O espaço recomendado para uma instalaçăo mínima é de 1GB, mas caso vocę faça uma instalaçăo completa vocę irá precisar cerca de 2Gb de espaço em disco e mais um espaço para armazenar seus arquivos pessoais. A maioria dos usuários năo fazem a instalaçăo completa. O fato é que muitos usuários instalam o Slackware em um disco realmente pequeno com 100Mb de espaço.
O Slackware pode ser instalado em sistemas com pouca memória RAM, discos rígidos pequenos e CPUs com pouco poder de processamento, porém isso necesita de um pouco de trabalho. Se este for o seu caso, leia o arquivo LOWMEM.TXT localizado na árvore da distibuiçăo, para obter algumas dicas úteis.
Por razőes de simplicidade, os softwares (pacotes) que acompanham o Slackware săo divididos em séries. Essas séries săo chamadas de conjunto de discos devido terem sido planejadas para a instalaçăo do sistema através de disquetes, porém hoje essas séries săo usadas basicamente para categorizar os pacotes incluso no Slackware. Hoje năo é mais possível fazer a instalaçăo apenas com disquetes.
A seguir vocę encontra uma breve descriçăo de cada série de pacotes.
Série dos Pacotes
| Série | Conteúdo |
| A | Base do Sistema. Contęm uma grande parte dos softwares utilizados para se ter um sistema básico funcionando. Isso contęm um editor de textos e um programa simples de comunicaçăo. |
| AP | Diversos aplicativos que năo necessitam de um Servidor X. |
| D | Ferramentas de desenvolvimento de programas. Compiladores, debugadores, interpretadores e a grande parte das man pages. |
| E | GNU Emacs. |
| F | FAQs, HOWTOs e outros tipos de documentaçăo. |
| GNOME | O ambiente gráfico GNOME. |
| K | O código fonte do kernel do Linux. |
| KDE | O ambiente gráfico K. Um ambiente gráfico que possui muitas características visuais em comum com o MacOS e o Windows. A biblioteca Qt, requerida para este ambiente, também é encontrada nesta série. |
| KDEI | Pacotes de internacionalizaçăo para o ambiente KDE. |
| L | Bibliotecas. Bibliotecas dinâmicas lincadas necessárias para muitos outros programas. |
| N | Programas de Rede. Daemons, programas de e-mail, telnet, leitor de news e alguns outros. |
| T | Sistema de formataçăo de documentos teTeX. |
| TCL | Ferramenta de Linguagem de comando. Tk, TclX, e TkDesk. |
| X | Sistema base para o X Window. |
| XAP | Aplicaçőes gráficas que năo fazem parte de um ambiente de desktop principal (como por exemplo: Ghostscript e Netscape). |
| Y | Jogos de console BSD |
Disquete
Quando era possível, O Slackware Linux era instalado com apenas dois disquetes, porém o tamanho dos pacotes de alguns softwares cresceram (especificamente alguns softwares) entăo houve o abandono forçado da instalaçăo via disquete. Até a versăo 7.1, era possível fazer uma parte da instalaçăo utilizando disquetes. As séries A e N podiam ser totalmente instaladas, o que fornecia um sistema básico para instalar o restante da distribuiçăo. Caso vocę for utilizar um disquete para instalar (em um equipamento mais velho), é recomendável que vocę utilize uma versăo mais antiga. Para esse tipo de equipamento é recomendado as versőes 4.0 (a mais popular para isso) e a 7.0 do Slackware.
Observe que o disquete ainda é utilizado para realizar o boot, quando isso năo é possível através de uma unidade de CD-ROM, ou quando se utiliza a instalaçăo via NFS.
CD-ROM
Se vocę tiver um CD bootável, criado pela Slackware Linux, Inc. (veja a seçăo Obtendo o Slackware) a instalaçăo ficará mais fácil para vocę. Caso contrário, vocę poderá utilizar um disquete de boot. Caso, vocę tenha um hardware específico, um disco de boot específico poderá ser utilizado.
A partir da versăo 8.1, um novo método de criaçăo de CDs de BOOT foi adotado, que năo trabalha com algumas BIOS (esse problema é enfrentado por todas distribuiçőes Linux atualmente). Se este for o seu caso, recomendamos que vocę utilize um disquete.
Veja a seçăo 3.2.3 e a seçăo 3.2.5 fornecem informaçőes de como criar um disquete de boot, caso seja necessário.
NFS
NFS (Sistemas de Arquivos de Rede) é uma maneira de utilizar sistemas de arquivos em máquinas remotas. A instalaçăo via NFS permite que vocę instale o Slackware ŕ partir de uma outra máquina de sua rede. A máquina que vocę estiver utilizando para a instalaçăo precisa ser configurada de modo a exportar a árvore de distribuiçăo do Slackwware para a máquina que vocę está instalando. Isto, naturalmente, requer um certo conhecimento do NFS, que é coberto na seçăo Network File System (NFS)
Também é possível executar o NFS através de um método como o PLIP (sobre uma porta paralela), SLIP, e PPP (exceto sobre uma conexăo via modem). Entretanto, é recomendável que vocę utilize uma placa de rede. Apesar de tudo, instalar um sistema através de uma porta paralela é algo muito lento.
O disco de boot é um disquete utilizado para iniciar a instalaçăo. Ele contęm uma imagem compactada do Kernel que é utilizada para controlar o hardware durante a instalaçăo. Ao menos que vocę esteja utilizando um CD, este disco é necessário. Os discos de boot săo localizados no diretório bootdisks/ da árvore da distribuiçăo.
Existem diversos discos de boot que vocę pode utilizar (săo aproximadamente 16). A lista completa dos discos de boot e a descriçăo completa de cada um săo encontradas no arquivo bootdisks/README.TXT localizado na árvore da distribuiçăo. Entretanto, a maioria das pessoas utilizam a imagem bare.i (para dispositivos IDE ou scsi.s (para dispositivos SCSI) para o boot.
Veja a seçăo 3.2.3 - Disco de Boot para instruçőes de como fazer um disco de boot.
Após o boot, um prompt de comando solicitará que vocę insira o disco de root.
Os discos de root contęm o programa de instalaçăo e um sistema de arquivos que é utilizado durante a instalaçăo. Também săo necessários. As imagens do disco de root săo encontradas na árvore da distribuiçăo. Vocę terá que fazer dois discos de root, install.1 e install.2. Aqui, vocę também pode encontrar os discos network.dsk, pcmcia.dsk, rescue.dsk, e sbootmgr.dsk.
Um disco complementar é necessário caso vocę utilize uma instalaçăo via NFS ou se vocę tiver um cartăo PCMCIA. Os discos complementares săo encontrados no diretótio raíz da árvore de distribuiçăo, com os nomes network.dsk e pcmcia.dsk. Recentemente, outros discos complementares como rescue.dsk e sbootmgr.dsk foram adicionados. O disco de restauraçăo é uma imagem pequena que funciona com 4MB de RAM. Inclui alguns utilitários básicos de rede e o editor vi para reparos rápidos. O disco sbootmgr.dsk é utilizado para carregar outros dispositivos. Use este disco se o seu CD-ROM bootável năo quiser dar boot com os CDs do Slackware. Ele pedirá outras opçőes de boot e pode ser uma forma conveniente de contornar uma BIOS com bugs.
O disco de root irá instruí-lo a usar discos complementares quando ele for carregado.
Caso tenha escolhido uma imagem de boot, vocę necessita de um disquete. Dependendo do sistema que está usando para criar os discos, o processo será diferente. Se vocę estiver utilizando um Linux (ou um outro sistema Unix) vocę utilizará o comando dd(1). Suponhamos que vocę esteja usando a imagem bare.i e a sua unidade de disquete é o /dev/fd0, o comando que vocę deverá utilizar para criar um disquete com a imagem bare.i é:
$ dd if=bare.i of=/dev/fd0
Se estiver utilizando um sistema operacional Microsoft, vocę precisará do programa RAWRITE.EXE, que está incluso no mesmo diretório das imagens de disquete. Suponhamos que esteja usando a imagem bare.i e o seu dispositivo de disquete é a unidade A:, abra o prompt do DOS e digite:
C:\ rawrite a: bare.i
Após a inicializaçăo com a sua mídia preferida, será necessário particionar o seu disco rígido. A partiçăo do disco é onde o sistema de arquivos do Linux será criado e onde o Slackware será instalado. Recomendamos a criaçăo de, no mínimo, duas partiçőes; uma para o seu sistema de arquivos root (/) e uma para a área de troca (swap).
Quando terminar o carregamento do disco de root, aparecerá um prompt de login. Entre no sistema como root (sem senha). No prompt do shell, execute cfdisk(8) ou fdisk(8). O programa cfdisk possui uma interface mais amigável do que o programa fdisk, mas lhe faltam alguns recursos. Segue abaixo uma rápida explicaçăo do programa fdisk.
Comece executando o fdisk para o seu disco rígido. No Linux, em vez dos discos rígidos possuírem letras de drive, eles săo representados por um arquivo. O primeiro disco rígido IDE (primário master) é /dev/hda, o primário slave é /dev/hdb, e assim por diante. Discos SCSI seguem o mesmo sistema, mas no formato /dev/sdX. Inicie o fdisk informando o seu disco rígido:
# fdisk /dev/hda
Como em todos os bons programas para o Unix, o fdisk mostra um prompt (pensou que haveria um menu, năo foi?). A primeira coisa que vocę deve fazer é examinar o seu esquema de partiçőes atual. Faça isso digitando p** no prompt do fdisk:
Command (m for help): p
Serăo exibidos todos os tipos de informaçőes sobre o seu sistema de partiçőes atual. A maioria das pessoas seleciona uma unidade livre para a instalaçăo e entăo remove as partiçőes existentes para dar espaço para as partiçőes do Linux.
AVISO: É EXTREMAMENTE IMPORTANTE FAZER UMA CÓPIA DE SEGURANÇA (BACKUP) DE TODAS AS INFORMAÇŐES QUE VOCĘ QUEIRA MANTER, ANTES DE REMOVER A PARTIÇĂO ONDE ELAS ESTĂO ARMAZENADAS.
Năo existe uma forma fácil de recuperar dados de uma partiçăo removida, portanto sempre faça uma cópia de segurança (backup) antes de alterá-las.
Na tabela de informaçőes da partiçăo há um número da partiçăo, o tamanho, e o tipo. Há mais informaçőes, mas năo se preocupe com isso por enquanto. Removeremos todas as partiçőes deste drive para criar as do Linux. Digitamos d para removę-las:
Command (m for help): d Partition number (1-4): 1
Repita este processo para cada uma das partiçőes. Após removę-las, estaremos prontos para criar as do Linux. Decidimos criar uma partiçăo para o nosso sistema de arquivos root e uma para o swap. Observe que os esquemas de particionamento do Unix săo a causa de acaloradas discussőes, e que a maioria dos usuários lhe dirá qual a melhor forma. No mínimo, crie uma partiçăo para o / e uma para swap. Com o tempo, vocę desenvolverá uma metodologia que funcione bem para vocę.
Eu uso dois esquemas básicos de particionamento. O primeiro é para um desktop. Faço 4 partiçőes, /, /home, /usr/local, e swap. Assim posso re-instalar ou atualizar tudo que está instalado em / sem remover os meus arquivos de dados no /home ou os meus aplicativos personalizados compilados no /usr/local. Em servidores, geralmente substituo a partiçăo /usr/local por uma partiçăo /var. Muitos servidores diferentes armazenam informaçőes nesta partiçăo e mantę-la separada do / traz benefícios quanto ao desempenho. Por enquanto, vamos ficar com apenas estas duas partiçőes: / e swap.
Agora podemos criar as partiçőes com o comando n:
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4):1
First cylinder (0-1060, default 0):0
Last cylinder or +size or +sizeM or +sizeK (0-1060, default 1060):+64M
Assegure-se de ter criado partiçőes primárias. A primeira partiçăo será a nossa partiçăo swap. Diremos ao fdisk para tornar a partiçăo número 1 uma partiçăo primária. Ela começará no cilindro 0 e, para o cilindro final, digitamos +64M. Isto criará uma partiçăo de 64 megabytes para swap. (Na verdade, o tamanho da partiçăo de swap depende da quantidade de RAM do seu sistema. Por convençăo se usa uma partiçăo de swap com o dobro do tamanho da RAM do seu sistema.) Entăo, definimos a partiçăo primária número 2 começando no primeiro cilindro disponível e indo até o final do drive.
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4):2
First cylinder (124-1060, default 124):124
Last cylinder or +size or +sizeM or +sizeK (124-1060, default 1060):1060
Está quase pronto. Precisamos alterar o tipo da primeira partiçăo para tipo 82 (Linux swap). Digite t para alterar o tipo, selecione a primeira partiçăo, e digite 82. Antes de gravar as suas alteraçőes em disco, dę uma última olhada na nova tabela de partiçőes. Use o p no fdisk para exibir a tabela de partiçőes. Se tudo parecer estar bem, digite w para salvar as suas alteraçőes e sair do fdisk.
Uma vez criada as partiçőes, vocę está pronto para instalar o Slackware. O próximo passo da instalaçăo é executar o programa setup. Para executá-lo simplesmente digite setup no prompt. O setup possui um sistema de menu na qual permite que vocę instale os pacotes do Slackware e configure seu sistema.
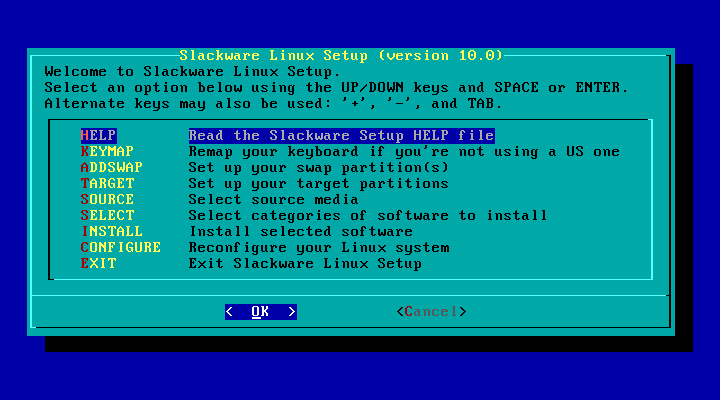
O processo de instalaçăo é algo do tipo: Selecione as opçőes de acordo como elas săo listadas no programa setup. (É claro que vocę pode mudar a ordem de escolha das opçőes, năo seguindo passo-a-passo o programa.) Os itens do menu săo selecionados usando as teclas seta para cima e seta para baixo, e os botőes Okay e Cancel săo usados para proseguir ou para voltar. Como alternativa, vocę pode escolher a opçăo desejada, teclando a letra correspondente destacada do menu para cada opçăo. Para selecionar as opçőes (estas săo indicadas com [X]) utiliza-se a barra de espaço.
É claro que vocę pode ver mais descriçőes na seçăo help do setup, porém acreditamos que o seu tempo vale dinheiro.
Caso seja a primeira vez que vocę esteja instalando o Slackware, vocę pode dar uma olhada na tela de ajuda. Assim terá uma descriçăo de cada parte do programa setup (assim como estamos descrevendo) e instruçőes para navegaçăo e para o restante da instalaçăo.

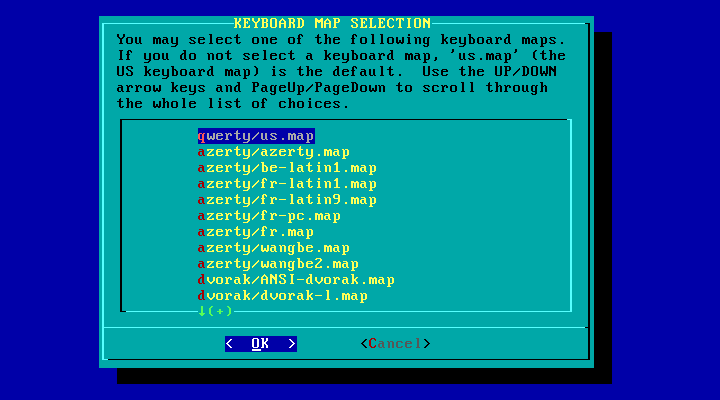
Caso necessite de um teclado diferente do padrăo americano qwerty, vocę deverá alterá-lo nessa seçăo. Existe uma grande quantidade de modelos de teclado que poderá escolher.

Caso vocę tenha criado uma partiçăo de swap (voltar ŕ seçăo 3.3), é aqui que vocę deverá habilitá-la para utilizar. As partiçőes de swap existentes em seu disco serăo exibidas automaticamente, permitindo que vocę selecione, pelo menos uma, para formatar e habilitar.
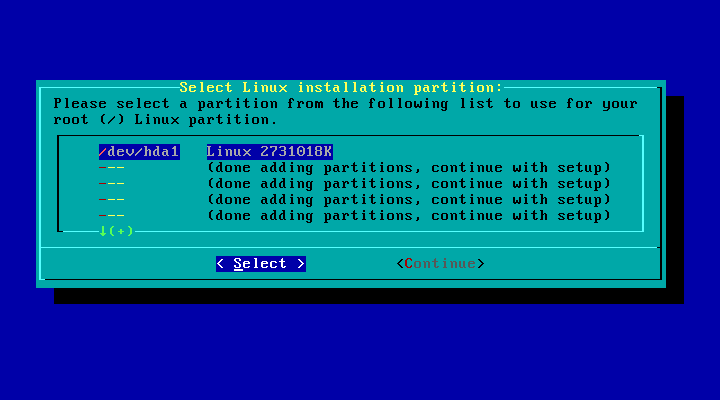
Na seçăo target vocę formatará suas partiçőes e mapeará os pontos de montagens dos sistemas de arquivos. Uma lista com as partiçőes de seu disco rígido săo mostradas. Para cada partiçăo, poderá escolher formatar ou năo. Dependendo do kernel utilizado, vocę poderá escolher os seguintes sistemas de arquivos reiserfs (padrăo), ext3, ext2, jfs e xfs. A maioria das pessoas utilizam reiserfs ou ext3. Em um futuro próximo nós poderemos ter o suporte ŕ reiserfs4.
A partiçăo a ser selecionada é onde o sistera root (/)deverá ser instalado. Após isso, vocę poderá escolher e mapear cada partiçăo para cada sistema de arquivos de acrodo com a sua escolha. (Por exemplo, vocę pode querer que a sua terceira partiçăo /dev/hda3, seja o sistemas de arquivos para o home. Isto é apenas um exemplo; crie os pontos de montagens de acordo com o seu gosto.)
A seçăo Source é onde selecionamos a mídia a partir da qual o Slackware será instalado. Atualmente, há quatro opçőes disponíveis. Săo elas: CD-ROM, uma partiçăo no disco rígido, NFS, ou um diretório pré-montado.
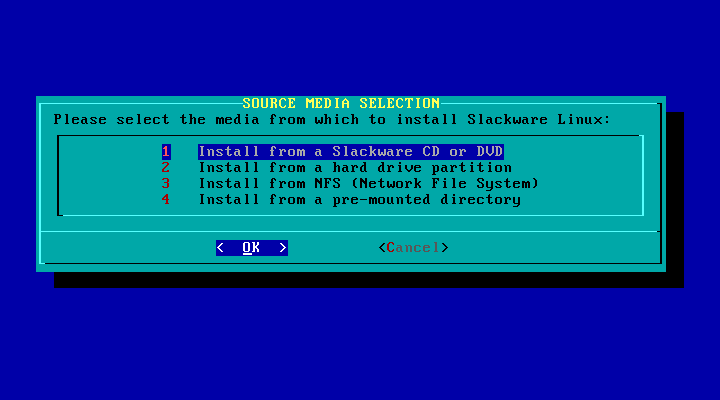
A opçăo CD-ROM permite a instalaçăo a partir de um CD-ROM. Há a opçăo de procurar automaticamente um drive de CD-ROM ou exibir uma lista da qual pode-se escolher o tipo do drive. Assegure-se de ter o CD do Slackware no seu drive antes de começar a busca.
A opçăo NFS pede informaçőes da sua rede e de seu servidor NFS. O servidor NFS já deve estar configurado. Note também que năo é possível usar nomes de máquina (hostnames), deve-se usar endereços IP tanto para a sua máquina, quanto para o servidor NFS (năo há um serviço de resoluçăo de nomes no disco de instalaçăo). Naturalmente, deve ser usado o disquete network.dsk para dar suporte para a sua placa de rede.
O diretório pré-montado oferece maior flexibilidade. Use este método para instalar a partir de dispositivos como Jaz disks, pontos de montagem NFS sobre PLIP, e sistemas de arquivos FAT. Monte o sistema de arquivos em um local de sua escolha antes de executar a instalaçăo, e entăo especifique esse local aqui.
A seçăo Select permite escolher as séries de software que desejamos instalar. Essas séries săo descritas na seçăo 3.2.1. Note que é obrigatória a instalaçăo da série A para ter um sistema base funcional. Todas as outras séries săo opcionais.
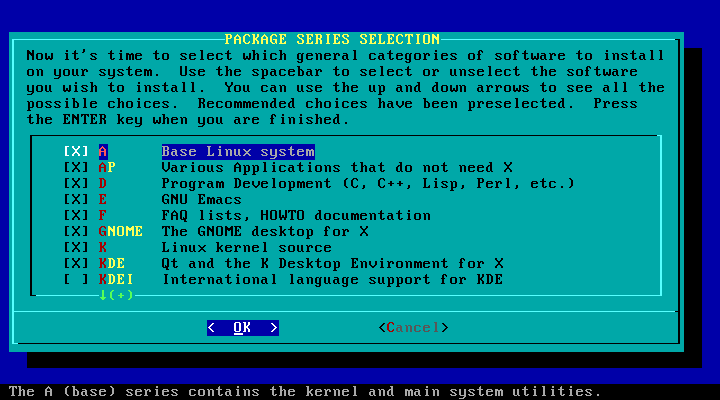
Considerando que tenhamos passado pelas seçőes "target", "source", and "select", a seçăo install permite selecionar pacotes dentre as séries de software escolhidas. Se năo, pedirá que vocę volte e complete as outras seçőes do programa de instalaçăo. Esta seçăo permite escolher dentre seis diferentes métodos de instalaçăo: //full, newbie, menu, expert, custom, e tag path.

A opçăo full (completo) instala todos os pacotes das séries escolhidas na seçăo select. Năo há mais perguntas. Este é o método de instalaçăo mais fácil, já que năo é necessário tomar quaisquer decisőes quanto aos pacotes a instalar de fato. É claro que esta opçăo também é a que ocupa maior espaço no disco rígido.
A próxima opçăo é newbie (novato). Esta opçăo instala todos os pacotes requeridos pelas séries selecionadas. Em todos os outros pacotes há um prompt onde podemos selecionar Yes (sim), No (năo), ou Skip (pular). Yes e No fazem o óbvio, enquanto Skip pula para a próxima série de software. Além disso, é exibida uma descriçăo e o tamanho de cada pacote para ajudar a decidir se o mesmo é necessário. Recomendamos esta opçăo para os novos usuários, já que ela assegura que os pacotes desejados sejam instalados. Contudo, ela é um pouco mais lenta devido ŕs perguntas.
Menu é uma versăo mais rápida e mais avançada da opçăo newbie. Em cada série, aparece um menu, a partir do qual pode-se selecionar todos os pacotes năo requeridos que se deseja instalar. Os pacotes requeridos năo aparecem nesse menu.
Para os usuários mais avançados, a instalaçăo oferece a opçăo expert. Isto permite total controle sobre quais pacotes săo instalados. É possível remover da seleçăo pacotes que săo absolutamente necessários, o que resulta em um sistema entrar em colapso. Por outro lado, é possível controlar exatamente o que entra em seu sistema. Simplesmente selecione os pacotes de cada série que deseja que sejam instalados. Isto năo é recomendado para os novos usuários, já que é muito fácil dar um tiro no próprio pé.
As opçőes custom e tag path também săo para usuários avançados. Estas opçőes permitem a instalaçăo com base em tag files personalizados criados na árvore da distribuiçăo. Isto é útil para se instalar um grande número de máquinas rapidamente. Para maiores informaçőes sobre o uso de tag files, veja a seçăo 18.4.
Após escolher o seu método de instalaçăo, uma coisa ou outra abaixo vai acontecer. Se tiver selecionado full ou menu, uma tela com um menu aparecerá, permitindo a seleçăo dos pacotes a ser instalados. Se tiver selecionado full, os pacotes começarăo a ser instalados no destino imediatamente. Se tiver selecionado newbie, os pacotes serăo instalados até que se alcance um pacote opcional. Observe que é possível que o espaço em disco acabe durante a instalaçăo. Se selecionar pacotes demais para a quantidade de espaço livre no dispositivo alvo, vocę terá problemas. É mais seguro selecionar alguns programas e adicionar mais depois, se necessário. Isto pode ser feito facilmente usando as ferramentas de gerenciamento de pacotes do Slackware. Para maiores informaçőes, veja a seçăo 18.
A seçăo configure permite fazer algumas configuraçőes básicas do sistema, agora que os pacotes já foram instalados. O que vocę vę depende em grande parte de que programas foram instalados. Contudo, sempre será exibido o conteúdo abaixo:
Aqui vocę deverá escolher um kernel para ser instalado. Vocę pode instalar o kernel do disco de boot usado na instalaçăo, do CD-ROM do Slackware, ou de outro disquete que vocę (sempre se antecipando) tiver preparado. Ou vocę pode decidir pular, sendo que entăo o kernel padrăo será instalado e o processo continuará.

Provavelmente será uma boa idéia fazer um disco de boot para usar no futuro. Vocę terá a opçăo de formatar um disquete e, entăo, criar um dos dois tipos de disco de boot. O primeiro tipo, simple (simples), simplesmente (como é de se esperar) grava um kernel no disquete. Uma opçăo mais flexível (e altamente recomendada) é lilo, que, é claro, cria um disco de boot do lilo. Veja LILO na seçăo 7.1 para maiores informaçőes. É claro, vocę também pode decidir simplesmente continuar, de modo que năo será criado um disco de boot.

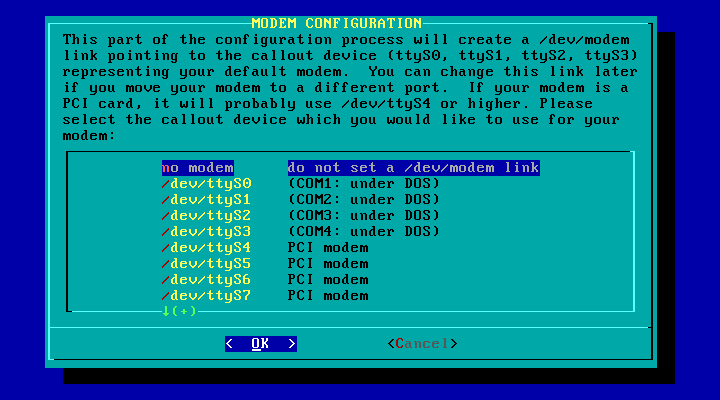
Serăo solicitadas informaçőes sobre o seu modem. Mais especificamente, se vocę possui um modem, e, se possuir, em qual porta serial ele está.
As próximas sub-seçőes de configuraçăo podem aparecer ou năo, dependendo se os seus pacotes correspondentes tiverem sido instalados.
Aqui é bem direto: será perguntado em qual fuso horário vocę está. Se estiver no horário Zulu, sentimos muito; a lista (extremamente longa) está em ordem alfabética, e vocę está no final dela.

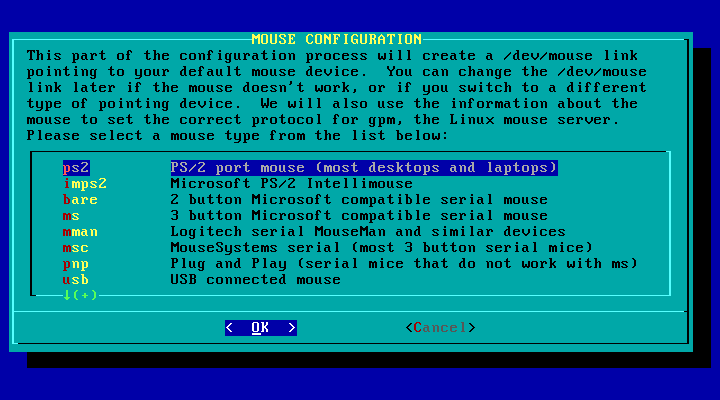
Esta sub-seçăo simplesmente pergunta que tipo de mouse vocę tem, e se vocę quer ter suporte ao mouse no console com o gpm(8) habilitado na inicializaçăo.
Esta sub-seçăo pergunta se o relógio de hardware do seu computador está ajustado no Tempo Universal Coordenado (UTC ou GMT). A maioria dos PCs năo estăo, entăo provavelmente vocę deve dizer "no" (năo).
A sub-seçăo font permite que se escolha dentre de uma lista de fontes personalizadas para o console.
Aqui é perguntado sobre a instalaçăo do LILO (o LInux LOader; veja a seçăo 7.1 para maiores informaçőes).
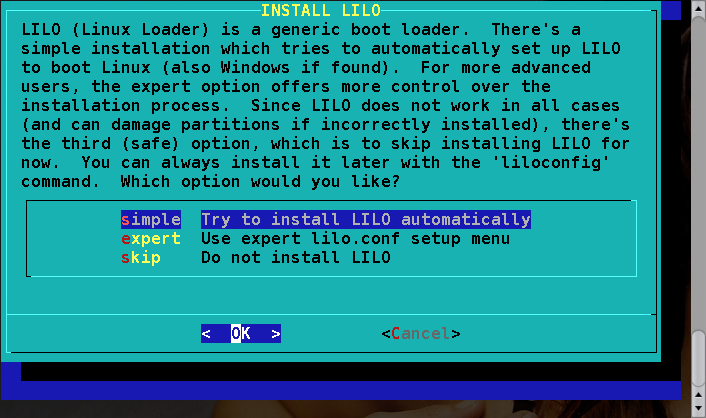
Se o Slackware for o único sistema operacional em seu computador, a opçăo simple (simples) deve funcionar perfeitamente. Se houver dual-boot, a opçăo expert é uma melhor escolha. Veja a seçăo 7.5 para maiores informaçőes sobre dual-boot. A terceira opçăo, do not install (năo instalar), năo é recomendada, a năo ser que vocę saiba o que está fazendo e que tenha uma ótima razăo para năo instalar o LILO. Se o modo de instalaçăo for "expert", vocę poderá escolher onde o LILO será instalado. O LILO pode ficar na MBR (Master Boot Record) do seu disco rígido, no superbloco da sua partiçăo raíz do Linux, ou em um disquete.
Na verdade, a sub-seçăo de configuraçăo network é o netconfig. Veja a seçăo 5.1 para maiores informaçőes.
Esta sub-seçăo permite a escolha de um gerenciador de janelas padrăo para o X. Veja seçăo 5.1 para maiores detalhes sobre o X e gerenciadores de janelas.

Năo importa quais pacotes tenham sido instalados, a última coisa que será feita na seçăo configure será perguntar se vocę quer continuar e criar uma senha para o root . Por razőes de segurança, provavelmente está será uma boa idéia; todavia, como tudo mais no Slackware, vocę decide.
Antes de vocę poder configurar as partes mais avançadas do seu sistema, é uma boa idéia entender como o sistema é organizado e que comandos podem ser utilizados para procurar por arquivos e programas. É bom saber também, se vocę precisará compilar um kernel otimizado e quais os passos que deverăo ser seguidos. Este capítulo irá familiarizá-lo com a organizaçăo do sistema e a configuraçăo de arquivos. Assim, vocę poderá avançar na configuraçăo das partes mais avançadas do sistema.
É importante entender como um sistema Linux é montado antes de mergulhar nos vários aspectos de sua configuraçăo. Um sistema Linux é significativamente diferente de um sistema DOS, Windows ou de um sistema Macintosh (com a exceçăo do Mac OS X que é baseado no Unix), mas estas seçőes o ajudarăo a ficar familiarizado com o seu layout, de modo que vocę facilmente poderá configurar seu sistema para as suas necessidades.
A primeira diferença marcante entre o Slackware Linux e um sistema DOS ou Windows é o sistema de arquivos. Logo de início, năo săo utilizados letras para os drivers, para identificar as diferentes partiçőes. Sob o Linux, existe apenas um único diretório principal. Vocę pode relacionar isto com o drive C: do ambiente DOS. Cada partiçăo em seu sistema é montado como um diretório dentro do diretório principal. É como se vocę tivesse um disco rígido expansível.
Chamamos o diretório principal de diretório root (ou raíz), e o mesmo é representado por uma barra (/). Este conceito pode soar estranho, mas isso torna sua vida mais fácil quando vocę quer adicionar mais espaço. Por exemplo, vamos dizer que vocę ficou sem espaço em disco no diretório /home. Muitas pessoas ao instalarem o Slackware criam uma única partiçăo raiz. Bem, como uma partiçăo pode ser montada para qualquer diretório, vocę só precisa ir até a loja mais próxima e comprar um disco rígido novo e montá-lo como /home. Vocę agora colocou mais espaço em seu sistema. E tudo sem precisar mover nada de lugar.
Abaixo, vocę irá encontrar as descriçőes dos diretórios mais importantes sob o Slackware.
bin - Programas essenciais para os usuários săo armazenados aqui. Isso representa um conjunto mínimo de programas requeridos pelo usuário para a utilizaçăo do sistema. Coisas como o shell e os comandos do sistema de arquivos (ls, cp, e assim por diante) săo armazenados aqui. O diretório /bin também năo recebe modificaçăo após a instalaçăo. Se isso acontecer, é na forma de atualizaçăo de pacotes que fornecemos.
boot - Arquivos que săo utilizados pelo Linux Loader (LILO). Esse diretório também recebe pequenas modificaçőes após a instalaçăo. O kernel é armazenado aqui desde a versăo 8.1 do Slackware. Em versőes anteriores do Slackware, o kernel era simplesmente armazenado sob o diretório / , porém a prática comum é montar o kernel e os arquivos relacionados aqui, para facilitar o dual-booting (ou boot duplo).
dev - Tudo no Linux é tratado como arquivo, inclusive dispositivos de hardware como as portas seriais, discos rígidos, e scanners. Em ordem de acessar esses dispositivos, um arquivo especial chamado de dispositivo de conexăo tem de estar presente. Todos os dispositivos de conexăo săo armazenados no diretório /dev. Vocę vai descobrir que isso é verdade através dos muitos sistemas operacionais baseados em Unix.
etc - Esse diretório mantém os arquivos de configuraçăo do sistema. Todos os arquivos de configuraçăo do X Window, o banco de dados do usuário, até o sistema de inicializaçăo de scripts. Com o tempo, o administrador do sistema ficará bastante familizado com este diretório.
home - O Linux é um sistema operacional multi-usuário. A cada usuário no sistema é dado uma conta e um diretório único para seus arquivos pessoais. Este diretório é chamado de diretório raíz do usuário. O diretório /home é fornecido como localizaçăo padrăo para os diretórios raíz do usuário.
lib - As bibliotecas do sistema que săo necessárias para operaçőes básicas do sistema săo armazenadas aqui. A biblioteca C, o carregador dinâmico, as bibliotecas ncurses e os módulos do kernel estăo entre as coisas aqui armazenadas.
mnt - Este diretório contém pontos de montagem temporários para discos rígidos em operaçăo ou drives removíveis. Aqui vocę encontrará os pontos de montagem para o seus drives de CD-ROM e de disquete.
opt - Pacotes de software opcionais. A idéia por trás do diretório /opt é que cada pacote de software instalado no diretório /opt/pacote de software, que seja fácil de remover depois. O Slackware distribui algumas coisas no diretório /opt (como o KDE em /opt/kde), porém vocę é livre para adicionar qualquer coisa que queira ao diretório /opt.
proc - Este é um diretório único. Ele năo é realmente parte do sistema de arquivos, mas sim um sistema de arquivos virtual que provę acesso as informaçőes do kernel. Vários pedaços de informaçăo que o kernel quer que vocę conheça săo transportados a vocę através de arquivos no diretório /proc. Vocę pode enviar informaçăo para o kernel através desses mesmos arquivos. Tente o comando cat /proc/cpuinfo.
root - O administrador do sistema é conhecido como root no sistema. O diretório raíz do usuário root é mantido em /root em vez de /home/root. A razăo é simples. O que acontece se o diretório /home estiver em uma partiçăo diferente do diretório / e năo puder ser montado? O usuário //root irá querer logar e repara o problema. Se o seu diretório de usuário raíz estiver no sistema de arquivos danificado, será meio difícil para ele conseguir logar-se.
sbin - Programas essenciais que săo rodados pelo usuário root e durante o processo de boot do sistema săo mantidos aqui. Usuários normais năo irăo rodar programas neste diretório.
tmp - Local de armazenagem temporária. Todos os usuários possuem acesso de leitura e escrita neste diretório.
usr - Este é o maior diretório em um sistema Linux. Tudo o mais vem aqui, programas, documentaçăo, o código-fonte do kernel, e o sistema X Window. Este é o diretório que vocę mais irá gostar de estar instalando programas.
var - Arquivos de log do sistema, informaçőes de cache, e arquivos protegidos de programas săo armazenados aqui. Este é o diretório para mudanças freqüentes de informaçăo.
Vocę agora deve ter uma boa noçăo para quais diretórios contém o que no sistema de arquivos. Informaçőes mais detalhadas sobre o layout do sistema de arquivos estăo disponíveis nas páginas de manual do hier(7). A próxima seçăo irá ajudá-lo a encontrar arquivos específicos com facilidade, entăo vocę năo precisará fazer isso de forma braçal.
Agora vocę sabe o que cada diretório principal contém, mas isso realmente năo ajuda em nada a encontrar coisas. Eu creio que vocę poderia ir olhando através dos diretórios, porém existem maneiras rápidas de fazer isso. Existem quatro comandos principais de busca de arquivos disponíveis no Slackware.
which
O primeiro é o comando which(1). O comando which é geralmente usado para achar de forma rápida a localizaçăo de um programa. Ele apenas procura seu PATH e retorna a primeira instância encontrada e o caminho do diretório do mesmo. Pegue este exemplo:
$ which bash
/bin/bash
Pelo que vocę já viu do bash ele está no diretório /bin. Este é um comando de busca muito limitado, já que o mesmo só procura pelo PATH.
whereis
O comando whereis(1) trabalha de forma similar ao comando which, mas pode também procurar por páginas de manual e arquivos fontes. Um comando whereis para procurar pelo programa bash iria retornar:
$ whereis bash
bash: /bin/bash /usr/bin/bash /usr/man/man1/bash.1.gz
Este comando năo apenas nos diz onde atualmente o programa está localizado, mas também onde a sua documentaçăo online está armazenada. Ainda assim, este comando é limitado. O que aconteceria se vocę precisasse procurar por um arquivo de configuraçăo específico? Vocę năo poderia utilizar o comando which ou o whereis para isso.
find
O comando find(1) permite ao usuário procurar o sistema de arquivos com um rico arsenal de opçőes de busca. Usuários poderiam especificar uma busca com espressőes regulares no nome do arquivo, alcance de modificaçőes ou tempo de criaçăo, ou outra propriedade avançada. Por exemplo, para procurar pelo arquivo xinitrc padrăo em um sistema, o comando a seguir poderia ser utilizado.
$ find / -name xinitrc
/var/X11R6/lib/xinit/xinitrc
O comando find irá demorar um pouco no processo, desde que ele vai varrer tudo na árvore de diretórios raíz. E se este comando estiver rodando por um usuário normal, irăo aparecer várias mensagens erro de permissăo negada para os diretórios em que apenas o usuário root pode ver. Porém se o comando find encontra qualquer arquivo, isto é bom. Se ele pudesse ser pelo menos um pouco mais rápido...
slocate
O comando slocate(1) procura no sistema de arquivos inteiro, assim como o comando find pode fazer, porém ele procura em um banco de dados em vez do atual sistema de arquivos. O banco de dados está programado para ser atualizado toda manhă, entăo vocę terá de algum modo uma lista atualizada dos arquivos de seu sistema. Vocę pode rodar manualmente o comando updatedb(1) para atualizar o banco de dados slocate (antes de rodar na măo o comando updatedb, vocę precisa primeiro rodar o comando su para virar o usuário root). Aqui está um exemplo do comando slocate em açăo:
$ slocate xinitrc # we don't have to go to the root
/var/X11R6/lib/xinit/xinitrc
/var/X11R6/lib/xinit/xinitrc.fvwm2
/var/X11R6/lib/xinit/xinitrc.openwin
/var/X11R6/lib/xinit/xinitrc.twm
Nós conseguimos mais do que estávamos procurando, e de forma rápida também. Com esses comandos, vocę será capaz de encontrar qualquer coisa que estiver procurando em seu sistema Linux.
Os arquivos de inicializaçăo do sistema săo armazenados no diretório /etc/rc.d. O Slackware utiliza o layout estilo BSD para estes arquivos de inicializaçăo ao contrário dos scripts de inicializaçăo do System V, a qual tende a tornar as mudanças na configuraçăo mais difíceis sem estar utilizando um programa especificamente desenhado para esta funçăo. Nos scripts de inicializaçăo do BSD, cada runlevel é um arquivo rc simples. No System V, cada runlevel é dado a seu próprio diretório, a qual contém inúmeros scripts de inicializaçăo. Isto provę uma estrutura organizada que é fácil de manter.
Existem várias categorias de arquivos de inicializaçăo. Estes săo o sistema de inicializaçăo, runlevel, inicializaçăo de rede, e a compatibilidade com o System V. Pela tradiçăo, nós iremos amontoar todas as outras coisas em uma nova categoria.
Inicializaçăo do Sistema
O primeiro programa a rodar sobre o Slackware, além do kernel Linux, é o init(8). Este programa lę o arquivo /etc/inittab(5) para ver como carrega o sistema. Ele roda o script /etc/rc.d/rc.S para preparar o sistema antes de ir para o nível de execuçăo desejado. O arquivo rc.S habilita sua memória virtual, monta seu sistema de arquivos, limpa certos diretórios de log, inicializa os dispositivos Plug and Play, carrega os módulos do kernel, configura os dispositivos PCMCIA, ativa as portas seriais, e os scripts de inicializaçăo do System V (se encontrado). Obviamente o rc.S possui muitos recursos, mas existe alguns scripts no diretório /etc/rc.d que o rc.S irá chamar para completar seu trabalho:
rc.S - Este é o atual script do sistema de inicializaçăo.
rc.modules - Carrega os módulos do kernel. Coisas como sua placa de rede, suporte a PPP, e outras coisas săo carregadas aqui. Se este script acha o rc.netdevice, correrá tudo bem.
rc.pcmcia - Investiga e configura qualquer dispositivo PCMCIA que vocę possa ter em seu sistema. Isto é bem útil para usuários de laptops, que provavelmente possuem um modem ou rede PCMCIA.
rc.serial - Configura suas portas seriais rodando os comandos apropriados do setserial.
rc.sysvinit - Procura pelos scripts de inicializaçăo do System V para o runlevel desejado e os inicializa. Este assunto é discutido em maiores detalhes abaixo.
Scripts de inicializaçăo do Runlevel
Após o sistema de inicializaçăo estar completo, o comando init vai para a inicializaçăo do runlevel. Um runlevel descreve o nível em que a sua máquina irá rodar. Isso soa redundante? Bem, o runlevel comunica ao init se vocę estará aceitando logins de multi-usuários ou apenas de um único usuário, independente se vocę vai utilizar os serviços de rede ou năo, e se vocę estará utilizando o X Window System ou o comando agetty(8) para manipular os logins. Os arquivos abaixo definem os diferentes runlevels no Slackware Linux.
rc.0 - Desliga o sistema (runlevel 0). Por padrăo, este runlevel está linkado ao rc.6.
rc.4 - Inicializaçăo multi-usuário (runlevel 4), porém no X11 com o KDM, GDM, ou XDM como o gerenciador de login.
rc.6 - Reinicializa o sistema (runlevel 6).
rc.K - Inicializa o sistema em modo mono-usuário (runlevel 1).
rc.M - Modo multi-usuário (runlevels 2 e 3), porém com o login em modo texto padrăo. Este é o runlevel padrăo no Slackware.
Inicializaçăo de rede
Os Runlevels 2, 3, e 4 irăo inicializar os serviços de rede. Os seguintes arquivos săo responsáveis pela inicializaçăo do sistema:
rc.inet1 - Criado pelo netconfig, este arquivo é responsável pela configuraçăo da atual interface de rede.
rc.inet2 - Roda depois do rc.inet1 e inicializa os serviços de rede básicos.
rc.atalk - Inicializa os serviços AppleTalk.
rc.httpd - Inicializa o servidor Apache. Como alguns outros scripts, este pode ser utilizado para parar e reiniciar um serviço. O rc.httpd toma argumentos de parada, inicio, ou reinicio.
rc.news - Inicializa o servidor de news.
Compatibilidade com System V
A compatibilidade com o System V init foi introduzida no Slackware 7.0. Muitas outras distribuiçőes Linux fazem uso deste estilo, em vez do estilo BSD. Basicamente a cada runlevel é dado um sub-diretório para os scripts do init, do contrário do estilo BSD que dá um script de inicializaçăo para cada runlevel.
O script rc.sysvinit irá procurar por todos os scripts de inicializaçăo do System V que vocę tenha em /etc/rc.d e inicializá-los, se o runlevel for apropriado. Isto é útil para certos pacotes de software que instalam os scripts de inicializaçăo no System V.
Outros Arquivos
Os scripts descritos abaixo săo os outros scripts de inicializaçăo do sistema. Eles săo rodados tipicamente de um dos principais scripts descritos acima, entăo tudo de que vocę precisa fazer é editar seus conteúdos.
rc.gpm - Inicializa os serviços de habilitaçăo do mouse. Permite que vocę possa copiar e colar no console do Linux. Ocasionalmente, o gpm irá causar problemas para o mouse quando for usado sobre o X Windows. Se vocę tiver problemas com o uso do mouse no X, tente tirar a permissăo de execuçăo deste arquivo parando o servidor gpm.
rc.font - Carrega as fontes customizáveis para o console.
rc.local - Contém todos os comandos específicos de inicializaçăo do seu sistema. Ele fica vazio depois de uma instalaçăo limpa, esta reservado para administradores locais. Este script é inicializado após todas as outras inicializaçőes terem sido realizadas.
Para habilitar um script, tudo que vocę precisa fazer é adicionar permissőes de execuçăo a ele com o comando chmod. Para desabilitar um script, remova a permissăo de execuçăo do mesmo. Para maiores informaçőes sobre o comando chmod, veja a seçăo 9.2.
O kernel é a parte do sistema operacional que provę acesso ao hardware, controle de processos, e todo o sistema de controle. O kernel contém suporte para seus dispositivos de hardware, entăo escolher um kernel para o seu sistema é um passo muito importante.
O Slackware provę mais de uma dúzia de kernels pré-compilados que vocę poderá utilizar, cada qual com um conjunto padrăo de drivers genéricos e alguns drivers específicos. Vocę pode rodar um dos kernels pré-compilados ou pode construir seu próprio kernel a partir do código-fonte. Seja qualquer uma das opçőes que for escolhida, vocę precisará ter certeza que o seu kernel tenha o suporte ao hardware que vocę possui.
Os kernels pré-compilados estăo disponíveis no diretório /kernels no CD-ROM do Slackware ou no site de FTP no diretório principal do Slackware. Os kernels disponíveis mudam sempre que novas versőes săo lançadas, entăo a documentaçăo em cada diretório é o código-fonte do mesmo. O diretório /kernels possui sub-diretórios para cada kernel disponibilizado. Os sub-diretórios possuem o mesmo nome que o seu disco de boot que o acompanha. Em cada sub-diretório vocę irá encontrar os seguintes arquivos:
| Arquivo | Propósito |
| System.map | O arquivo de mapas do sistema para este kernel |
| bzImage | A imagem do kernel atual |
| config | O arquivo-fonte de configuraçăo para este kernel |
Para utilizar um kernel, copie os arquivos System.map e config para o seu diretório /boot e copie a imagem do kernel para /boot/vmlinuz. Rode o /sbin/lilo(8) para instalar o LILO para este novo kernel, e entăo reinicie seu sistema. Isso é tudo que há para instalar um novo kernel.
Os kernels que terminam com um .i săo kernels IDE. Sendo assim, eles năo incluem suporte a SCSI na base do seu kernel. Os kernels que terminam com .s săo kernels com suporte a SCSI. Eles incluem todo o suporte a IDE, como nos kernels terminados em .i, além de terem o suporte a SCSI.
A questăo "Devo compilar um kernel para meu sistema?" é sempre questionado por usuários novatos. A resposta é sempre talvez. Existem poucas ocasiőes onde vocę irá precisar compilar um kernel específico para o seu sistema. A maioria dos usuários pode utilizar um kernel pré-compilado e seus módulos carregáveis para terem um sistema totalmente funcional. Vocę irá querer compilar um kernel para o seu sistema apenas se vocę precisar fazer um upgrade de seu atual kernel para um que năo esteja atualmente disponibilizado para o slcakware, ou se vocę estiver adicionando novas funcionalidades ao seu kernel para dar suporte a um hardware específico, que năo esteja presente no código nativo no código-fonte do seu kernel. Qualquer um com um sistema SMP definitivamente irá querer compilar um kernal com suporte a SMP. Também, muitos usuários acham que um kernel customizado rodará. Vocę achará útil compilar o kernel com otimizaçőes para o processador específico de sua máquina.
Construir seu próprio kernel năo é tăo difícil assim. O primeiro passo é ter certeza que vocę tem o código-fonte do kernel instalado no seu sistema. Tenha certeza de ter instalado os pacotes da série K durante o processo de instalaçăo do seu Slackware. Vocę irá querer ter certeza que possui a série D instalada, especificamente o compilador C, o GNU make, e o GNU binutils. Em geral, é uma boa idéia ter a série D inteira instalada se vocę planeja fazer qualquer tipo de desenvolvimento. Vocę também pode baixar a última versăo do código-fonte do kernel disponível em http://www.kernel.org/mirrors.
Compilaçăo do Kernel Linux versăo 2.4.x
$ su -
Password:
# cd /usr/src/linux
A primeira etapa é trazer o código-fonte do kernel ao seu estado de base. Nós emitimos este comando para fazer isso (nota, acredito que vocę vá querer fazer um backup do arquivo .config já que esse comando irá apagar ele sem nenhum aviso):
# make mrproper
Agora vocę pode configurar o kernel para o seu sistema. O kernel atual oferece 3 maneiras de fazer isso. A primeira é o original sistema de perguntas-e-respostas em modo texto. Este fará diversas perguntas e, baseado nas suas respostas, irá construir um arquivo de configuraçăo. O problema deste método é se vocę errar algo, terá de recomeçar tudo do início. O método que a maior parte dos usuários preferem é o de sistema de menu. Por último, existe uma ferramenta de configuraçăo gráfica do kernel. Escolha uma de sua preferęncia e digite o comando apropriado:
# make config (baseado em texto, versăo P&R (Perguntas e Respostas))
# make menuconfig (menu dirigido, versăo baseado em texto)
# make xconfig (versăo baseado em X, certifique-se que vocę está primeiramente no X)
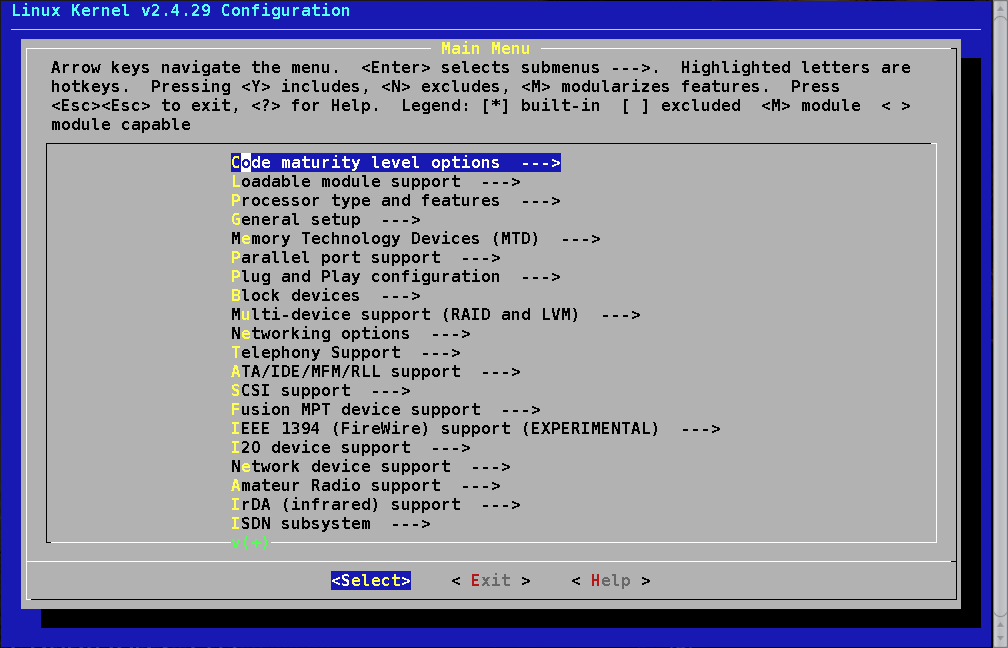
menu de configuraçăo do kernel
Os usuários novatos provavelmente irăo achar o comando menuconfig mais fácil de usar. As telas de ajuda provęm explicaçőes de várias partes do kernel. Após configurar seu kernel, saia do programa de configuraçăo. Ele irá escrever os arquivos de configuraçăo necessários. Agora nós podemos preparar a árvore do código-fonte do kernel para uma construçăo:
# make dep
# make clean
A próxima etapa é compilar o kernel. Primeiro tente emitir o comando bzImage abaixo.
# make bzImage
Isso pode demorar um pouco, dependendo da velocidade de sua CPU. Durante o processo de construçăo, vocę poderá ver as mensagens geradas pela compilaçăo. Após construir a imagem do kernel, vocę irá querer construir todas as partes do kernel que vocę marcou para serem modulares.
# make modules
Vocę agora pode instalar o kernel e seus módulos que compilou. Para instalar o kernel em um sistema Slackware, os comandos abaixo devem ser digitados:
# mv /boot/vmlinuz /boot/vmlinuz.old
# cat arch/i386/boot/bzImage > /vmlinuz
# mv /boot/System.map /boot/System.map.old
# cp System.map /boot/System.map
# make modules_install
Vocę irá querer editar o arquivo /etc/lilo.conf e adicionar uma seçăo para a inicializaçăo de seu kernel antigo em caso do novo kernel năo funcionar. Após ter feito isso, execute o comando /sbin/lilo para instalar o novo bloco de inicializaçăo. Vocę agora já pode reiniciar com o seu novo kernel.
Kernel Linux Versăo 2.6.x
A compilaçăo do kernel 2.6 kernel é levemente diferente do kernel 2.4 ou 2.2, mas é importante que vocę entenda as diferenças antes de pesquisar. Năo é mais necessário rodar os comandos make dep e make clean. Também, o processo de compilaçăo do kernel năo é mais em modo descritivo na série 2.6. Isso resulta em uma construçăo de processos de fácil entendimento, porém tem seus contras. Se vocę tiver problemas na construçăo do kernel, é altamente recomendado que vocę habilite o modo descritivo de novo. Vocę pode fazer isso modificando a opçăo V=1 na construçăo. Isso permite a vocę ter mais informaçőes da saída da compilaçăo que poderá ajudar um desenvolvedor de kernel ou outro amigo entendido a te ajudar na resoluçăo deste problema.
# make bzImage V=1
Os módulos do kernel é outra definiçăo para os drivers de dispositivo que podem ser inseridos em um kernel em uso. Eles permitem a vocę extender o suporte ao hardware pelo seu kernel sem precisar usar outro kernel ou mesmo compilar um novo.
Os módulos podem também ser carregados e descarregados a qualquer hora, mesmo se o sistema estiver rodando. Isso torna a atualizaçăo de drivers mais fácil para os administradores de sistema. Um novo módulo pode ser compilado, um antigo removido, e o novo ser carregado em seu lugar, tudo isso sem precisar reiniciar sua máquina.
Os módulos săo armazenados no diretório /lib/modules/versăo do kernel do seu sistema. Eles podem ser carregados na inicializaçăo do sistema através do arquivo rc.modules. Este arquivo é muito bem documentado e oferece exemplos para a maior parte dos componentes de hardware. Para ver a lista dos módulos atualmente ativos, utilize o comando lsmod(1):
# lsmod
Module Size Used by
parport_pc 7220 0
parport 7844 0 [parport_pc]
Vocę pode ver aqui que eu só tenho o módulo da porta paralela carregado. Para remover um módulo, vocę usa o comando rmmod(1). Os módulos podem ser carregados pelos comandos modprobe(1) ou insmod(1). modprobe é normalmente mais seguro porque ele irá carregar qualquer módulo dos disponíveis que possuam dependęncias com o carregamento atual.
Vários usuários nunca tiveram que carregar ou descarregar módulos de kernel na măo. Eles utilizam o auto-carregamento do kernel para o gerenciamento de módulos. Por padrăo, o Slackware inclui o kmod em seu kernel. O kmod é uma opçăo do kernel que habilita o kernel para carregar automaticamente os módulos que săo requisitados. Para maiores informaçőes sobre o kmod e como ele é configurado, veja o arquivo /usr/src/linux/Documentation/kmod.txt. Vocę irá precisar do pacote de código-fonte do kernel, ou baixar o código-fonte do kernel de http://kernel.org.
Maiores informaçőes podem ser encontradas nas páginas de manual para cada um desses comandos, além do arquivo rc.modules.
Quando vocę instala inicialmente o Slackware, o programa setup chama o programa netconfig. O netconfig tem como objetivo realizar para vocę as seguintes funçőes:
Em geral o netconfig irá realizar cerca de 80% do trabalho de configurar sua conexăo de rede LAN, se vocę permitir. Recomenda-se fortemente que vocę revise seus arquivos de configuraçăo por duas razőes:
Uma vez que seu desejo é conectar sua máquina com o Slackware em algum tipo de rede, a primeira coisa que vocę precisará é de uma placa de rede compatível com o Linux. Vocę precisa ter um pouco de cuidado e se certificar de que sua placa é verdadeiramente compatível com o Linux (por favor, consulte o Projeto de Documentaçăo do Linux e/ou a documentaçăo do kernel para informaçőes sobre o status atual da placa de rede que vocę deseja utilizar). Via de regra vocę ficará, provavelmente muito surpreso com o número de placas de rede suportadas sob os kernels mais modernos. Tendo dito isso, sugerimos ainda que vocę consulte algumas das várias listas de hardwares compatíveis com o Linux (como por exemplo The GNU/Linux Beginners Group Hardware Compatibility Links e The Linux Documentation Project Hardware HOWTO) que estăo disponíveis na Internet antes de comprar sua placa. Um pequeno tempo extra gasto em pesquisa podem economizar dias ou até semanas tentando resolver problemas com placas năo compatíveis totalmente com o Linux.
Quando vocę visitar as listas de Hardware Compatível com o Linux disponíveis na Internet, ou quando consultar a documentaçăo do kernel instalado na sua máquina, preste atençăo em qual módulo que vocę irá precisar para suportar sua placa de rede.
Os módulos do kernel săo carregados durante a inicializaçăo do sistema săo carregados pelo arquivo rc.modules, /etc/rc.d, ou pelo carregador automático de módulos do kernel iniciado pelo /etc/rc.d/rc.hotplug. O arquivo rc.modules padrăo inclui uma seçăo de suporte a periféricos de rede. Se vocę abrir o rc.modules e procurar por esta seçăo, poderá notar que ele verifica inicialmente a existęncia do arquivo executável rc.netdevice em /etc/rc.d/. Esse script é criado se a tentativa de auto-configuraçăo do periférico de rede executada pelo setup obteve sucesso durante a instalaçăo.
Abaixo do bloco do "if" está uma lista de periféricos de rede e linhas com o comando modprobe comentadas. Procure o seu periférico e descomente a linha com o modprobe correspondente, e entăo salve o arquivo. Rodar o rc.modules como root irá, a partir de agora, carregar o driver do seu periférico de rede (assim como qualquer outro módulo listado e năo comentado). Note que alguns módulos (como o do driver ne2000) precisam de parâmetros; tenha certeza que vocę selecionou a linha correta.
Esse subtítulo abrange todas as placas de rede internas ISA ou PCI. Drivers para essas placas săo acessados via módulos carregáveis do kernel conforme dito no parágrafo anterior. É possível que o /sbin/netconfig tenha encontrado e configurado com sucesso sua placa no seu arquivo rc.netdevice. Se isso năo ocorreu o problema mais provável deve ser o carregamento do módulo incorreto para a placa em questăo (năo săo conhecidos casos onde para diferentes geraçőes de um mesmo tipo/família de placas de um mesmo fabricante sejam necessários módulos diferentes). Se vocę tęm certeza que o módulo que vocę quer carregar é o correto, sua próxima melhor açăo seria consultar a documentaçăo do módulo para verificar se o módulo exige ou năo algum(uns) parâmetro(s) específico(s) no momento em que o módulo é iniciado.
Assim como as placas de redes locais, modems podem ter várias opçőes de barramento suportadas. Até pouco tempo atrás a maioria dos modems eram placas com barramento ISA, de 8 ou 16 bits. Graças aos esforços da Intel e de fabricantes de placas-măe de todo o mundo, finalmente modems ISA fazem parte do passado, sendo comum atualmente que a maioria dos modems sejam modems externos que se conectam por uma porta serial ou USB, ou entăo modems internos PCI. Se vocę deseja trabalhar com seu modem no Linux, é de VITAL importância perquisar o modem que vocę pretende comprar, particularmente se vocę tem intençăo de comprar um modem PCI. Muitos, se năo a maioria, dos modems PCI atualmente disponíveis nas prateleiras das lojas săo WinModems. WinModems năo possuem algumas funçőes de hardware características dos próprios modems: as funçőes de responsabilidade desse hardware específico geralmente săo descarregadas sobre a CPU pelo driver do modem e pelo sistema operacional Windows. Isso significa que eles năo tem a interface serial padrăo que o PPPD estará esperando quando vocę disca para o seu Provedor de Acesso ŕ Internet.
Se vocę deseja ter absoluta certeza de que o modem que vocę está comprando irá trabalhar com o Linux, compre um modem de hardware externo que se conecta ŕ porta serial do seu PC. Com toda certeza esses irăo trabalhar melhor e apresentar menos problemas para instalar e dar manutençăo, em detrimento de precisarem de energia externa e tenderem a custar mais.
Há vários sites que oferecem drivers e assistęncia para configuraçăo de periféricos baseados em WinModems. Alguns usuários relatam sucessos na configuraçăo e instalaçăo de drivers para vários Winmodems, incluindo os de chipset Lucent, Conexant e Rockwell. Como os softwares necessários para esses periféricos năo fazem parte do Slackware, e variam de driver para driver, nós năo iremos entrar em detalhes.
Como parte da instalaçăo do seu Slackware, vocę terá a oportunidade de instalar o pacote pcmcia (na série "A" de pacotes). Esse pacote contém as aplicaçőes e arquivos de configuraçăo necessários para trabalhar com placas PCMCIA no Slackware. É importante notar que o pacote pcmcia instala apenas o software genérico necessário para trabalhar com placas PCMCIA no Slackware. Ele NĂO instala qualquer driver ou módulo. Os módulos e drivers disponíveis podem ser encontrados no diretório /lib/modules/`uname -r`/pcmcia. Vocę possivelmente precisará de algumas experięncias para encontrar o módulo que irá trabalhar com sua placa de rede. Vocę precisará editar o arquivo /etc/pcmcia/network.opts (para uma placa Ethernet) ou o /etc/pcmcia/wireless.opts (se vocę tem uma placa de rede sem fio). Como a maioria dos arquivos de configuraçăo do Slackware, esses dois arquivos săo muito bem comentados e isso torna fácil a tarefa de determinar que modificaçőes vocę precisa fazer.
Nesse momento, sua placa de rede deve estar físicamente instalada no seu computador, e os módulos relevantes do kernel devem estar carregados. Vocę ainda năo estará pronto para se comunicar utilizando sua placa de rede, mas informaçőes a respeito do seu periférico de rede podem ser obtidas com um ifconfig -a.
# ifconfig -a
eth0 Link encap:Ethernet HWaddr 00:A0:CC:3C:60:A4
UP BROADCAST NOTRAILERS RUNNING MULTICAST MTU:1500 Metric:1
RX packets:110081 errors:1 dropped:0 overruns:0 frame:0
TX packets:84931 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:114824506 (109.5 Mb) TX bytes:9337924 (8.9 Mb)
Interrupt:5 Base address:0x8400
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:2234 errors:0 dropped:0 overruns:0 frame:0
TX packets:2234 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:168758 (164.8 Kb) TX bytes:168758 (164.8 Kb)
Se vocę digitar /sbin/ifconfig, sem a opçăo -a, pode ser que vocę năo veja a interface eth0, o que indica que sua placa de rede ainda năo tem um endereço IP válido ou uma rota.
Uma vez que existem muitas formas diferentes de configurar uma rede, todas elas podem ser reduzidas a dois tipos: Estática e Dinâmica. Redes estáticas săo configuradas para que cada nó (nomenclatura geek para objetos que com um endereço IP) sempre tenha o mesmo endereço IP. Redes dinâmicas săo configuradas de forma que o endereço IP para cada nó seja controlado por um único servidor, chamado de servidor DHCP.
DHCP (Dynamic Host Configuration Protocol ou Protocolo de Configuraçăo Dinâmica de Host), é um método pelo qual um endereço IP pode ser atribuído a um computador quando esse é ligado. Quando o cliente é iniciado, ele envia uma requisiçăo na rede local para que um servidor DHCP lhe atribua um endereço IP. O servidor DHCP tem um conjunto (ou escopo) de endereços IP disponíveis. O servidor irá responder a essa requisiçăo com um endereço IP do seu conjunto, durante um tempo de alocaçăo. Uma vez que o tempo de alocaçăo para o endereço IP dado expire, o cliente precisa contactar novamente o servidor e repetir a negociaçăo.
Entăo, o cliente aceitará o endereço IP enviado pelo servidor e irá configurar a interface que requireu com o endereço IP. Entretanto, há ainda um macete manual que o cliente DHCP usa para negociar o endereço IP que será a ele atribuído. O cliente irá lembrar seu último endereço IP a ele atribuído, e solicitará ao servidor uma re-atribuiçăo do mesmo endereço IP novamente na próxima negociaçăo. Se possível, o servidor irá atender o pedido, mas se năo for, um novo endereço será atribuído. Assim, a negociaçăo se parece com o que segue:
Cliente: Há algum servidor DHCP disponível na rede local? Servidor: Sim, há. Aqui estou eu. Cliente: Eu preciso de um endereço IP. Servidor: Vocę pode pegar o 192.168.10.10 por 19200 segundos. Cliente: Obrigado. Cliente: Há algun servidor DHCP disponível na rede local? Servidor: Sim, há. Aqui estou eu. Cliente: Eu preciso de um endereço IP. Da última vez que conversamos, Eu peguei o 192.168.10.10; Posso pegá-lo novamente? Servidor: Sim, pode (ou Năo, năo pode: pegue o 192.168.10.12 dessa vez). Cliente: Obrigado.
O cliente DHCP no Linux é o /sbin/dhcpcd. Se vocę carregar o /etc/rc.d/rc.inet1 em seu editor de texto favorito, vocę irá notar que o /sbin/dhcpcd é chamado mais ou menos no meio do script. Isso irá forçar a o diálogo mostrado acima. O dhcpcd irá também controlar a quantidade de tempo de alocaçăo restante para o endereço IP atual, e irá contactar automaticamente o servidor DHCP com uma requisiçăo para renovaçăo da alocaçăo quando necessário. O DHCP pode ainda controlar informaçőes relacionadas, como qual o servidor ntp usar, qual rota pegar, etc.
Configurar DHCP no Slackware é simples. Apenas execute o netconfig e selecione DHCP quando oferecido. Se vocę tem mais de uma placa de rede e năo deseja que a eth0 seja configurada via DHCP, apenas edite o arquivo /etc/rc.d/rc.inet1.conf e mude a variável relacionada ŕ sua placa de rede para "YES".
Endereços IP estáticos săo endereços fixos que só mudam se modificadas manualmente. Isso é usado em qualquer caso em que o administrador năo deseje que as informaçőes relacionadas ao IP mudem, por exemplo para servidores internos de uma rede local, qualquer servidor conectado ŕ Internet, e roteadores. Com o endereçamento IP estático, vocę atribui um endereço IP e esquece :). Outras máquinas saberăo que vocę sempre terá um certo endereço IP e poderăo contactar vocę no endereço de sempre.
/etc/rc.d/rc.inet1.conf
Se vocę planeja atribuir um endereço IP ao seu novo Slackware, vocę pode fazę-lo através do script netconfig, ou entăo pode também editar o /etc/rc.d/rc.inet1.conf. No /etc/rc.d/rc.inet1.conf, vocę irá notar:
# Primary network interface card (eth0)
IPADDR[0]=""
NETMASK[0]=""
USE_DHCP[0]=""
DHCP_HOSTNAME[0]=""
E, mais abaixo:
GATEWAY=""
Nesse caso, nossa tarefa será meramente colocar a informaçăo correta entre as aspas duplas. Essas variáveis săo chamadas pelo /etc/rc.d/rc.inet1 no momento do boot para configurar as placas de rede. Para cada placa de rede, apenas insira a informaçăo correta do IP, ou coloque "YES" no USE_DHCP. O Slackware irá iniciar as interfaces com a informaçăo colocada na ordem em que elas forem encontradas.
A variável DEFAULT_GW configura a rota padrăo para o Slackware. Todas as comunicaçőes entre seu computador e outros computadores na Internet devem passar através do gateway, no caso de nenhuma outra rota ser especificada para elas (as comunicaçőes). Se vocę está usando DHCP, em geral vocę năo precisará digitar nada aqui, pois seu servidor DHCP irá especificar qual gateway usar.
/etc/resolv.conf
Muito bem. Entăo vocę tem um endereço IP, vocę tem um gateway padrăo, vocę pode ter dez milhőes de reais (nos dę um pouco), mas o que vocę consegue fazer de bom se vocę năo consegue traduzir nomes para endereços IP? Ninguém merece digitar 72.9.234.112 no navegador para entrar no www.slackbook.org. Além disso, quem, além dos autores conseguiriam memorizar esse endereço IP? Nós precisamos configurar o DNS, mas como? É aí que o /etc/resolv.conf entra no jogo.
Provavelmente vocę já tem as opçőes apropriadas no /etc/resolv.conf. Se vocę configurar sua conexăo de rede usando o DHCP, o servidor DHCP pode se encarregar de atualizar esse arquivo para vocę. (Tecnicamente o servidor DHCP apenas diz ao dhcpcd o quę colocar aqui, e ele obedece.) No entanto, se vocę precisa atualizar manualmente sua lista de servidores DNS, vocę precisará editar manualmente o /etc/resolv.conf. Segue um examplo:
# cat /etc/resolv.conf
nameserver 192.168.1.254
search lizella.net
A primeira linha é simples. A diretiva nameserver nos indica qual servidor DNS procurar. Por necessidade eles sempre săo endereços IP. Vocę pode ter vários listados aqui, conforme seu gosto. O Slackware irá alegremente checar um depois do outro até um deles retornar a busca.
A segunda linha é um pouco mais interessante. A diretiva search nos dá uma lista de domínio de nomes para assumir quando nenhum DNS requisitado for encontrado. Isso lhe permite contactar outra máquina tendo apenas a primeira parte da sua FQDN (Fully Qualified Domain Name, ou Domínio de Nome Totalmente Qualificado). Por exemplo, se "slackware.com" estava indicado na sua diretiva search, vocę pode buscar http://store.slackware.com apenas apontando seu navegador para http://store.
# ping -c 1 store
PING store.slackware.com (69.50.233.153): 56 data bytes
64 bytes from 69.50.233.153 : icmp_seq=0 ttl=64 time=0.251 ms
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.251/0.251/0.251 ms
/etc/hosts
Agora que nós temos um DNS trabalhando bem, o que podemos fazer se desejamos identificar nosso servidor DNS, ou adicionar uma entrade de DNS em uma máquina que năo está no DNS? O Slackware inclui o arquivo salvador /etc/hosts, que contém uma lista local de nomes DNS e endereços IP para os quais eles apontam.
# cat /etc/hosts
127.0.0.1 localhost locahost.localdomain
192.168.1.101 redtail
172.14.66.32 foobar.slackware.com
Nele vocę pôde notar que o localhost tęm como endereço IP relativo o 127.0.0.1 (sempre reservado para o localhost), redtail é apontado para 192.168.1.101, e o foobar.slackware.com para 172.14.66.32.
A maioria das pessoas continuam se conectando ŕ Internet através de algum tipo de conexăo discada. O método mais comum é o PPP, embora o SLIP seja ainda utilizado ocasionalmente. Configurar o seu sistema para utilizar chamar via PPP um servidor remoto é muito fácil. Nós vamos abordar algumas poucas ferramentas para ajudá-lo(a) a configurar.
O Slackware inclui um programa chamado pppsetup para configurar seu sistema para usar sua conta discada. Ele compartilha a aparęncia e parece muito semelhante ao nosso programa netconfig. Para executar o programa, tenha certeza que vocę está logado como root. Entăo digite pppsetup para executá-lo. Vocę irá ver uma tela como essa:
O programa apresentará uma série de questőes, as quais vocę precisará responder apropriadamente. Coisas como o seu modem, a string de inicializaçăo do modem, e o número de telefone do seu provedor. Alguns itens terăo um valor padrăo, que vocę poderá aceitar na maioria dos casos.
Após rodar o programa, ele criará um programa ppp-go e um programa ppp-off. Eles săo usados para iniciar e parar, respectivamente, a conexăo PPP. Os dois programas estăo em /usr/sbin e precisam de privilégios de root para serem executados.
/etc/ppp
Para a maioria dos usuários, rodar o pppsetup será o suficiente. Entretanto, podem haver circunstâncias onde vocę precisará preparar um conjunto de valores a serem usados pelo daemon do PPP. Todas as informaçőes de configuraçăo ficam em /etc/ppp. Aqui está uma lista do que vocę pode encontrar para diferentes arquivos:
| ip-down | Esse script é executado pelo pppd após o encerramento da conexăo PPP. |
| ip-up | Esse script é executado pelo pppd quando ocorre sucesso em uma conexăo ppp. Coloque nesse arquivo qualquer comando que vocę deseje executar após obter sucesso na conexăo. |
| options | Opçőes gerais para configuraçăo do pppd. |
| options.demand | Opçőes gerais de configuraçăo do pppd quando executado no modo de discagem por demanda. |
| pppscript | Os comandos enviados para o modem. |
| pppsetup.txt | Um log dos seus dados de entrada, quando executou o pppsetup. |
NOTA: A maioria desses arquivos năo estarăo lá até depois da execuçăo do pppsetup.
As redes sem fio ainda săo coisas relativamente novas no mundo dos computadores mesmo com o grande crescimento no número de pessoas que compram laptops e esperam encontrar redes por onde passem, sem se preocuparem com o seu velho cabo de par trançado. E essa tendęncia năo parece estar diminuindo o ritmo. Infelizmente, as redes sem fio năo săo ainda tăo bem suportadas no Linux, a exemplo das redes cabeadas tradicionais.
Existem tręs passos básicos no processo de configuraçăo de uma placa de rede sem fio:
O suporte ao hardware de placas sem fio é dado através do kernel, tanto com um módulo como com suporte direto (built in) no kernel. Geralmente, as placas mais recentes utilizam esse suporte com múdulos. Sendo assim,vocę pode determinar o módulo aproprioado e carregá-lo via /etc/rc.d/rc.modules. O netconfig pode năo detectar sua placa de rede sem fio. Nesses casos vocę provavelmente precisará determinar pessoalmente qual o módulo da sua placa. Procure mais informaçőes sobre drivers para o kernel de várias placas de rede sem fio, em http://www.hpl.hp.com/personal/Jean_Tourrilhes/Linux/.
A vasta maioria desse trabalho é feito pelo iwconfig, como sempre vocę pode ler o manual (com poderes de root, digite man iwconfig no terminal) do iwconfig se vocę precisa de mais informaçőes.
Antes de tudo, vocę precisará configurar o seu ponto de acesso sem fio. Pontos de acesso sem fio possuem uma pequena variaçăo em suas terminologias, e formas de configuraçăo, entăo vocę talvez precise se mexer um pouco para se acostumar ao seu hardware. Em geral, vocę precisará pelo menos das seguintes informaçőes:
AVISO: UMA NOTA A RESPEITO DO WEP. O WEP é bastante fraco, mas é muito melhor do que năo usar nada. Se vocę deseja um grau avançado de segurança na sua rede sem fio, vocę pode estudar VPNs ou IPSec. Ambos estăo fora do escopo deste documento. Vocę pode também configurar seu ponto de acesso para năo publicar sua ID de domínio/ESSID. Uma discussăo mais completa a respeito de políticas de redes sem fio está além do escopo desta seçăo, mas uma busca rápida no Google retornará mais do que vocę esperava aprender.
Uma vez que vocę tenha coletado as informaçőes acima, e assumindo que vocę usou o modprobe para carregar o driver apropriado no kernel, vocę pode editar o rc.wireless.conf e adicionar suas informaçőes. O arquivo rc.wireless.conf é um pouco desorganizado. Um esforço mínimo seria modificar a seçăo genérica com a sua ESSID, KEY, e CHANNEL, se isso for necessário ŕ sua placa. (Tente năo configurar o CHANNEL, e, se funcionar, ótimo! Se năo funcionar, configure o CHANNEL de forma apropriada.) Se vocę for audacioso pode modificar o arquivo de forma que apenas as variáveis necessárias sejam utilizadas. Os nomes das variáveis no rc.wireless.conf correspondem aos parâmetros do iwconfig. Săo lidos pelo rc.wireless e utilizados nos comandos iwconfig apropriados.
Se vocę tem sua chave em hexadecimal, o que é o ideal, será possível trabalhar de forma bastante confidencial, uma vez que seu ponto de acesso e o iwconfig estarăo com a chave acordada. Se vocę tem apenas uma sequęncia de caracteres, pode ter certeza que o seu ponto de acesso a traduzirá para uma chave em hexadecimal. Nesse caso pode ser necessário algum trabalho para descobrí-la (ou coloque sua chave do ponto de acesso em hexadecimal).
Uma vez que vocę modificou o rc.wireless.conf, execute o rc.wireless como root, e entăo rode o rc.inet1, novamente como root. Vocę pode testar sua rede sem fio com as ferramentas padrőes de testes, como o ping, junto com o iwconfig.
Se vocę tem uma interfaces que usem cabo, pode usar, se desejar, o ifconfig para desativá-las enquanto estiver testando sua rede sem fio, para ter certeza de năo estar havendo nenhuma confusăo de interface. Vocę pode também desejar testar o efeito das suas mudanças quando da reinicializaçăo do sistema.
Agora que vocę viu como editar o /etc/rc.d/rc.wireless para sua rede padrăo, vamos dar uma breve olhada no iwconfig para ver como ele trabalha. Isso vai lhe ensinar uma maneira rápida e direta para configurar o wifi para aquelas vezes em que vocę mesmo procura por sinal de Internet em um café, hotel, aeroporto ou qualquer outro hot spot wifi, desejando ficar online.
O primeiro passo é dizer ŕ sua interface wireless em qual rede entrar. Tenha certeza que vocę substituiu a "eth0" com qualquer outra interface que a sua placa de rede use e trocou a "mynetwork" para o essid que vocę deseja usar. Sim, nós temos certeza que vocę é esperto o bastante para isso. Depois disso vocę irá especificar a chave criptográfica (se existir) usada na sua rede sem fio. Finalmente, especifique que canal usar (se necessário).
# iwconfig eth0 essid "mynetwork"
# iwconfig eth0 key XXXXXXXXXXXXXXXXXXXXXXXXXXX
# iwconfig eth0 channel n
Isso encerra nosso assunto sobre redes sem fio.
Isso é feito exatamente da mesma maneira como era feito nas redes cabeadas. Simplesmente consulte a primeira parte desse capítulo.
Nesse ponto, vocę já deve ter uma conexăo TCP/IP trabalhando na sua rede. Vocę deve estar conseguindo enviar pings para outros computadores na sua rede interna e, se vocę configurou corretamente o gateway, deve também conseguir 'pingar' computadores da própria Internet. Como sabemos, o fator básico que nos leva a ligar umcomputador em uma rede é a possibilidade de acessar informaçőes. Enquanto algumas pessoas podem colocar seu computador numa rede apenas para se divertir nela, a maioria deseja compartilhar arquivos e impressoras. Elas desejam poder acessar documentos na Internet ou jogar online. Ter o TCP/IP instalado e functional no seu novo sistema Slackware é um bom inicío para tal, mas apenas com o TCP/IP instalado, as funcionalidades disponíveis serăo muito rudimentares. Para compartilhar arquivos, nós precisaremos usar o FTP ou o SCP para tranferí-los para lá e para cá. Năo podemos navegar por arquivos em nosso computador Slackware a partir de um vizinho na rede, ou nos ícones do Meus Locais Rede nos computadores com Windows. Da mesma forma, nós também gostaríamos de acessar arquivos em outras máquinas Unix.
Idealmente, nós gostaríamos de poder usar um sistema de arquivos de rede que nos permitisse acessar transparentemente nossos arquivos em outros computadores. Os programas que nós usamos para interagir com informaçőes armazenadas em nosso computador năo precisam, na verdade, saber em qual computador um dado arquivo está armazenado; eles apenas precisam saber que ele existe e como pegá-lo. É responsabilidade do sistema operacional gerenciar o acesso a arquivos através do sistema de arquivos disponível e dos sistemas de arquivo de rede. Os dois sistemas de arquivo de rede utilizados mais comumente săo o SMB (que é implementado pelo Samba) e o NFS.
O SMB (de Server Message Block) é um descendente do antigo protocolo NetBIOS, que foi inicialmente utilizado pela IBM em seus produtos gerentes de redes locais. A Microsoft também sempre se interessou bastante pelo NetBIOS e seus sucessores (NetBEUI, SMB e CIFS).O projeto Samba existe desde 1991, quando ele foi escrito originalmente para ligar um IBM PC rodando NetBIOS com um servidor Unix. Atualmente o SMB é o método preferido para compartilhamento de arquivos e serviços de impressăo sobre uma rede para, virtualmente, toda a populaçăo mundial, devido seu suporte ao Windows.
O arquivo de configuraçăo do Samba é o /etc/samba/smb.conf; um dos mais arquivos de configuraçăo mais bem comentado e documentado que vocę irá encontrar em qualquer lugar. Exemplos de compartilhamento săo configurados para sua visualizaçăo, e modificaçăo, se necessário. Se vocę precisa ter um controle preciso, o man (manual) do smb.conf é indispensável. Uma vez que o Samba é tăo bem documentado, conforme mencionamos acima, năo iremos reescrever a documentaçăo aqui. Iremos, no entanto, cobrir rapidamente os pontos básicos.
O smb.conf é repartido em múltiplas seçőes: uma seçăo para compartilhamento, e uma seçăo global para opçőes de configuraçăo que válida para todo o escopo do Samba. Algumas opçőes săo aceitas apenas na seçăo global; outras săo válidas apenas fora da seçăo global. Lembre-se que a seçăo global pode ser sobreposta por qualquer outra seçăo. Consulte as páginas do manual (man pages) para mais informaçőes. Vocę vai se sentir mais confortável se editar seu smb.conf de forma a refletir as configuraçőes da sua rede local. Sugerimos a modificaçăo dos itens listados abaixo:
[global] # workgroup = NT-Domain-Name or Workgroup-Name, eg: LINUX2 workgroup = MYGROUP
Substitua o nome do grupo de trabalho (workgroup) pelo grupo de trabalho da sua rede, ou pelo nome do domínio que vocę esteja usando localmente.
# server string is the equivalent of the NT Description field server string = Samba Server<
Esse será o nome do seu Slackware, quando mostrado na pasta de computadores vizinhos (ou Meus Locais de Rede).
# Security mode. Most people will want user level security. See # security_level.txt for details. NOTE: To get the behaviour of # Samba-1.9.18, you'll need to use "security = share". security = user
Muito provavelmente vocę vai querer implementar o nível de segurança por usuário no seu Slackware.
# You may wish to use password encryption. Please read # ENCRYPTION.txt, Win95.txt and WinNT.txt in the Samba # documentation. # Do not enable this option unless you have read those documents encrypt passwords = yes
Se as senhas criptografadas năo estăo ativadas, vocę năo poderá usar o Samba com os Windows NT 4.0, 2000, XP, e 2003. A princípio, o sistema operacional Windows năo requer encriptaçăo para compartilhamento de arquivos.
O SMB é um protocolo de autenticaçăo, o que significa que é necessário a entrada de um usuário e senha corretos, a fim de usar este serviço. Nós avisamos ao servidor samba que os usuários e senhas válidos estăo válidos com o comando smbpasswd. O smbpasswd realiza um par de testes de verificaçăo quando da adiçăo tradicional de usuários, ou da adiçăo de usuários da máquina (o SMB requer que vocę adicione os nomes dos computadores com NETBIOS como máquinas usuárias, restringindo que computares podem autenticar).
Adicionando um usuário ao arquivo /etc/samba/private/smbpasswd.
# smbpasswd -a user
Adicionando um nome de máquina ao arquivo /etc/samba/private/smbpasswd.
# smbpasswd -a -m machine
É importante notar que um dado usuário ou nome de máquina precisam existir previamente no arquivo /etc/passwd. Vocę pode realizar isso de maneira simples, com o comando adduser. Note que quando usamos o comando adduser para adicionar um nome de máquina precisamos pós-fixar um sinal de dólar ("$") ao nome da máquina. Entretanto, isso năo é feito com o smbpasswd.O próprio smbpasswd se responsabiliza pelo sinal de dólar pós-fixo. Se houver falhas no processo de inserçăo do nome da máquina com o adduser teremos como resultado um erro, quando adicionarmos o nome da máquina no samba.
# adduser machine$
O NFS (ou Sistema de Arquivos de Redes) foi originalmente escrito pela Sun para sua implementaçăo do Unix, o Solaris. Ao mesmo tempo que ele é significativamente mais fácil de adquirir e rodar, quando comparado ao SMB, também é significativamente menos seguro. A principal vunerabilidade no NFS é que ele é facilmente atingido por técnicas de spoof de usuários ou identificadores de grupo de uma máquina para outra. O NFS é um protocolo que năo implementa autenticaçăo. Versőes futuras do protocolo NFS estăo elaborando melhorias de segurança, mas elas năo săo comuns até a presente data.
A configuraçăo do NFS é controlada pelo arquivo /etc/exports. Se vocę carregar o /etc/exports padrăo em um editor, verá um arquivo em branco com duas linhas comentadas na parte mais superior. Precisaremos adicionar uma linha no arquivo de exportaçăo para cada diretório que quisermos exportar, com uma lista das estaçőes de trabalho clientes para as quais desejemos permitir o acesso aos arquivos. Por hora, se quisermos exportar o diretório /home/diretorio para a estaçăo de trabalho pc1, podemos simplesmente adicionar a linha:
/home/diretorio pc1(rw) no nosso /etc/exports. A seguir, vocę verá um exemplo encontrado na man page (manual) do arquivo exports:
# sample /etc/exports file / master(rw) trusty(rw,no_root_squash) /projects proj*.local.domain(rw) /usr *.local.domain(ro) @trusted(rw) /home/joe pc001(rw,all_squash,anonuid=150,anongid=100) /pub (ro,insecure,all_squash)
Como vocę pode ver, há várias opçőes disponíveis, e a maioria delas está representada claramente nesse exemplo.
O NFS assume que um dado usuário em uma máquina tem o mesmo user ID (número interno ao sistema operacional, que identifica um usuário) em todas as máquinas na rede. Quando uma consulta de leitura ou escrita de um cliente NFS para um servidor NFS, um UID (user ID) é passada como parte da requisiçăo de leitura/escrita. Esse UID é tratatada da mesma forma de uma requisiçăo de leitura/escrita originada na máquina local. Como vocę pode ver, se alguém, arbitrariamente, especificar um dado UID quando recursos acessam um sistema remoto, Coisas Ruins (tm) podem e devem ocorrer. Como uma cerca-viva protetora contra isso, cada diretório é montado com a opçăo root_squash. Isso mapeia o UID para qualquer usuário que alegue ser root para um UID diferente, prevenindo entăo o acesso de root a arquivos ou pastas no diretório exportado. A opçăo root_squash para estar inicialmente habilitada como uma medida de segurança, mas os autores recomendam sua especificaçăo individualmente para todos os diretórios no /etc/exports.
Vocę pode também exportar um diretório diretamente utilizando a linha de comando no servidor usando o comando exportfs, como segue:
# exportfs -o rw,no_root_squash pc1:/home/diretorio
Essa linha exporta o diretório /home/diretorio para o computador "pc1" e concede acesso de leitura/escrita ŕ máquina de nome pc1. A título de informaçăo o servidor NFS năo invocará o root_squash, o que significa que qualquer usuário do pc1, com o UID igual a "0" (UID do root) terá os mesmo privilégios de root no servidor. A síntaxe parece mesmo um pouco estranha (geralmente quando um diretório é especificado na síntaxe computador:/diretorio/arquivo, vocę está se referindo a um arquivo em um diretório, em um dado computador).
Vocę pode obter mais informaçőes no manual (man page) do arquivo exports.
Começando com o Slackware-10.0, o Ambiente de Janelas X é fornecido pelo Xorg. O X é o responsável por fornecer uma interface para o usuário, a qual, diferentemente do Windows ou do MacOS, é independente do sistema operacional.
O Sistema X Window é implementado através de diversos programas executados no ambiente do usuário. Os dois principais componentes săo o servidor e o gerenciador de janelas. O servidor fornece as funçőes de baixo nível para interagir com seu dispositivo de vídeo, sendo dessa forma específico para cada sistema. O gerenciador de janelas está acima do servidor e provę a interface do usuário. A vantagem disso é que vocę pode ter muitas interfaces de usuário diferentes, simplesmente trocando o gerenciador de janelas que vocę usa.
Configurar o X pode ser uma tarefa complexa. O motivo dessa complexidade é o grande número de dispostivos de vídeo disponíveis para a arquitetura PC, os quais usam interfaces de programaçăo diferentes. Felizmente, muitas das placas, hoje em dia, suportam os padrőes básicos de vídeo, conhecidos como VESA e se sua placa está entre essas, vocę será capaz de iniciar o X utilizando o comando startx, logo após a instalaçăo.
Caso isso năo funcione ou vocę queira obter as vantagens das características de alta-performance de sua placa, como aceleraçăo ou renderizaçăo 3-D via hardware, entăo será necessário reconfigurar o X.
Para configurar o X, será necessário criar o arquivo /etc/X11/xorg.conf. Esse arquivo contém muitos detalhes sobre seu dispositivo de vídeo, mouse e monitor. É um arquivo de configuraçăo muito complexo, mas, felizmente, existem programas para ajudar na criaçăo de um para vocę. Iremos mencionar alguns deles aqui.
Esta é uma interface simples orientada a menus que é similar ao instalador do Slackware. Ela pede ao servidor X que analize sua placa e entăo crie o melhor arquivo de configuraçăo inicial que pode ser feito, baseado na informaçăo obtida. O arquivo /etc/X11/xorg.conf é um bom ponto de partida para a maioria dos sistemas (e deve funcionar sem modificaçőes).
Este é um programa modo-texto de configuraçăo do X, o qual foi desenvolvido para administradores de sistemas experientes. Aqui está um "passo-a-passo" utilizando o xorgconfig. Primeiramente, inicie o programa:
# xorgconfig
Esta tela apresentará uma tela cheia de informaçőes sobre o xorgconfig. Para continuar, pressione ENTER; xorgconfig vai propor que verifique se vocę configurou a variável de ambiente PATH corretamente. Ela deve estar correta, assim vá em frente e aperte ENTER.
xorgconfig - Configuraçăo do Mouse
Selecione o seu mouse a partir do menu apresentado. Caso seu mouse serial năo esteja listado, selecione o protocolo Microsoft -- é o mais comum e provavelmente funcionará. Em seguida, xorgconfig irá lhe perguntar se deseja ativar as opçőes ChordMiddle e Emulate3Buttons; essas opçőes estarăo descritas em detalhes na tela. Use-as caso o botăo do meios de seu mouse năo funcionse sob o X, ou caso seu mouse somente tenha dois botőes (Emulate3Buttons permite a simulaçăo do botăo do meio atravás do pressionamento de ambos os botőes simultaneamente). Entăo, entre com o nome do arquivos de dispositivo de seu mouse; a escolha padrăo, /dev/mouse, deve funcionar desde que a ligaçăo tenha sido escolhida durante a configuraçăo do Slackware. Se vocę estiver executando o GPM (o servidor de mouse do Linux) no modo de repetiçăo, vocę poderá configurar o tipo de seu mouse para /dev/gpmdata, de modo que o X obtém informaçőes de seu mouse através do gpm(8). Em alguns casos (especialmente com o "busmice") isso pode funcionar melhor, mas muitos dos usuários năo devem fazer isso.
O xorgconfig vai lhe perguntar se eseja habilitar o conjunto de teclas especiais. Caso precise disso, diga "y". A maioria dos usuários podem dizer "n" -- digite isso se năo estiver certo.

xorgconfig - Sincronia Horizontal
Na próxima seçăo vocę informará o intervalo de sincronia horizontal de seu monitor. Para iniciar a configuraçăo de seu monitor, pressione ENTER. Vocę verá uma lista de tipos de monitores -- escolha um deles. Tenha cautela para năo exceder a especificaçăo de seu monitor, isso poderá danificá-lo.

xorgconfig - Sincronia Vertical
Especifique o intervalo de sincronia vertical de seu monitor (vocę poderá encontrar isso no manual do monitor). xorgconfig irá lhe pedir para entrar com os textos para a identificaçăo do tipo do monitor no arquivo xorg.conf. Digite o que quiser nestas tręs linhas (incluindo nada).

xorgconfig - Video Card
Agora vocę terá a oportunidade de olhar no banco de dados os tipos de placas de vídeo. Provavelmente vocę vai querer vę-lo, entăo responda "y" e selecione sua placa na lista exibida; caso vocę năo encontre a placa exata que possui, experimente selecionar uma que use o mesmo chipset (núcleo) e, provávelmente, irá funcionar bem.
Em seguinda, informe ao xorgconfig quanto de RAM possui sua placa de vídeo. O xorgconfig vai pedir um texto descriçăo sobre sua placa de vídeo, entăo, digite sobre a mesma caso deseje.
Vocę também será perguntado sobre a resoluçăo que deseja usar. Novamente, utilizar os valores padrőes pode ser legal para começar, de forma que depois vocę poderá editar o arquivo /etc/X11/xorg.conf e reajustar os modos, por exemplo, fazendo que 1024x768 (ou qualquer outro modo que prefira) seja o padrăo.
Nesse momento, xorgconfig vai perguntar se vocę quer que o arquivo de configuraçăo seja salvo. Diga que sim e o arquivo de configuraçăo será salvo, completando o processo de configuraçăo. Vocę poderá iniciar o X com o comando startx
O segundo caminho para configurar o X é usar o xorgsetup, um programa de configuraçăo um -- tanto quanto mágico -- que vem com o Slackware.
Para executar o xorgsetup, entre no sistema como root e digite:
# xorgsetup
Caso vocę já tenha um arquivo /etc/X11/xorg.conf (por já ter configurado o X), vocę será perguntado se deseja salvar uma cópia de segurança da configuraçăo atual antes de continuar. O arquivo original será renomeado para /etc/X11/xorg.conf.backup.
O xinit(1) é o programa que inicia o X; ele é chamado pelo startx(1), entăo vocę năo deve ter notado-o (e provavelmente nem precisava). Seu arquivo de configuraçăo, no entanto, determina quais programas (incluindo especialmente os gerenciadores de janela) săo executados quando o X inicia. xinit primeiramente verifica seu diretório pessoal em busca do arquivo .xinitrc. Caso o arquivo seja encontrado, é executado; caso contrário, /var/X11R6/lib/xinit/xinitrc (o padrăo global do sistema) é utilizado. Segue um exemplo simples do arquivo xinitrc:
#!/bin/sh
# $XConsortium: xinitrc.cpp,v 1.4 91/08/22 11:41:34 rws Exp $
userresources=$HOME/.Xresources usermodmap=$HOME/.Xmodmap sysresources=/usr/X11R6/lib/X11/xinit/.Xresources sysmodmap=/usr/X11R6/lib/X11/xinit/.Xmodmap
# junta os mapas de teclas padrăo
if [ -f $sysresources ]; then xrdb -merge $sysresources fi
if [ -f $sysmodmap ]; then xmodmap $sysmodmap fi
if [ -f $userresources ]; then xrdb -merge $userresources fi
if [ -f $usermodmap ]; then xmodmap $usermodmap fi
# inicia alguns programas legais
twm & xclock -geometry 50x50-1+1 & xterm -geometry 80x50+494+51 & xterm -geometry 80x20+494-0 & exec xterm -geometry 80x66+0+0 -name login
Todos aqueles blocos "if" săo para mesclar várias configuraçőes de outros arquivos. A parte interessante do arquivo é o final, onde vários programas săo executados. Esta sessăo do X vai começar com o gerenciador de janelas twm(1), um relógio e tręs terminais. Note que o exec antes do último xterm sobrepőe a shell em execuçăo, na qual está executando este script xinitrc, com o comando xterm(1). Assim, quando o usuário fechar o xterm, a sessăo do X irá terminar.
Para personalizar a incializaçăo do X, copie o arquivo padrăo /var/X11R6/lib/xinit/xinitrc para ~/.xinitrc e o edite, substituindo as suas linhas pelo que vocę desejar. O final do meu é simples:
# Inicia o gerenciador de janelas:
exec startkde
Note que existem diversos arquivos xinitrc.* em /var/X11R6/lib/xinit, os quais correspondem aos vários gerenciadores de janela e interfaces do usuário. Vocę pode usar qualquer um deles, caso deseje.
Durante anos, o Unix foi usado, quase que exclusivamente, como sistema operacional para servidores, com a exceçăo das poderosas estaçőes de trabalho. Somente os técnicos estavam familiarizados com o uso de um sistema operacional Unix (e suas variaçőes) e as interfaces para o usuário refletiam esse fato. As interfaces gráficas tendiam para ser, de longe, esqueletos, desenhados para executar poucas aplicaçőes gráficas, tais como programas CAD e renderizadores de imagem. Assim, muito do gerenciamento de arquivos e do sistema foi conduzido via linha de comando. Diversos vendedores (Sun Microsystems, Silicaon Graphics, etc) foram vendendo estaçőes que tentavam ter uma aparencia ("look and feel") coesiva, mas a grande variedade de Toolkits (conjunto de componentes para uma interface gráfica) usadas por desenvolvedores levou para a dissoluçăo da uniformidade dos ambientes gráficos. Dessa forma, uma barra de rolagem pode năo parecer igual em duas aplicaçőes diferentes; menus podem aparecer em diferentes lugares; programas podem ter diferentes botőes e caixas de checagem; havia um grande intervalo de cores e estas eram especificadas no código de cada toolkit. Como os usuários eram primariamente técnicos profissionais, isso năo importava muito.
Com o advento de sistemas operacionais gratuitos baseados no Unix e o crescente número e variedade de aplicaçőes gráficas, o X recentemente ganhou uma grande base de usuários no desktop. Muitos usuários, obviamente, estăo acostumados com a aparęncia consistente fornecida pelo Microsoft Windows ou pelo Apple MacOS; a falta de tal consistęncia em aplicaçőes baseadas no X se tornou uma barreira para sua aceitaçăo. Em resposta, dois projetos de código aberto foram formados: o K Desktop Environment (conhecido como KDE) e o GNU Network Object Model Environment (mais difundido como GNOME). Cada um tem uma variedade de aplicaçőes, que văo desde a barra de tarefas e gerenciadores de arquivo até jogos e suites de escritório, escritas com os mesmos Toolkits da interface e integradas para prover uma área de trabalho uniforme e consistente.
A diferença entre o KDE e GNOME săo de longe, grandes. Eles se parecem diferente um do outro por causa da utilizaçăo de diferentes Toolkits. O KDE se baseia na biblioteca gráfica QT (da Trolltech AS) enquanto o GNOME usa a GTK, uma biblioteca gráfica originalmente desenvolvida para o GIMP (em portuguęs, programa de manipulaçăo de imagens GNU). Como projetos separados, o KDE e o GNOME tęm seus próprios desenvolvedores e analistas. O resultado em cada caso, no entanto, tem sido fundamentalmente o mesmo: um ambiente consistente, uma área de trabalho integrada e uma grande coleçăo de aplicativos. A funcionalidade, usabilidade e detalhes de ambos năo é rival de nenhum outro sistema operacional disponível.
A melhor parte, no entando, é que esses ambientes avançados săo gratuitos. Isso significa que vocę pode ter um ou ambos (sim! ao mesmo tempo). A escolha é sua.
Em adiçăo aos ambientes GNOME e KDE, o Slackware inclui uma grande coleçăo de gerenciadores de janela. Alguns săo feitos para emular outros sistemas, outros para personalizaçăo e outros para se obter o máximo de desempenho. Existe uma variedade um tanto quanto grande. Obviamente, vocę pode instalar quantos quiser e, mecher com todos e decidir qual vocę gostou mais.
Para facilitar a seleçăo de ambientes de área de trabalho, O Slackware também incluiu um programa chamado xwmconfig que pode ser utilizado para selecionar o ambiente de área de trabalho ou gerenciador de janelas. Veja a seguir sua execuçăo:
$ xwmconfig
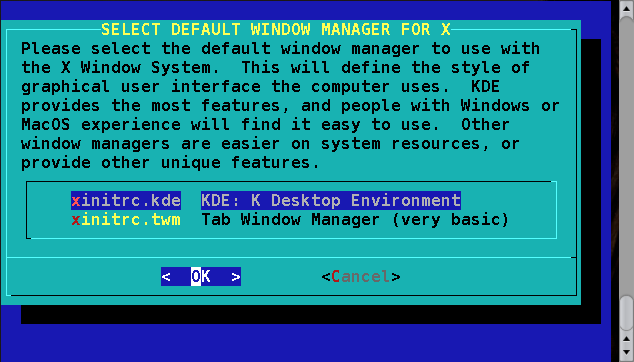
Vocę receberá uma lista de todos os ambientes de área de trabalho e gerenciadores de janelas disponíveis no sistema. Somente selecione da lista o qual deseja. Cada usuário precisará executar este programa, uma vez que diferentes usuários podem usar diferentes ambientes de área de trabalho, e nem todos văo querer o ambiente selecionado por vocę na instalaçăo.
Entăo apenas inicie o X e estará pronto.
Como Linux se tornou mais e mais usual como um sistema operacional de área de trabalho, muitos usuários acharam interessante o computador ligar diretamente no ambiente gráfico. Para isso, vocę precisará dizer ao Slackware para inicializar diretamente no X, e atribuir um gerenciador de login gráfico. O Slackware vem com tręs ferramentas de login gráfico,xdm(1), kdm e gdm(1).
O xdm á o gerenciador de login gráfico que vem com o sistema X.org. Ele é constantemente encontrado, mas năo possui tantos recursos como os alternativos. kdm é o gerenciador de login gráfico do KDE, o Ambiente de área de Trabalho K. Finalmente, gdm é o gerenciador de login do GNOME. Quaisquer que sejam a sua escolha vai permitir que vocę entre no sistema como qualquer usuário e escolha qual ambiente de trabalho deseja usar.
Infelizmente, O Slackware năo inclui um bom programa, como o xwmconfig, para selecionar qual gerenciador de login será utilizado, entăo se todos os tręs estăo instalados vocę pode fazer algumas ediçőes para selecionar o gerenciador de sua preferęncia. Mas primeiro, vamos discutir como iniciar o sistema no modo gráfico.
A fim de iniciar o X na inicializaçăo, vocę precisará inicializar no nível de execuçăo (run-level) 4. Níveis de execuçăo săo um modo de dizer ao init(8) para fazer algo diferente, quando o sistema operacional é iniciado. Nós fazemos isso alterando o arquivo de configuraçăo do init, /etc/inittab.
# Estes săo os níveis de execuçăo padrăo do Slackware: # 0 = desligamento # 1 = modo de usuário singular # 2 = năo utilizado (mas configurado da mesma forma que o nível de execuço 3) # 3 = modo multi-usuário (nível de execuçăo padrăo no Slackware) # 4 = X11 com KDM/GDM/XDM (gerenciadores de login) # 5 = inutilizado (mas configura para fazer o mesmo que o nível 3 # 6 = reinicializaçăo # nível de execuçăo padrăo (Năo configurar para 0 ou 6) id:3:initdefault:
A fim de fazer o Slackware inicializar no modo gráfico, nós somente mudaremos o 3 para o 4.
# nível de execuçăo padrăo (Năo configurar para 0 ou 6)
id:4:initdefault:
Agora o Slackware vai inicializar no nível de execuçăo 4 e executar o /etc/rc.d/rc.4. Este arquivos inicia o X e chama o gerenciador de login que vocę escolheu. Agora, como vamos escolher os gerenciadores de login? Existem alguns modos de fazer isso, e vamos explicar eles após em rc.4.
# Tenta utilizar o gerenciador de login do GNOME:
if [ -x /usr/bin/gdm ]; then
exec /usr/bin/gdm -nodaemon
fi
# Năo existe? OK, entăo tenta utilizar o gerenciador de login do KDE:
if [ -x /opt/kde/bin/kdm ]; then
exec /opt/kde/bin/kdm -nodaemon
fi
# Se tudo que tivermos for o XDM, acho que ele que vai entrar em açăo:
if [ -x /usr/X11R6/bin/xdm ]; then
exec /usr/X11R6/bin/xdm -nodaemon
fi
Como vocę pode ver aqui, rc.4 primeiro checa se o gdm é executável, e, caso seja, executa-o. Em segundo lugar na lista vem o kdm, e finalmente o xdm. Uma forma de escolher o gerenciador de login é simplesmente removendo os quais vocę năo quer usar utilizando o removepkg. Vocę pode encontrar mais sobre removepkg em Gerenciamento de Pacotes do Slackware.
Opcionalmente, vocę pode remover a permissăo de execuçăo dos arquivos que năo deseja usar. Nós vamos discutir chmod em Estrutura do Sistema de Arquivos.
# chmod -x /usr/bin/gdm
Finalmente, vocę pode somente comentar as linhas dos gerenciadores de login que năo quer usar.
# Tenta utilizar o gerenciador de login do GNOME:
# if [ -x /usr/bin/gdm ]; then
# exec /usr/bin/gdm -nodaemon
# fi
# Năo existe? OK, entă tenta utilizar o gerenciador de login do KDE:
if [ -x /opt/kde/bin/kdm ]; then
exec /opt/kde/bin/kdm -nodaemon
fi
# Se tudo que tivermos for o XDM, acho que ele que vai entrar em açăo:
# if [ -x /usr/X11R6/bin/xdm ]; then
# exec /usr/X11R6/bin/xdm -nodaemon
# fi
Qualquer linha precedida por um sustenido (#) săo consideradas comentários e o interpretador de comandos passa silenciosamente por elas. No entando, mesmo se o gdm está instalado e é executável, o interpretador de comandos (nesse caso o bash) năo vai se importar em checar isso.
O processo de boot de seu sistema Linux pode tanto ser fácil quanto difícil. Muitos usuários instalam o Slackware em seus computadores e pronto. Eles simplesmente o ligam e já está pronto para ser usado. Para outros, o simples ato de dar boot na máquina pode ser uma dor de cabeça. Para a maioria dos usuários, o LILO funciona melhor. O Slackware inclui o LILO e o LOADLIN para inicializar o Slackware Linux. O LILO funciona a partir de uma partiçăo de um disco rígido, da MBR de um disco rígido, ou de um disquete, o que o torna uma ferramenta versátil. O LOADLIN funciona a partir de uma linha de comando DOS, substituindo o DOS e chamando o Linux.
Outro utilitário popular para inicializar o Linux é o GRUB.
O GRUB năo está incluído nem é suportado oficialmente pelo Slackware. O Slackware mantém o padrăo "testado e aprovado" em tudo o que é incluído na distribuiçăo. Apesar do GRUB funcionar bem e incluir algumas funcionalidades que o LILO năo possui, o LILO realiza todas as tarefas essenciais de um sistema de boot de forma confiável e comprovada. Por ser mais recente, o GRUB ainda năo conseguiu este legado. Já que năo é incluído no Slackware, năo vamos discutir sobre ele aqui. Se vocę quiser usar o GRUB (talvez tenha vindo com outro sistema Linux e vocę queira usá-lo para dual boot), consulte a documentaçăo do GRUB.
Esta sessăo cobre o uso do LILO e do LOADLIN, os dois gerenciadores de boot incluídos no Slackware. Aqui também vemos alguns cenários típicos de dual boot e como configurá-los.
O Linux Loader, ou LILO, é o gerenciador de boot mais usado em sistemas Linux. Ele permite uma extensa gama de configuraçőes pode ser usado facilmente para dar boot em outros sistemas operacionais.
O Slackware Linux possui um utilitário de configuraçăo na forma de menu chamado liloconfig. Este utilitário é executado pela primeira vez durante o processo de configuraçăo, mas vocę pode chamá-lo mais tarde digitando liloconfig na linha de comando.
O LILO lę suas configuraçőes a partir do arquivo /etc/lilo.conf(5) Ele năo é lido toda vez que o computador é inicializado, e sim todas as vezes que o LILO é instalado. O LILO deve ser reinstalado no setor de boot sempre que houver uma alteraçăo na configuraçăo. Muitos erros do LILO acontecem quando se faz alteraçőes no arquivo lilo.conf, mas se esquece de reexecutar o lilo para instalar essas alteraçőes. O liloconfig ajuda a montar o arquivo de configuraçăo para que vocę possa instalar o LILO em seu sistema. Se preferir editar o /etc/lilo.conf manualmente, a reinstalaçăo do LILO envolve simplesmente a digitaçăo de /sbin/lilo (como root) na linha de comando.
Ao chamar pela primeira vez o liloconfig, ele será como:
liloconfig
Se esta for a primeira vez que vocę configura o LILO, escolha a opçăo simple (simples). Por outro lado, a opçăo expert (avançado) é mais rápida se vocę estiver familiarizado com o LILO e o Linux. Selecionando simple, a configuraçăo do LILO é iniciada.
Se o seu kernel estiver compilado com suporte a frame buffer, o liloconfig pergunta qual resoluçăo de vídeo vocę gostaria de usar. Esta resoluçăo também é usada pelo frame buffer do servidor XFree86. Se vocę năo quiser usar o console em um modo de vídeo especial, selecione normal para manter o modo texto padrăo de 80x25 em uso.
Na próxima parte da configuraçăo do LILO, selecione onde quer que ele seja instalado. Provavelmente este é o passo mais importante. A lista abaixo explica os locais de instalaçăo:
Esta opçăo instala o LILO no início de sua partiçăo raíz. Esta é a maneira mais segura se năo houver outros sistemas operacionais em seu computador. Ela assegura que outros gerenciadores de boot năo sejam sobreescritos. A desvantagem é que o LILO apenas carrega se o seu drive com o Linux for o primeiro drive em seu sistema. é por este motivo que muitos preferem criar uma pequena partiçăo /boot como o primeiro driver em seus sistemas. Isto permite que o kernel e o LILO sejam instalados no início do drive, onde o LILO consegue encontrá-los. Algumas versőes anteriores do LILO continham uma falha infame conhecida como "limite do cilindro 1024". O LILO năo conseguia inicializar kernels em partiçőes além do limite do cilindro 1024. As ediçőes recentes do LILO eliminaram esse problema.
Este método é ainda mais seguro do que o anterior. Ele cria um disquete que vocę pode usar para dar boot no seu sistema Linux. Isto mantém o gerenciador de boot completamente fora do seu disco rígido. Desse modo, se quiser usar o Slackware, vocę somente conseguirá iniciar o seu sitema usando este disquete. As falhas deste sistema săo óbvias. Os disquetes săo conhecidos por serem frágeis, propensos a dar defeitos. Além disso, o gerenciador de boot năo está mais contido no computador. Se vocę perder o seu disquete, terá que fazer outro para inicializar o o seu sistema.
Este método é escolhido quando o Slackware é o único sistema operacional em seu computador, ou se o LILO for usado para escolher entre múltiplos sistemas operacionais em seu computador. Este é o método recomendado para a instalaçăo do LILO e funciona em quase qualquer sistema.
AVISO: Esta opçăo sobreescreve qualquer outro gerenciador de boot que porventura exista na MBR.
Após a seleçăo do local de instalaçăo, o liloconfig cria o arquivo de configuraçăo e instala o LILO. E pronto. Se escolher o modo expert, é apresentado um menu especial. Este menu permite fazer ajustes avançados no arquivo /etc/lilo.conf, adiconar outros sistemas operacionais no seu menu de boot, e ajustar o LILO para passar parâmetros especiais ao kernel durante o boot. O menu expert se parece com a figura abaixo:
liloconfig - Menu Expert
Qualquer que seja a configuraçăo do seu sistema, é fácil configurar um gerenciador de boot que funcione. O liloconfig torna essa tarefa uma moleza.
A outra opçăo para a inicializaçăo que vem com o Slackware Linux é o LOADLIN. O LOADLIN é um executável DOS que pode ser usado para iniciar o Linux a partir de um sistema DOS em execuçăo. Ele requer que o kernel do Linux esteja na partiçăo DOS para que o LOADLIN possa carregá-lo e inicializar o sistema adequadamente.
Durante o processo de boot, o LOADLIN é copiado para o diretório home do usuário root como um arquivo .ZIP. Năo há um processo de instalaçăo automática para o LOADLIN. é necessário copiar o kernel do Linux (geralmente /boot/vmlinuz) e o arquivo LOADLIN do diretório home do usuário root para a partiçăo do DOS.
O LOADLIN é útil quando se deseja fazer um menu de boot em sua partiçăo DOS. Pode-se adicionar um menu ao seu arquivo AUTOEXEC.BAT para permitir a escolha entre o Linux e o DOS. Escolhendo o Linux o LOADLIN é executado, assim inicializando o seu sistema Slackware. O exemplo abaixo do arquivo AUTOEXEC.BAT para o Windows 95 cria um menu de boot satisfatório:
@ECHO OFF
SET PROMPT=$P$G
SET PATH=C:\WINDOWS;C:\WINDOWS\COMMAND;C:\
CLS
ECHO Selecione o sistema operacional:
ECHO.
ECHO [1] Slackware Linux
ECHO [2] Windows 95
ECHO.
CHOICE /C:12 "Selection? -> "
IF ERRORLEVEL 2 GOTO WIN
IF ERRORLEVEL 1 GOTO LINUX
:WIN
CLS
ECHO Iniciando o Windows 95...
WIN
GOTO END
:LINUX
ECHO Iniciando o Slackware Linux...
CD \LINUX
LOADLIN C:\LINUX\VMLINUZ ROOT=<dispositivo da partiçăo root> RO
GOTO END
:END
Especifique a sua partiçăo root com o nome do dispositivo no Linux, tal como /dev/hda2 ou algo semelhante. Vocę também pode usar o LOADLIN a partir da linha de comando. Simplesmente use-o como no exemplo acima. A documentaçăo do LOADLIN possui muitos exemplos sobre o seu uso.
Muitos usuários configuram os seus computadores para inicializar o Slackware Linux e outro sistema operacional (o que se chama dual boot). Descrevemos vários cenários típicos de dual boot abaixo, em caso de haver dificuldades para configurar o seu sistema.
Provavelmente o cenário mais comum de dual boot é com o MS Windows e o Linux. Há várias maneiras de se configurar a inicializaçăo, mas esta sessăo abrangerá duas delas.
Ŕs vezes, ao configurar um sistema com dual boot se cria um plano perfeito em relaçăo a onde tudo vai ficar, mas se confunde a ordem de instalaçăo. é muito importante compreender que os sistemas operacionais devem ser instalados em uma determinada ordem para que o dual boot funcione. O Linux sempre oferece controle sobre o que, se for o caso, é gravado na MBR (Master Boot Record - Registro Principal de Inicializaçăo). Portanto, é aconselhável instalar o Linux por último. O Windows deve ser instalado primeiro, já que ele sempre grava seu gerenciador de boot na MBR, sobreescrevendo as configuraçőes porventura gravadas pelo Linux.
Usando o LILO
A maioria dos usuários preferem usar o LILO para escolher entre o Linux e o Windows. Como foi citado acima, instale primeiramente o Windows, e, entăo, o Linux.
Digamos que o único drive no seu sistema seja um disco rígido IDE de 40GB. Suponhamos também que vocę queira deixar a metade do espaço para o Windows e a outra metade para o Linux. Haverá um problema ao tentar iniciar o Linux.
20GB Windows boot (C:)
1GB Linux root (/)
19GB Linux /usr (/usr)
Vocę deve separar também um espaço adequado para uma partiçăo de troca (swap) para o Linux. A regra geral é usar o dobro da quantidade de memória RAM. Um sistema com 64MB deve ter 128MB de swap, e assim por diante. O espaço de swap adequado é alvo de muitas discussőes inflamadas no IRC e na Usenet. Na verdade năo há uma forma "correta" de fazer, mas a regra acima deve ser satisfatória.
Com as suas partiçőes prontas, comece a instalaçăo do Windows. Depois que estiver configurado e funcionando, instale o Linux. A instalaçăo do LILO requer atençăo especial. Talvez vocę prefira escolher o modo expert para instalar o LILO.
Inicie uma nova configuraçăo do LILO. Prefira instalar na MBR para que possa ser usado para escolher entre ambos os sistemas operacionais. No menu, adicione a sua partiçăo Linux e a sua partiçăo Windows (ou DOS). Assim que este passo estiver completo, pode instalar o LILO.
Reinicie o seu computador. O LILO deve ser carregado e exibir um menu que permite a escolha entre os sistemas operacionais instalados. Selecione o nome do Sistema Operacional que deseja carregar (esses nomes foram escolhidos na configuraçăo do LILO).
O LILO é um gerenciador de boot altamente configurável. Ele năo se limita a iniciar o Linux ou o DOS. Ele pode iniciar praticamente qualquer coisa. As páginas de manual do lilo(8) e do lilo.conf(5) fornecem informaçőes mais detalhadas.
E se o LILO năo funcionar? Há casos onde o LILO năo funciona em uma máquina específica. Felizmente, há outra maneira de fazer dual boot entre o Linux e o Windows.
Usando o LOADLIN
Este método pode ser usado se o LILO năo funcionar em seu sistema, ou se vocę năo quiser configurar o LILO. Este método também é ideal para o usuário que reinstala o Windows freqüentemente. A cada reinstalaçăo do Windows, ele sobreescreve A MBR, assim destruindo a instalaçăo do LILO. Com o LOADLIN, vocę năo está sujeito a esse problema. A maior desvantagem é que o LOADLIN somente pode ser usado para iniciar o Linux.
Com o LOADLIN, os sistemas operacionais podem ser instalados em qualquer ordem. Cuidado para năo fazer instalaçőes na MBR, vocę năo quer fazer isso. O LOADLIN depende de que a partiçăo do Windows seja inicializável. Entăo, durante a instalaçăo do Slackware, assegure-se de pular a configuraçăo do LILO.
Após a instalaçăo dos sistemas operacionais, copie o arquivo loadlinX.zip (onde X é o número da versăo, tal como 16a) do diretório home do usuário root para a sua partiçăo Windows. Copie também a imagem do seu kernel para a partiçăo do Windows. Para isso funcionar, é necessário estar no Linux. O exemplo abaixo mostra como fazer isso:
# mkdir /win
# mount -t vfat /dev/hda1 /win
# mkdir /win/linux
# cd /root
# cp loadlin* /win/linux
# cp /boot/vmlinuz /win/linux
# cd /win/linuz
# unzip loadlin16a.zip
É criado um diretório C:\LINUX em sua partiçăo Windows (supondo que seja /dev/hda1) e tudo que é necessário ao LOADLIN é copiado. Após isso, é necessário reiniciar o Windows para configurar um menu de boot.
De volta ao Windows, abra uma janela do DOS. Primeiro, temos que assegurar que o sistema esteja configurado para năo iniciar na interface gráfica.
C:\> cd \
C:\> attrib -r -a -s -h MSDOS.SYS
C:\> edit MSDOS.SYS
Adicione esta linha ao arquivo:
BootGUI=0
Agora salve o arquivo e saia do editor. Agora edite o C:\AUTOEXEC.BAT para que possamos adicionar um menu de boot. O exemplo abaixo mostra como deve ser um bloco de menu de boot no AUTOEXEC.BAT:
cls
echo System Boot Menu
echo.
echo 1 - Linux
echo 2 - Windows
echo.
choice /c:12 "Selection? -> "
if errorlevel 2 goto WIN
if errorlevel 1 goto LINUX
:LINUX
cls
echo "Iniciando o Linux..."
cd \linux
loadlin c:\linux\vmlinuz root=/dev/hda2 ro
goto END
:WIN
cls
echo "Iniciando o Windows..."
win
goto END
:END
A linha principal é a que chama o LOADLIN. Dizemos qual kernel carregar, a partiçăo root do Linux, e que inicialmente queremos que seja montada somente para leitura.
As ferramentas necessárias para esse método săo fornecidas com o Slackware Linux. Há vários outros gerenciadores de boot no mercado, mas esses devem funcionar ma maioria das configuraçőes de dual boot.
Esta é a situaçăo de dual boot menos comum. Nos velhos tempos do o LILO năo conseguia iniciar o Windows NT, o que requeria que os usuários do Linux alterassem a NTLDR, que apresentava muito mais problemas do que o dual boot entre o Windows 9x e o Linux. Esteja ciente de que as instruçőes abaixo estăo ultrapassadas. O LILO já consegue iniciar o Windows NT/2000/XP/2003 há vários anos. Contudo, se vocę estiver usando uma máquina antiga, este procedimento pode ser necessário.
A instalaçăo do Windows NT deve ser bem direta, assim como deve ser a instalaçăo do Linux. A partir desse ponto, fica mais complicado. Pegar os primeiros 512 bytes da partiçăo do Linux é mais fácil do que parece. Para isso, vocę precisa estar no Linux. Supondo que a sua partiçăo Linux seja /dev/hda2, digite o comando:
# dd if=/dev/hda2 of=/tmp/bootsect.lnx bs=1 count=512
Só isso. Agora vocę precisa copiar o bootsect.lnx para a partiçăo do Windows NT. Aqui ocorre outro problema. O Linux năo possui suporte estável para gravaçăo em sistemas NTFS. Se vocę tiver instalado o Windows NT e formatado o seu drive como NTFS, será necessário copiar esse arquivo para um disquete com FAT e entăo ler a partir dele no Windows NT. Se vocę tiver formatado o drive do Windows NT como FAT, pode simplesmente montá-lo no Linux e copiar o arquivo. De qualquer modo, copie o /tmp/bootsect.lnx do Linux para C:\BOOTSECT.LNX no Windows NT.
O último passo é adicionar uma opçăo no menu de boot do Windows NT. No Windows NT, abra um terminal.
C:\WINNT> cd \
C:\> attrib -r -a -s -h boot.ini
C:\> edit boot.ini
Adicione esta linha ao final do arquivo:
C:\bootsect.lnx="Slackware Linux"
Salve as alteraçőes e saia do editor. Ao reiniciar o Windows NT, aparecerá uma opçăo para o Linux no menu. Selecione-a para iniciar o Linux.
Sim, isso realmente é feito. Definitivamente, este é o cenário de dual boot mais simples. Pode-se simplesmente usar o LILO e adicionar mais entradas no arquivo /etc/lilo.conf. Isso é tudo.
Em um ambiente gráfico, a interface é apresentada por um programa que cria janelas, barras de rolagem, menus, etc. Em um ambiente de linha de comando, a interface com o usuário é apresentada por um shell, que interpreta os comandos e geralmente torna as coisas úteis. Imediatamente após entrar no sistema (o que é visto neste capítulo), os usuários săo colocados em um shell e podem fazer o seu trabalho. Este capítulo serve como uma introduçăo ao shell, e ao shell mais comum entre os usuários do Linux - o Bourne Again Shell (bash). Para maiores informaçőes sobre qualquer tópico deste capítulo, veja a página de manual do bash(1).
Entăo vocę iniciou o Linux, e está olhando para algo que se parece com isso:
Welcome to Linux 2.4.18
Last login: Wed Jan 1 15:59:14 -0500 2005 on tty6.
darkstar login:
Hă... ninguém disse nada sobre um login. E o que é darkstar? Năo se preocupe; provavelmente vocę năo abriu acidentalmente um link de comunicaçăo espacial com a lua artificial do Império. (Infelizmente, o protocolo de link de comunicaçăo espacial ainda năo tem suporte no kernel do Linux. Talvez a série 2.8 do kernel finalmente tenha suporte a esse protocolo tăo esperado.) Năo, darkstar é apenas o nome de um dos nossos computadores, e seu nome aparece por padrăo. Se vocę tiver especificado um nome para o seu computador durante a configuraçăo, ele deve ser exibido em vez de darkstar.
Quanto ao login... Se for a sua primeira vez, vocę deve entrar como root. Será pedida uma senha; se vocę tiver criado uma durante o processo de configuraçăo, é essa senha que será pedida. Se năo, simplesmente pressione enter. Isso aí - vocę entrou!
Ok, quem ou o que é o root? E o que está fazendo com uma conta em meu sistema?
Bem, no mundo Unix e dos sistemas operacionais semelhantes (como o Linux), há usuários e usuários. Veremos maiores detalhes depois, mas o que importa por enquanto é saber que o root é o maior usuário de todos; o root é onipotente e onisciente, e ninguém desobedece o root. Isso simplesmente năo é permitido. O root é o que chamamos de "super usuário", e realmente ele é. E o que é melhor, o root é vocę.
Legal, hein?
Se vocę estiver em dúvida: sim, isso é muito legal. O problema é, contudo, que o root pode por sua natureza, pode quebrar tudo o que desejar. Vocę pode querer ir direto para a seçăo 12.1.1 e ver como adicionar um usuário; e, entăo, entre no sistema e continue daqui. A sabedoria popular diz que é melhor só se tornar o super usuário quando for absolutamente necessário, de forma a minimizar a possibilidade de estragar algo acidentalmente.
A propósito, năo há problemas se vocę decidir que quer se tornar o root enquanto está no sistema como outro usuário. É só usar o comando su(1). Vocę terá que informar a senha de root e se tornará o root até que dę o comando exit ou logout. Vocę também pode se tornar qualquer outro usuário usando o su, desde que saiba a sua senha: su logan, por exemplo, permitiria que vocę fosse eu.
NOTA: O root pode dar o su para qualquer usuário, sem precisar de senha.
Năo há muito o que fazer sem executar um programa; deve dar para apoiar algo com o seu computador ou manter uma porta aberta, e alguns fazem um zumbido maravilhoso quando estăo ligados, mas năo é para isso que servem. E acho que podemos concordar que ser usado como batente para portas năo é o que trouxe popularidade aos computadores pessoais.
Entăo, lembra-se de que quase tudo no Linux é um arquivo? Bem, isso também vale para programas. Cada comando que vocę executa (que năo é funçăo nativa do shell) reside em um arquivo em algum lugar. Vocę executa um programa simplesmente especificando o caminho completo até ele.
Por exemplo, lembra-se do comando su da seçăo acima? Bem, na verdade ele está no diretório /bin: /bin/su o executaria perfeitamente.
Por que, entăo, digitar apenas su funciona? Afinal, vocę năo disse que ele estava em /bin. Poderia também estar em /usr/local/share, certo? Como o sistema sabia? A resposta está na variável de ambiente PATH; a maioria dos shells possui o PATH ou algo muito parecido com o PATH. Essa variável basicamente contém uma lista de diretórios, para procurar os programas que vocę tenta executar. Entăo, quando vocę executou su, o seu shell percorreu sua lista de diretórios, procurando em cada um o arquivo executável chamado su que pudesse executar; assim que encontrou algum, ele o executou. Isto acontece sempre que vocę executa um programa sem especificar o caminho completo para ele; se der um erro de "Command not found" (comando năo encontrado), isso significa que o programa que tentou executar năo está em seu PATH. (É claro que isso seria verdadeiro se o programa năo existisse...) Discutiremos as variáveis de ambiente com maiores detalhes em variáveis de ambiente.
Lembre-se, também, que o "." é um atalho para o diretório atual, entăo se vocę estivesse em /bin, ./su funcionaria como um caminho completo explícito.
Quase todo shell reconhece alguns caracteres como substitutos ou abreviaçőes que significam que qualquer caracter encaixa aqui. Estes caracteres săo chamados de meta-caracteres; os mais comuns săo * e ?. Por convençăo, o ? geralmente substitui qualquer caractere único. Por exemplo, suponha que esteja em um diretório com tręs arquivos: ex1.txt, ex2.txt, e ex3.txt. Vocę quer copiar todos estes arquivos (usando o comando cp visto na seçăo 10.5.1) para outro diretório, digamos /tmp. Bem, digitar cp ex1.txt ex2.txt ex3.txt /tmp é trabalhoso demais. É muito mais fácil digitar cp ex?.txt /tmp; o ? combina com qualquer um dos caracteres "1", "2", e "3", e cada um, por sua vez, será substituído.
O que disse? Isto ainda dá muito trabalho? Vocę está certo. Isto é assustador; temos leis trabalhistas para nos proteger deste tipo de coisa. Felizmente, também temos o *. Como já foi mencionado, o * substitui "qualquer número de caracteres", inclusive 0. Entăo se aqueles tręs arquivos fossem os únicos no diretório, poderíamos simplesmente dizer cp * /tmp e pegar todos com um só golpe. Suponha, contudo, que também exista um arquivo chamado ex.txt e um chamado hejaz.txt. Queremos copiar o ex.txt, mas năo o hejaz.txt; O cp ex* /tmp faz isso para nós.
O cp ex?.txt /tmp, somente iria, é claro, pegar os nossos tręs arquivos originais; năo há um caractere em ex.txt para combinar com o ?, entăo ele ficaria de fora.
Outro meta-caractere comum é o par de colchetes [ ]. Quaisquer caracteres dentro dos colchetes substituem de acordo com o padrăo informado em [ ] para encontrar combinaçőes. Parece confuso? Năo é tăo ruím. Suponha, por exemplo, que um diretório contém os 8 seguintes arquivos: a1, a2, a3, a4, aA, aB, aC, e aD . Queremos encontrar apenas os arquivos que terminam com números; o [ ] fará isso para nós.
$ ls a[1-4] a1 a2 a3 a4
Mas o que realmente queremos é apenas os arquivos a1, a2 e a4? no exemplo anterior usamos - significando todos os valores entre 1 e 4. Também podemos separar entradas individuais usando vírgulas.
$ ls a[1,2,4] a1 a2 a4
Sei que agora vocę está pensando Bem, e quanto as letras? O Linux distingue entre maiúsculas e minúsculas, o que significa que a é diferente de A e que só săo relacionados em sua mente. As letras maiúsculas sempre vęm antes das letras minúsculas, entăo A e B vęm antes de a e b. Dando continuidade ao nosso exemplo anterior, se quiséssemos os arquivos a1 e A1, podemos encontrá-los rapidamente com o [ ].
$ ls [A,a]1 A1 a1
Observe que se incluíssemos um hífen em vez de uma vírgula, obteríamos resultados incorretos.
$ ls [A-a]1 A1 B1 C1 D1 a1
Também pode combinar hífen e vírgula.
$ ls [A,a-d]1 A1 a1 b1 c1 d1
(Lá vem algo legal.)
$ ps > blargh
Sabe o que é isso? Estou executando o ps para ver quais processos estăo em execuçăo; o ps está na seçăo 11.3. Essa năo é a parte legal. A parte legal é > blargh, que significa, a grosso modo, pegue a saída do ps e mande para um arquivo chamado blargh. Mas espere, vai ficar mais legal.
$ ps | less
Este pega a saída do ps e a manda através do less, entăo posso subir ou descer a página conforme a minha vontade.
$ ps >> blargh
Este é o terceiro redirecionador mais usado; ele faz o mesmo que o ">", exceto pelo fato de que o ">>" adiciona a saída do ps ao final do arquivo blargh, se este arquivo existir. Se năo, assim como o ">", ele será criado. (O ">" substitui o conteúdo atual do arquivo blargh.)
Também há o operador "<", que significa pegue a entrada a partir do saída, mas năo é usado tăo freqüentemente.
$ fromdos < dosfile.txt > unixfile.txt
O redirecionamento fica mesmo divertido quando começa a ser combinado:
$ ps | tac >> blargh
Isso executa o ps, reverte as linhas de sua saída, e as adiciona ao arquivo blargh. Vocę pode empilhar quantos redirecionadores desejar; apenas tenha o cuidado de se lembrar de que eles săo interpretados da esquerda para a direita.
Veja a página de manual do bash(1) para encontrar informaçőes mais detalhadas sobre redirecionamento.
Um sistema Linux é uma fera complexa, e há muito para se lembrar, muitos pequenos detalhes que fazem diferença nas suas interaçőes normais com vários programas (alguns dos quais vocę năo deve nem ter ouvido falar). Ninguém precisa passar um monte de opçőes para cada programa que é executado, dizendo a ele que tipo de terminal está sendo usado, o nome da máquina, como o seu prompt deve ser...
Exemplo: Listando as Variáveis de Ambiente com o set
$ set
PATH=/usr/local/lib/qt/bin:/usr/local/bin:/usr/bin:/bin:/usr/X11R6/bin:/usr/openwin/bin:/usr/games:
:/usr/local/ssh2/bin:/usr/local/ssh1/bin:/usr/share/texmf/bin:/usr/local/sbin:/usr/sbin:/home/logan/bin
PIPESTATUS=([0]="0")
PPID=4978
PS1='\h:\w\$ '
PS2='> '
PS4='+ '
PWD=/home/logan
QTDIR=/usr/local/lib/qt
REMOTEHOST=ninja.tdn
SHELL=/bin/bash
Entăo, como um mecanismo de ajuda, os usuários contam com o que se chama de ambiente. O ambiente define as condiçőes nas quais os programas săo executados, e algumas destas definiçőes săo variáveis; o usuário pode alterar e brincar com elas, de forma que só acontece em um sistema Linux. Praticamente qualquer shell possui variáveis de ambiente (se năo, provavelmente năo é um shell muito útil). Daremos uma visăo geral dos comandos do bash para a manipulaçăo das suas variáveis de ambiente.
O set sozinho exibe todas as variáveis de ambiente definidas atualmente, assim como seus valores. Como a maioria das funçőes nativas do bash, também pode fazer várias outras coisas (com parâmentros); deixaremos a página de manual do bash(1) cobrir esses detalhes, entretanto. O Exemplo acima mostra um trecho da saída de um comando set executado em um dos computadores do autor. Observe nesse exemplo a variável PATH que foi discutida acima. Os programas de cada um destes diretórios podem ser executados simplesmente digitando-se o nome do arquivo.
$ unset VARIAVEL
O comando unset remove as variáveis que vocę indicar, apagando tanto a variável quanto o seu conteúdo; O bash esquece que a variável já existiu. (Năo se preocupe. A năo ser que seja algo que vocę definiu explicitamente naquela sessăo do shell, provavelmente será redefinida em uma outra sessăo.)
$ export VARIAVEL=algum_valor
O comando export é realmente prático. Usando-o, vocę dá ŕ variável de ambiente VARIAVEL o valor "algum_valor"; se VARIAVEL năo existia, passa a existir. Se VARIAVEL já possuir um valor, bem, já era. Isso năo é tăo bom se vocę estiver apenas tentando adicionar um diretório ŕ sua variável PATH. Neste caso, vocę provavelmente quer fazer alguma coisa como:
$ export PATH=$PATH:/um/novo/diretorio
Observe o uso de $PATH aqui: quando se quer que o bash interprete uma variável (substituí-la por seu valor), adicione um $ ao início do nome da variável. Por exemplo, echo $PATH exibe o valor de PATH, no meu caso:
$ echo $PATH
/usr/local/lib/qt/bin:/usr/local/bin:/usr/bin:/bin:/usr/X11R6/bin:
/usr/openwin/bin:/usr/games:.:/usr/local/ssh2/bin:/usr/local/ssh1/bin:
/usr/share/texmf/bin:/usr/local/sbin:/usr/sbin:/home/logan/bin
(Aqui vai outra coisa legal.)
Vocę está no meio de um trabalho e decide que precisa fazer outra coisa. Vocę poderia simplesmente parar o que está fazendo e alternar as tarefas, mas este sistema é multi-usuário, năo é? E vocę pode entrar no sistema quantas vezes quiser simultaneamente, năo pode? Entăo por que teria que fazer uma coisa de cada vez?
Năo precisa. Nem todos nós podemos ter múltiplos teclados, mouse e monitores para cada máquina; provavelmente nem queremos ter. Obviamente, hardware năo é a soluçăo. Sobra para o software, e o Linux se dá bem nesse caso, oferecendo "terminais virtuais", ou "VTs".
Pressionando Alt e uma tecla de funçăo, vocę pode alternar entre os terminais virtuais; cada tecla de funçăo corresponde a um deles. Por padrăo, o Slackware tem logins em 6 terminais virtuais. Alt+F2 te leva ao segundo, Alt+F3 ao terceiro, etc.
O restante das teclas de funçăo săo reservadas para sessőes do X. Cada sessăo do X usa seu próprio VT, começando pelo sétimo (Alt+F7) e assim por diante. No X, a combinaçăo Alt+Tecla de Funçăo é substituída por Ctrl+Alt+Tecla de Funçăo; assim, se estiver no X e quiser voltar a um console de texto (sem sair de sua sessăo no X), Ctrl+Alt+F3 te levará ao terceiro terminal virtual. (Alt+F7 te leva de volta ŕ primeira sessăo do X.)
E quanto ŕs situaçőes onde năo há terminais virtuais? E entăo? Felizmente, o Slackware inclui um belo gerenciador de tela oportunamente chamado de screen. O screen é um emulador de terminal que possui capacidades semelhantes ŕs de um terminal virtual. Ao executar o screen, uma breve apresentaçăo aparece, entăo um terminal abre. Diferentemente dos terminais virtuais padrăo, o screen possui seus próprios comandos. Todos os comandos do screen săo precedidos por Crtl+A. Por exemplo, Ctrl+A+C cria uma nova sessăo do terminal. Ctrl+A+N alterna para o próximo terminal. Ctrl+A+P alterna para o terminal anterior.
O screen também permite sair e retornar a sessőes do screen, o que é especialmente útil em sessőes remotas por ssh e telnet, (maiores detalhes abaixo). Ctrl+A+D sai da tela atualmente em execuçăo. O comando screen -r relaciona todas as sessőes atuais do screen ŕs quais vocę pode retornar.
$ screen -r
There are several suitable screens on:
1212.pts-1.redtail(Detached)
1195.pts-1.redtail(Detached)
1225.pts-1.redtail(Detached)
17146.pts-1.sanctuary (Dead ???)
Remove dead screens with 'screen -wipe'.
Type "screen [-d] -r [pid.]tty.host" to resume one of them.
O comando screen -r 1212 retorna ŕ primeira sessăo listada. Mencionei anteriormente que isso era útil para sessőes remotas. Se eu tivesse logado em um servidor Slackware remoto por ssh, e a minha conexăo caísse pro algum motivo como falta de energia local, o que quer que eu estivesse fazendo naquele momento seria perdido instantaneamente, o que pode ser terrível para o seu servidor. Usar o screen evita isso, desconectando a minha sessăo se a minha conexăo cair. Assim que a minha conexăo for restaurada, posso retornar ŕ minha sessăo do screen e reiniciar exatamente de onde parei.
Nós já discutimos previamente sobre a estrutura de diretórios no Slackware Linux. A partir deste ponto, vocę está apto a encontrar arquivos e diretórios que precisar. Porém, há mais sobre sistemas de arquivos que apenas a estrutura de diretórios.
O Linux é um sistema operacional multi-usuário. Todo o aspecto do sistema é multiusuário, inclusive o sistema de arquivos. O sistema armazena informaçőes sobre quem possui um arquivo e quem pode ler este arquivo. Existem outras partes únicas sobre o sistema de arquivos, como os links e a montagem de partiçőes NFS. Essa seçăo explica tudo isso, tăo bem quanto os aspectos multi-usuário do sistema de arquivos.
O sistema de arquivos armazena informaçőes sobre o dono de cada arquivo e diretório no sistema. Isso inclui qual usuário e grupo possui um determinado arquivo. A maneira mais fácil de ver essa informaçăo é com o comando ls:
$ ls -l /usr/bin/wc
-rwxr-xr-x 1 root bin 7368 Jul 30 1999 /usr/bin/wc
Nós estamos interessados na terceira e quarta colunas (da esquerda para a direita). Essas colunas contém o nome do usuário e grupo que possui o arquivo. Nós podemos ver que o usuário "root" e o grupo "bin" săo os proprietários desse arquivo.
"Nós podemos mudar facilmente os donos de um arquivo com os comandos chown(1) (que significa mudar o proprietário") e chgrp(1) (que significa "mudar o grupo"). Para mudar o dono de um arquivo para daemon, nós podemos usar o comando chown:
# chown daemon /usr/bin/wc
Para mudar o grupo que possui um arquivo para "root", nós podemos usar o comando chgrp:
# chgrp root /usr/bin/wc
Nós podemos utilizar o comando chown para especificar as propriedades de usuário e grupo para um arquivo:
# chown daemon:root /usr/bin/wc
No exemplo acima, o usuário poderia ter usado um ponto, no lugar do dois-pontos. O resultado teria sido o mesmo; entretanto, o dois-pontos é considerado a melhor forma. O uso do ponto é obsoleto e poderá ser removido em futuras versőes do comando chown para permitir nomes de usuários que contenham ponto. Esses nomes de usuário tendem a ser muito populares com Servidores Windows Exchange e săo encontrados com maior freqüęncia em endereços de e-mail como: <mr jones (a) example com>. No Slackware, os administradores săo alertados para evitarem esses nomes de usuários, porque alguns scripts utilizam o ponto para indicar o nome e o grupo de um arquivo ou diretório. Em nosso exemplo, o comando chmod interpretaria mr.jones como usuário "mr" e grupo "jones".
A definiçăo de quem é o dono de um determinado arquivo é uma parte muito importante na utilizaçăo de um sistema Linux, mesmo que vocę seja o único usuário do sistema. Algumas vezes vocę precisa corrigir as propriedades em arquivos e em nós de dispositivos (device nodes).
As permissőes săo outra parte importante do aspecto multi-usuário do sistema de arquivos. Com elas, vocę pode alterar quem lę, escreve, e executa arquivos.
A informaçăo de permissăo é armazenada na forma de quatro dígitos octais, cada um especificando diferentes conjuntos de permissőes. Săo eles, permissăo do proprietário, permissăo de grupo e, permissăo do mundo. Os quatro dígitos octais săo utilizados para armazenar informaçőes especiais como identificaçăo de usuário (user ID), identificaçăo de grupo (group ID), e o bit controle. Os valores octais associados aos modos de permissăo săo (eles possuem letras associadas que săo mostradas por programas como o comando ls e podem ser utilizadas pelo comando chmod):
Valores de Permissăo Octais
| Tipo de Permissăo | Valor Octal | Valor Letra |
| "bit" controle | 1 | t |
| identificaçăo de usuário | 4 | s |
| identificaçăo de grupo | 2 | s |
| leitura | 4 | r |
| escrita | 2 | w |
| execuçăo | 1 | x |
Vocę adiciona os valores octais para cada grupo de permissőes. Por exemplo, se vocę quer que o grupo tenha permissăo de "leitura" e "escrita", vocę utilizará "6" na porçăo referente ŕ permissăo do grupo.
As permissőes padrőes do bash săo:
$ ls -l /bin/bash
-rwxr-xr-x 1 root bin 477692 Mar 21 19:57 /bin/bash
O primeiro traço pode ser substituído por um "d" se for um diretório. As tręs permissőes de grupo (proprietário, grupo, e outros) săo mostradas a seguir. Nós vemos que o proprietário possui permissőes de leitura, escrita e execuçăo (rwx). O grupo possui apenas permissăo de leitura e execuçăo (r-x). E todo o mundo possui permissőes de leitura e escrita (r-x).
Como nós configuramos as permissőes de um outro arquivo para que elas fiquem semelhantes as permissőes do bash? Primeiro, vamos criar um arquivo chamado exemplo:
$ touch /tmp/exemplo
$ ls -l /tmp/exemplo
-rw-rw-r--- 1 david users 0 Apr 19 11:21 /tmp/exemplo
Nós usaremos o comando chmod(1) (que significa "mudar o modo") para alterar as permissőes do arquivo exemplo. Acrescente os números octais para a permissăo que vocę quer. Para o proprietário que possui permissăo de leitura, escrita e execuçăo, nós teríamos o valor 7. Para permissăo de leitura e execuçăo teríamos o valor 5. Aplique esses valores juntos ao chmod dessa maneira:
$ chmod 755 /tmp/exemplo
$ ls -l /tmp/exemplo
-rwxr-xr-x 1 david users 0 Apr 19 11:21 /tmp/exemplo
Agora vocę deve estar pensando, "Por que nós năo criamos o arquivo com essas permissőes desde o início?" Bem, a resposta é simples. O bash possui uma implementaçăo chamada umask. Este comando vem incluído com a maioria dos shells do Unix, e controla quais permissőes săo designadas ŕ arquivos criados recentemente. Nós discutimos sobre as implementaçőes do bash com maior profundidade na seçăo 8.3.1. O comando umask é utilizado de forma razoável. Ele funciona de maneira bastante similar ao chmod, só que em modo reverso. Vocę especifica os valores octais que vocę năo deseja que estejam presentes nos arquivos recém-criados. O seu valor padrăo é 0022.
$ umask
0022
$ umask 0077
$ touch tempfile
$ ls -l tempfile
-rw-------- 1 david users 0 Apr 19 11:21 tempfile
Olhe a página do manual do bash para maiores informaçőes.
Para aplicar permissőes especiais com o chmod, adicione os números juntos e identifique-os na primeira coluna. Por exemplo, para forçar a identificaçăo do usuário (user ID) e a identificaçăo de grupo (group ID), nós usamos o 6 na primeira coluna:
$ chmod 6755 /tmp/exemplo
$ ls -l /tmp/exemplo
-rwsr-sr-x 1 david users 0 Apr 19 11:21 /tmp/exemplo
Se os valores octais confundem vocę, vocę pode usar letras com o chmod. Os grupos de permissăo săo representados como:
| Proprietário | u |
| Grupo | g |
| Mundo | o |
| Todas acima | a |
Para fazer o descrito acima, nós precisamos utilizar várias linhas de comando:
$ chmod a+rx /tmp/exemplo
$ chmod u+w /tmp/exemplo
$ chmod ug+s /tmp/exemplo
Algumas pessoas preferem utilizar as letras em vez dos números. Ambas as maneiras irăo gerar o mesmo resultado na aplicaçăo das permissőes.
O formato octal é freqüentemente mais rápido, e o que vocę vę frequentemente sendo utilizado em shell script. Em alguns casos as letras săo mais poderosas. Por exemplo, năo existe uma maneira fácil de alterar um grupo de permissőes e preservar outros em arquivos e diretórios, quando vocę usa o formato octal. Isso é trivial utilizando as letras.
$ ls -l /tmp/
-rwxr-xr-x 1 alan users 0 Apr 19 11:21 /tmp/exemplo0
-rwxr-x--- 1 alan users 0 Apr 19 11:21 /tmp/exemplo1
----r-xr-x 1 alan users 0 Apr 19 11:21 /tmp/exemplo2
$ chmod g-rwx /tmp/exemplo
-rwx---r-x 1 alan users 0 Apr 19 11:21 /tmp/exemplo0
-rwx------ 1 alan users 0 Apr 19 11:21 /tmp/exemplo1
-------r-x 1 alan users 0 Apr 19 11:21 /tmp/exemplo2
Nós mencionamos as permissőes de identificaçăo de usuário (user ID) e a identificaçăo de grupo (group ID) em várias partes acima. Vocę pode estar se perguntando o que săo essas permissőes. Normalmente, quando vocę roda um programa, este está operando sob a sua conta de usuário. Isto é, ele tem todas as permissőes que o seu usuário possui. O mesmo é verdade para o grupo. Quando vocę roda um programa, ele é executado sob o seu grupo atual. Com a permissăo de identificaçăo de usuário, vocę pode forçar o programa para sempre rodar como o proprietário do programa (como o "root"). A permissăo de identificaçăo de grupo faz a mesma coisa, só que para o grupo.
Seja cuidadoso com isso, pois as permissőes de identificaçőes de usuário e de grupo dos programas podem abrir brechas de segurança no seu sistema. Se vocę freqüentemente força as permissőes de usuário para os programas que pertencem ao usuário root, vocę está permitindo que qualquer um utilize o programa e o utilize como root. Como o usuário root năo possui restriçőes no sistema, vocę pode ver como isso cria um grande problema de segurança. Resumindo, năo é ruim utilizar as permissőes de identificaçăo de usuário e de grupo, apenas use o bom senso.
Links săo ponteiros entre arquivos. Com os links, vocę pode ter arquivos existindo em vários locais e podendo ser acessados por vários nomes. Existem dois tipos de links: estáticos e dinâmicos.
Links estáticos săo nomes para um arquivo em particular. Eles só podem existir dentro de um único sistema de arquivos e só săo removidos quando o nome real é removido do sistema. Eles săo úteis em alguns casos, porém muitos usuários acham o link dinâmico muito mais versátil.
O link dinâmico, também chamado de link simbólico, pode apontar para um arquivo fora do seu sistema de arquivos. Ele é na verdade um pequeno arquivo contendo apenas as informaçőes que ele necessita. Vocę pode adicionar ou remover links simbólicos sem afetar o arquivo atual. E desde que um link simbólico é na verdade um arquivo pequeno contendo sua própria informaçăo, ele também pode apontar para um diretório. É bastante comum ver o /var/tmp atualmente como um link simbólico para /tmp por exemplo.
Os links năo possuem seu próprio conjunto de permissőes ou propriedades, porém refletem os arquivos aos quais eles apontam. Os usuários do Slackware usam mais os links dinâmicos. Aqui está um exemplo comum:
$ ls -l /bin/sh
lrwxrwxrwx 1 root root 4 Apr 6 12:34 /bin/sh -> bash
O shell sh sob o Slackware é atualmente o bash. A remoçăo de links é feita utilizando o comando rm. O comando ln é utilizado para criar links. Esses comandos serăo discutidos com maior profundidade no Capítulo 10.
É muito importante ter cuidado, em particular, com os links simbólicos. Uma vez, eu estava trabalhando em uma máquina que teimava em falhar nos backups em fita toda noite. Dois links simbólicos tinham sido feitos para dois diretórios, um embaixo do outro. O software para backup manteve anexado ŕ fita esses mesmos diretórios, até ficar sem espaço. Normalmente, uma série de verificaçőes prévias irá prever a criaçăo de links simbólicos nessa situaçăo, mas o nosso era um caso especial.
Como foi préviamente discutido na seçăo 4.1.1, todos os drives e dispositivos em seu computador săo um sistema de arquivos enorme. Várias partiçőes em seu disco rígido, CD-ROMs, e disquetes săo todos alocados em uma mesma árvore. Ao anexar todos esses drives ao sistema de arquivos para que possam ser acessados, vocę precisa utilizar os comandos mount(1) e umount(1).
Alguns dispositivos săo montados automaticamente quando vocę inicializa o seu computador. Esses dispositivos estăo listados no arquivo /etc/fstab. Tudo o que vocę quiser que seja montado automaticamente precisa ter uma entrada neste arquivo. Para os outros dispositivos, vocę terá que executar um comando toda vez que vocę quiser montar um dispositivo.
Vamos dar uma olhada em um exemplo do arquivo /etc/fstab:
$ cat /etc/fstab
/dev/sda1 / ext2 defaults 1 1
/dev/sda2 /usr/local ext2 defaults 1 1
/dev/sda4 /home ext2 defaults 1 1
/dev/sdb1 swap swap defaults 0 0
/dev/sdb3 /export ext2 defaults 1 1
none /dev/pts devpts gid=5,mode=620 0 0
none /proc proc defaults 0 0
/dev/fd0 /mnt ext2 defaults 0 0
/dev/cdrom/mnt/cdrom iso9660 ro 0 0
A primeira coluna é o nome do dispositivo. Nesse caso, os dispositivos săo cinco partiçőes espalhadas por dois discos rígidos SCSI, dois sistemas de arquivos que năo precisam de dispositivos, um drive de disquete, e um drive de CD-ROM. A segunda coluna informa aonde o dispositivo será montado. Esse deve ser o nome de um diretório, com exceçăo no caso de uma partiçăo swap. A terceira coluna é o tipo de sistema de arquivo do dispositivo. Para os sistemas de arquivos normais do Linux, estes serăo ext2 (segundo sistema de arquivos extendido). Drives de CD-ROM săo iso9660, e dispositivos baseados no Windows serăo do tipo msdos ou vfat.
A quarta coluna é uma listagem de opçőes que se aplicam ao sistema de arquivos montado. O padrăo (defaults) pode ser usado sem problemas com quase todos os dispositivos. Entretanto, para dispositivos de somente leitura vocę deve colocar a opçăo ro. Existem muitas opçőes que podem ser utilizadas. Verifique o manual do fstab(5) para maiores informaçőes. As duas últimas colunas săo utilizadas para o fsck e outros comandos que precisam manipular os dispositivos. Verifique o manual para essas informaçőes.
Quando vocę instala o Slackware Linux, o programa de instalaçăo irá criar a maior parte do arquivo fstab.
Anexar outro dispositivo ao seu sistema de arquivos é fácil. Tudo o que vocę tem que fazer é utilizar o comando mount, com algumas opçőes. Utilizar o comando mount pode ser mais simples se o dispositivo possui uma entrada no arquivo /etc/fstab. Por exemplo, vamos dizer que eu queira montar o meu driver de CD-ROM e o arquivo fstab se parece com o exemplo citado na seçăo anterior. Eu poderia utilizar o comando mount desta forma:
$ mount /cdrom
Desde que haja uma entrada no arquivo fstab para esse ponto de montagem, o comando mount sabe quais opçőes utilizar. Caso năo haja uma entrada para este dispositivo, eu terei de utilizar muitas opçőes junto ao comando mount:
$ mount -t iso9660 -o ro /dev/cdrom /cdrom
Esta linha de comando inclui a mesma informaçăo que o exemplo do fstab tinha, mesmo assim nós iremos explicar todas as partes do comando. A opçăo <option>-t iso9660</option> é o tipo de sistema de arquivos do dispositivo a ser montado. Neste caso, ele seria o sistema de arquivos iso9660, que é usado normalmente pelos drivers de CD-ROM. A opçăo <option>-o ro</option> diz ao comando para montar o dispositivo com capacidade para apenas efetuar leituras. O caminho /dev/cdrom é o nome do dispositivo a ser montado, e o diretório /cdrom é o local no sistema de arquivos onde o drive será montado.
Antes que vocę possa remover um disquete, CD-ROM, ou outro dispositivo removível, que esteja atualmente montado, vocę terá que desmontá-lo. Isto é feito utilizando o comando umount. Năo pergunte para onde o "n" foi porque nós năo poderíamos te contar. Vocę pode utilizar, tanto o caminho para o dispositivo montado quanto o ponto de montagem, como argumento para o comando umount. Por exemplo, se vocę quer desmontar o CD-ROM do exemplo anterior, ambos os comandos podem ser utilizados:
# umount /dev/cdrom
# umount /cdrom
NFS significa Network Filesystem (Sistema de arquivos de rede). Ele năo é realmente parte do sistema de arquivos real, mas pode ser utilizado para adicionar partes ao sistema de arquivos montado.
Ambientes Unix enormes, algumas vezes, precisam compartilhar os mesmos programas, conjuntos de diretórios de usuários, e o repositório de e-mail. O problema de pegar a mesma cópia para cada máquina é resolvido pelo NFS. Nós podemos utilizar o NFS para compartilhar um conjunto de diretórios de usuários entre todas as estaçőes de trabalho. Entăo as estaçőes de trabalho montam o diretório que o NFS compartilhou como se estivesse nas suas próprias máquinas.
Veja a seçăo 5.6.2 e as páginas do manual para exports(5), nfsd(8), e mountd(8) para maiores informaçőes.
O Linux tenta ser o mais parecido com o Unix possível.Tradicionalmente, os sistemas operacionais Unix tem sido orientados pela linha de comando. É claro que temos uma interface gráfica no Slackware, mas a linha de comando é ainda o principal nível de controle do sistema. Portanto, é importante entender alguns dos comandos básicos dos comandos de gerenciamento de arquivos.
A seçăo a seguir explica os comandos corriqueiros do gerenciamento de arquivos e provę exemplos de como eles săo usados. Existem muitos outros comandos, mas estes irăo ajudar vocę a começar. Além disso, os comandos estăo explicados resumidamente. Vocę encontrará mais detalhes nas man pages de cada comando.
Esse comando lista arquivos em um diretório. Usuários DOS e Windows irăo notar a similaridade com o comando dir. Ele mesmo, ls(1) irá listar os arquivos no diretório atual. Para ver o que existe em seu diretório raiz, vocę poderia usar esses comandos:
$ cd /
$ ls
bin cdr dev home lost+found proc sbin tmp var
boot cdrom etc lib mnt root suncd usr vmlinuz
O problema que muita gente tem com a saída, do comando anterior, é que năo se pode dizer facilmente o que é um diretório e o que é um arquivo. Alguns usuários preferem o ls adicionado a um identificador para cada listagem, como essa:
$ ls -FC
bin/ cdr/ dev/ home/ lost+found/ proc/ sbin/ tmp/ var/
boot/ cdrom/ etc/ lib/ mnt/ root/ suncd/ usr/ vmlinuz
Diretórios tęm uma barra (/) no final do nome, arquivos executáveis tęm um asterisco no final do nome, e assim por diante.
O ls pode também ser usado para conseguir outras informaçőes nos arquivos. Por exemplo, para ver a data de criaçăo, proprietário, e permissőes, vocę especificaria uma lista longa:
$ ls -l
drwxr-xr-x 2 root bin 4096 May 7 09:11 bin/
drwxr-xr-x 2 root root 4096 Feb 24 03:55 boot/
drwxr-xr-x 2 root root 4096 Feb 18 01:10 cdr/
drwxr-xr-x 14 root root 6144 Oct 23 18:37 cdrom/
drwxr-xr-x 4 root root 28672 Mar 5 18:01 dev/
drwxr-xr-x 10 root root 4096 Mar 8 03:32 etc/
drwxr-xr-x 8 root root 4096 Mar 8 03:31 home/
drwxr-xr-x 3 root root 4096 Jan 23 21:29 lib/
drwxr-xr-x 2 root root 16384 Nov 1 08:53 lost+found/
drwxr-xr-x 2 root root 4096 Oct 6 12:47 mnt/
dr-xr-xr-x 62 root root 0 Mar 4 15:32 proc/
drwxr-x--x 12 root root 4096 Feb 26 02:06 root/
drwxr-xr-x 2 root bin 4096 Feb 17 02:02 sbin/
drwxr-xr-x 5 root root 2048 Oct 25 10:51 suncd/
drwxrwxrwt 4 root root 487424 Mar 7 20:42 tmp/
drwxr-xr-x 21 root root 4096 Aug 24 03:04 usr/
drwxr-xr-x 18 root root 4096 Mar 8 03:32 var/
Suponhamos que vocę queira uma lista dos arquivos ocultos no diretório atual.O comando seguinte listaria isso.
$ ls -a
. bin cdrom home mnt sbin usr
.. boot dev lib proc suncd var
.pwrchute_tmp cdr etc lost+found root tmp vmlinuz
Arquivos començando com um ponto (chamados de arquivos ponto) săo ocultados quando vocę executa o ls. Vocę somente verá esses arquivos se passar a opçăo -a.
Existem muitas outras opçőes que podem ser encontradas nos manuais online. Năo esqueça que pode combinar as opçőes que vocę passa para o ls.
O comando cd é usado para mudar o diretório de trabalho. Vocę simplesmente digita cd seguido do nome do caminho para mudar. Aqui estăo alguns exemplos:
darkstar:~$ cd /bin
darkstar:/bin$ cd usr
bash: cd: usr: No such file or directory
darkstar:/bin$ cd /usr
darkstar:/usr$ ls
bin
darkstar:/usr$ cd bin
darkstar:/usr/bin$
Note que sem começar com a barra (/) ele tenta mudar para um diretório no diretório atual. Também executando o cd sem nenhuma opçăo moverá vocę para o seu diretório pessoal.
O comando cd năo é igual a outros comandos. Ele é um comando integrado do shell. Comandos integrados do shell serăo discutidos na seçăo 8.3.1. Isso pode năo fazer nenhum sentido pra vocę agora. Basicamente isso significa que năo existe man page para esse comando. Ao invés disso, vocę tem que usar o help do shell. Como segue:
$ help cd
Serăo mostradas as opçőes para o cd e como usá-las.
O comando pwd é usado para mostrar a sua localizaçăo atual. Para usar o comando pwd basta digitar pwd. Por exemplo:
$ cd /bin
$ pwd
/bin
$ cd /usr
$ cd bin
$ pwd
/usr/bin
more (1) é como chamamos um utilitário de paginaçăo. Muitas vezes a saída de um comando em particular é muito grande para caber em apenas uma tela. Os comandos individualmente năo sabem como fazer caber as saídas em telas separadas. Eles deixam esse trabalho para os paginadores. O comando more quebra a saída numa tela única e espera que vocę pressione a barra de espaços antes de continuar na próxima página. Pressionando a tecla enter irá avançar a saída em uma linha. Aqui segue um bom exemplo:
$ cd /usr/bin
$ ls -l
Isso deveria rolar a tela um pouco. Para parar a saída tela por tela, pipe ( | ) seguido do more:
$ ls -l | more
Esse é o caractere pipe (shift + \). O pipe é: pegue a saída do ls e alimente o more. Vocę pode "pipar" qualquer coisa através do comando more, năo apenas o ls. Pipe é também visto na seçăo 8.2.3.
O comando more é mais simples, mas năo permite que vocę volte para uma página já exibida. O more năo provę um jeito de vocę voltar. O comando less (1) prove essa funcionalidade. Ele é usado do mesmo jeito que o comando more, entăo o exemplo anterior serve aqui também. Entăo, o less é mais que o more. Just Krammer define esses comandos com o seguinte trocadilho:
"less is more, but more more than more is, so more is less less, so use more less if you want less more."
Onde more e o less năo conseguem ir, o most (1) vai além. Se less é mais do que more, most é mais do que less. Enquanto os outros paginadores podem apenas mostrar um arquivo por vez, most é capaz de vizualizar qualquer número de arquivos, até que cada janela de arquivo tenha pelo menos duas linhas aparecendo. O comando most tem muitas opçőes, confira as páginas de manual para mais detalhes.
cat (1) é a abreviaçăo de concatenar. Ele foi originalmente desenhado para mesclar arquivos de textos em outro, mas pode ser usado em muitos outros propósitos. Para mesclar dois ou mais arquivos em um, vocę simplesmente lista os arquivos depois do comando cat e entăo redireciona a saída para um novo arquivo. O comando cat funciona com entrada padrăo e saída padrăo, entăo vocę deve usar os caracteres de redirecionamento do shell. Por exemplo:
$ cat file1 file2 file3 > bigfile
Esse comando pega o conteúdo dos arquivos file1, file2, e file3 e mescla. A nova saída é enviada para a saída padrăo.
O comando cat também pode ser usado para exibir arquivos. Muitas pessoas usam o cat em arquivos de textos junto com os comandos more ou less, como segue:
$ cat file1 | more
Esse comando irá mostrar o arquivo file1 e "pipá-lo" através do comando more para que vocę apenas veja uma tela por vez. Outro uso comum para o cat é copiar arquivos. Vocę pode copiar qualquer arquivo usando o cat, como segue:
$ cat /bin/bash > ~/mybash
O programa /bin/bash é copiado para o seu diretório /home e nomeado como mybash.
O comando cat tem muitos usos e os mostrados aqui săo apenas alguns. Desde que o cat faz uso extensivo de entradas e saídas padrăo, ele é ideal para usar em scripts shell ou parte de outros comandos complexos.
O comando echo (1) mostra o texto especificado na tela. Vocę precisa especificar a string que vai ser mostrada depois do comando. Por padrăo o comando echo irá mostrar a string e imprimir a nova linha de caracteres depois dele. Vocę pode passar a opçăo -n para suprimir a impressăo de uma nova linha. A opçăo -e vai causar a procura por caracteres escape na string e executá-las.
O comando touch é usado para mudar a data de um arquivo. Vocę pode mudar a data de acesso e a data de modificaçăo com esse comando. Se o arquivo especificado năo existir, o comando touch criará um arquivo vazio. Para marcar um arquivo com a data atual, vocę poderia usar esse comando:
$ ls -al file1
-rw-r--r-- 1 root root 9779 Feb 7 21:41 file1
$ touch file1
$ ls -al file1
-rw-r--r-- 1 root root 9779 Feb 8 09:17 file1
Existem muitas outras opçőes para o comando touch para especificar qual data que vocę quer modificar, qual hora usar, e muitas outras opçőes.A man-page mostra isso em detalhes.
O comando mkdir irá criar um novo diretório. Vocę simplesmente especifica o diretório a ser criado quando vocę executa o mkdir. Esse exemplo criará o diretório hejaz no diretório atual.
$ mkdir hejaz
Vocę também pode especificar o caminho, como segue:
$ mkdir /usr/local/hejaz
A opçăo -p irá dizer ao mkdir para criar qualquer diretório pai. O exemplo acima falhará se /usr/local năo existir. A opçăo -p irá criar /usr/local e /usr/local/hejaz:
$ mkdir -p /usr/local/hejaz
O comando cp (1) copia arquivos. Usuários do DOS irăo notar a similaridade com o comando copy. Existem muitas opçőes para o comando cp, entăo vocę deve dar uma olhada na páginal de manual antes de usá-lo.
Um uso comum é usar o cp para copiar um arquivo de uma localizaçăo para outra. Por exemplo:
$ cp hejaz /tmp
Isso copia o arquivo hejaz do diretório atual para o diretório /tmp.
Muitos usuários preferem manter a data do arquivo, para isso:
$ cp -a hejaz /tmp
Isso assegura que a data năo será modificada na cópia.
Para cópia recursiva do conteúdo de um diretório para outro, vocę usaria esse comando:
$ cp -R mydir /tmp
Isso copiará o diretório mydir para o diretório /tmp.
Também se vocę quiser copiar um diretório ou um arquivo e mante-lo com as permissőes antigas, datas e deixa-lo exatamente o mesmo, use o comando cp -p.
$ ls -l file
-rw-r--r-- 1 root vlad 4 Jan 1 15:27 file
$ cp -p file /tmp
$ ls -l /tmp/file
-rw-r--r-- 1 root vlad 4 Jan 1 15:27 file
O comando cp tem muitas outras opçőes que săo mostradas em detalhes nas páginas de manual.
O comando mv (1) move os arquivos de um lugar para outro. Simples o bastante, năo?
$ mv oldfile /tmp/newfile
O comando mv tem poucas opçőes na linha de comando que săo detalhadas nas páginas de manual Na prática, o comando mv é raramente usado com opçőes de linha de comando.
O comando rm (1) remove arquivos e árvores de diretório.
Os usuários do DOS notarăo em ambos a similaridade com os comandos del e o deltree.
O comando rm pode ser muito perigoso se vocę năo se cuidar. Enquanto as vezes é possível recuperar um arquivo removido, isso pode ser uma tarefa complicada (e certamente cara) além de estar fora do escopo desse livro.
Para remover um único arquivo, especifique o nome dele quando vocę executar o rm:
$ rm file1
Se o arquivo tiver as permissőes de gravaçăo, vocę poderá ter uma mensagem de erro de permissăo negada. Para forçar a remoçăo do arquivo năo importando com nada, passe a opçăo -f, como segue:
$ rm -f file1
Para remover um diretório inteiro, vocę pode usar o -r e o -f juntos. Esse é um bom exemplo de como remover conteúdos inteiros do seu hd. Vocę realmente năo quer fazer isso. Mas existe um comando mesmo assim:
# rm -rf /
Seja cauteloso com o comando rm; vocę pode atirar no seu próprio pé. Existem várias opçőes na linha de comando, que săo discutidas nas páginas de manual.
O comando rmdir (1) remove diretórios do sistema de arquivos. O diretório deve estar vazio antes de poder ser removido. A síntaxe é simples:
$ rmdir <directory>
Esse exemplo irá remover o subdiretório hejaz no diretório atual:
$ rmdir hejaz
Se esse diretório năo existir, o rmdir dirá a vocę. Vocę também pode especificar um caminho completo de um diretório a ser removido, como esse exemplo mostra:
$ rmdir /tmp/hejaz
Esse exemplo irá tentar remover o diretório hejaz dentro do diretório /tmp.
Vocę também pode remover um diretório e todos os diretórios pai passando a opçăo -p.
$ rmdir -p /tmp/hejaz
Isso primeiro irá tentar remover o diretório hejaz dentro do /tmp. Caso tenha sucesso, ele irá tentar remover o /tmp. O comando rmdir irá continuar isso até ocorrer um erro ou até que a árvore especificada seja removida.
O comando ln (1) é usado para criar links entre arquivos. Esses links podem ser hard links ou links simbólicos. A diferença entre os dois tipos de links serăo discutidos na seçăo 9.3. Se vocę quiser fazer um link simbólico do diretório /var/media/mp3 e colocar esse link no seu diretório home, vocę faria isso:
$ ln -s /var/media/mp3 ~/mp3
A opçăo -s diz para o ln fazer um link simbólico. A próxima opçăo é o caminho do link, e a opçăo final é como chamar o link. Nesse caso, o comando apenas irá criar um arquivo chamado mp3 no seu diretório home que aponta para o /var/media/mp3. Vocę pode chamar o link do que vocę quiser apenas mudando a última opçăo.
Fazer um hard link é tăo fácil quanto. Tudo que vocę tem que fazer é tirar a opçăo -s. Hard links normalmente năo podem se referir a diretórios ou sistema de arquivos. Para criar um hard link de /usr/bin/email para /usr/bin/mutt, apenas digite o trecho a seguir:
# ln /usr/bin/mutt /usr/bin/email
Cada programa que está sendo executado é chamado de processo. Estes processos văo desde o ambiente gráfico X até programas de sistema (chamados "daemons") que săo iniciados durante o boot do computador. Cada processo pertence a um usuário em particular. Processos que săo iniciados no boot geralmente săo executados como usuário root ou nobody. Processos que vocę inicia pertencerăo ao seu usuário. Processo iniciados por outros usuários pertencerăo a eles.
Vocę tem controle sobre todos os processos iniciados por vocę. Adicionalmente, o usuário root tem controle sobre todos os processo do sistema, incluindo aqueles iniciados por outros usuários. Processos podem ser controlados e monitorados através de vários programas, bem como de comandos do shell.
Os programas iniciados ŕ partir da linha de comando săo executados em primeiro plano (foreground). Isto permite ver toda a saída do programa e interagir com ele. Entretanto há diversas situaçőes em que será necessário executar o programa sem que o terminal fique preso ŕ sua execuçăo. Chamamos isso de executar o programa em segundo plano, e há várias maneiras de fazę-lo.
A primeira maneira de se colocar um processo em segundo plano é adicionando o ę comercial (&) ŕ linha de comando quando vocę iniciar o programa. Por exemplo, digamos que vocę queira usar o amp, um mp3 player da linha de comando, para tocar um diretório cheio de arquivos mp3, mas vocę precisará utilizar o mesmo terminal para executar outros comandos. A seguinte linha de comando irá iniciar o programa amp em segundo plano:
$ amp *.mp3 &
O programa será executado normalmente e vocę retornará ao prompt de comando.
Outra maneira de colocar um processo em segundo plano é fazę-lo durante a sua execuçăo. Primeiro, inicie um programa. Durante sua execuçăo, pressione Control+z. Isso suspenderá o processo. Suspender um processo significa pausar a sua execuçăo. Ele momentaneamente pára de rodar, mas pode ser iniciado novamente a qualquer momento. Uma vez suspenso o processo, vocę retorna ao prompt de comando. Vocę inicia o processo suspenso em segundo plano digitando:
$ bg
Agora o processo suspenso está rodando em segundo plano.
Se vocę necessitar interagir com um processo em segundo plano, é possível trazę-lo para primeiro plano. Se existe apenas um processo em segundo plano, vocę pode trazę-lo de volta digitando:
$ fg
Se o programa ainda năo terminou sua execuçăo, entăo ele tomará o terminal e vocę năo terá mais acesso ao prompt de comando. Algumas vezes o programa terminará sua execuçăo enquanto estiver em segundo plano. Neste caso, vocę receberá uma mensagem como esta:
[1]+ Done /bin/ls $LS_OPTIONS
Informando que o processo em segundo plano (neste caso o ls - que năo é um exemplo muito interessante) foi terminado.
É possível ter vários processos em segundo plano de uma só vez. Quando isto acontece, será necessário saber qual processo vocę deseja trazer para o primeiro plano. Apenas digitando fg trará para o primeiro plano o último processo que foi colocado em segundo plano. E se vocę tiver uma lista enorme de processos em segundo plano? Por sorte, o bash possui um comando para listar esses processos. Ele é o jobs e o seu resultado é:
$ jobs
[1] Stopped vim
[2]- Stopped amp
[3]+ Stopped man ps
Isto mostra uma lista de todos os processos que estăo em segundo plano. Como vocę pode ver, todos estăo parados. Isto significa que os processos estăo suspensos. O número é um tipo de ID para todos os processos em segundo plano. O ID seguido de um sinal de adiçăo (man ps) é o processo que será trazido para primeiro plano se vocę apenas digitar fg.
Se quiser trazer para primeiro plano o vim, vocę deve digitar:
$ fg 1
e o vim rapidamente retornará ŕ console. Enviar processos para o segundo plano pode ser muito útil se vocę tiver apenas um terminal aberto em uma conexăo discada. Será possível executar diversos programas naquele único terminal, periodicamente alternando entre eles.
Agora vocę sabe alternar entre vários processos iniciados ŕ partir da linha de comando. Sabe também que existem muitos processos em execuçăo todo o tempo. Mas entăo como listar todos esses programas? Bem, vocę pode utilizar o comando ps(1). Este comando tem uma porçăo de opçőes, mas iremos apresentar apenas algumas das mais importantes. Para uma listagem completa, veja as páginas de manual do ps. Sobre as páginas de manual veja detalhes em Seçőes das páginas de Manual.
Apenas digitando ps vocę terá uma lista dos programas em execuçăo no seu terminal. Isto inclui os processos em primeiro plano (incluindo aí qualquer shell que vocę esteja usando e, é claro, o próprio ps). Também săo listados os processos que vocę está executando em segundo plano. Muitas vezes essa lista será bem curta:
Resultado padrăo do ps
$ ps
PID TTY TIME CMD
7923 ttyp0 00:00:00 bash
8059 ttyp0 00:00:00 ps
Embora năo sejam muitos processos, a informaçăo é interessante. Vocę terá as mesmas colunas usando o ps sem parâmetros, năo importa quantos processos estejam em execuçăo. Entăo, o que significa tudo aquilo?
Bem, o PID é o ID do processo. Todos os processos em execuçăo tęm um identificador único que vai de 1 até 32767. Para cada processo é atribuído o próximo PID livre. Quando um processo é finalizado (ou interrompido, como vocę verá na próxima seçăo), ele libera o PID. Quando o PID máximo é alcançado, o próximo será o menor valor que estiver livre.
A coluna TTY indica em qual terminal o processo está sendo executado. Executando o ps sem parâmetros serăo listados apenas os programas em execuçăo no terminal corrente, entăo todos os processos terăo a mesma informaçăo na coluna TTY. Como vocę pode ver, ambos processos listados săo executados em ttyp0. Isso indica que estăo sendo executados remotamente ou a partir de alguma variedade de terminal X.
A coluna TIME indica quanto tempo de CPU o processo tem consumido. Isso é diferente do tempo gasto para execuçăo do processo. Lembre-se que o Linux é um sistema operacional multi-tarefa. Existem muitos processos em execuçăo todo o tempo, e cada um desses utiliza uma pequena porçăo do tempo do processador. Entăo, a coluna TIME deve mostrar muito menos tempo para cada processo do que ele atualmente necessita para ser executado. Se vocę notar mais do que vários minutos na coluna TIME, isto pode significar que algo está errado.
Finalmente, a coluna CMD mostra o que é o programa. Ele apenas lista o nome básico do programa, sem nenhuma opçăo de linha de comando ou informaçăo similar. Para obter essa informaçăo será necessário usar uma das muitas opçőes do ps. Iremos discuti-las brevemente.
Vocę pode conseguir uma listagem completa do que está em execuçăo no seu sistema usando a combinaçăo adequada de opçőes. Isto provavelmente resultará em uma longa lista de processos (cinqüenta e cinco no meu laptop enquanto escrevo esta sentença), entăo abreviarei a saída:
$ ps -ax
PID TTYSTAT TIME COMMAND
1 ? S 0:03 init [3]
2 ? SW 0:13 [kflushd]
3 ? SW 0:14 [kupdate]
4 ? SW 0:00 [kpiod]
5 ? SW 0:17 [kswapd]
11 ? S 0:00 /sbin/kerneld
30 ? SW 0:01 [cardmgr]
50 ? S 0:00 /sbin/rpc.portmap
54 ? S 0:00 /usr/sbin/syslogd
57 ? S 0:00 /usr/sbin/klogd -c 3
59 ? S 0:00 /usr/sbin/inetd
61 ? S 0:04 /usr/local/sbin/sshd
63 ? S 0:00 /usr/sbin/rpc.mountd
65 ? S 0:00 /usr/sbin/rpc.nfsd
67 ? S 0:00 /usr/sbin/crond -l10
69 ? S 0:00 /usr/sbin/atd -b 15 -l 1
77 ? S 0:00 /usr/sbin/apmd
79 ? S 0:01 gpm -m /dev/mouse -t ps2
94 ? S 0:00 /usr/sbin/automount /auto file /etc/auto.misc
106 tty1 S0:08 -bash
108 tty3 SW 0:00 [agetty]
109 tty4 SW 0:00 [agetty]
110 tty5 SW 0:00 [agetty]
111 tty6 SW 0:00 [agetty]
[output cut]
Muitos desses processos săo iniciados durante o boot na maioria dos sistemas. Eu fiz algumas poucas modificaçőes no meu sistema, entăo isso poderá variar dependendo da sua quilometragem. Entretanto, vocę verá muitos desses processos no seu sistema também. Como vocę pode ver, essas opçőes exibem as opçőes da linha de comando que originou o processo em execuçăo. Recentemente, uma vulnerabilidade do kernel no ptrace fez com que năo seja permitida a exibiçăo das opçőes de linha de comando de muitos processos em execuçăo. Estes săo listados agora entre colchetes como dos PIDs 108 ao 110. Também temos algumas colunas a mais e outros dados interessantes.
Primeiro, vocę perceberá que muitos desses processos săo listados como em execuçăo no tty "?". Esses năo estăo anexados a nenhum terminal em particular. Isto é muito comum com processos executados pelo sistema ("daemons"), os quais năo săo vinculados a nenhum terminal. "Daemons" comuns săo sendmail, BIND, apache e NFS. Eles, de um modo em geral, aguardam pela requisiçăo de um cliente, retornando uma resposta assim que săo demandados.
Segundo, há uma nova coluna: STAT. Ela mostra o status do processo. S corresponde a parado ("sleeping"): o processo está esperando algo acontecer. Z corresponde a um processo zumbi. Um processo zumbi é aquele cujo pai (isto é, o processo que o originou) morreu, deixando o processo filho para trás. Isso năo é uma coisa boa. D corresponde a um processo que está irreversivelmente parado. Freqüentemente esses processos recusam-se a morrer, mesmo quando recebem um SIGKILL. Vocę pode ler mais a respeito do SIGKILL na próxima seçăo sobre o kill. O W corresponde a esperando uma chamada. Um processo morto é indicado com um X. Um processo indicado por um T é rastreado ou parado. R significa que o processo é executável.
Se vocę deseja ver ainda mais informaçőes sobre os processos em execuçăo, tente isto:
$ ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 344 80 ? S Mar02 0:03 init [3]
root 2 0.0 0.0 0 0 ? SW Mar02 0:13 [kflushd]
root 3 0.0 0.0 0 0 ? SW Mar02 0:14 [kupdate]
root 4 0.0 0.0 0 0 ? SW Mar02 0:00 [kpiod]
root 5 0.0 0.0 0 0 ? SW Mar02 0:17 [kswapd]
root 11 0.0 0.0 1044 44 ? S Mar02 0:00 /sbin/kerneld
root 30 0.0 0.0 1160 0 ? SW Mar02 0:01 [cardmgr]
bin 50 0.0 0.0 1076 120 ? S Mar02 0:00 /sbin/rpc.port
root 54 0.0 0.1 1360 192 ? S Mar02 0:00 /usr/sbin/sysl
root 57 0.0 0.1 1276 152 ? S Mar02 0:00 /usr/sbin/klog
root 59 0.0 0.0 1332 60 ? S Mar02 0:00 /usr/sbin/inet
root 61 0.0 0.2 1540 312 ? S Mar02 0:04 /usr/local/sbi
root 63 0.0 0.0 1796 72 ? S Mar02 0:00 /usr/sbin/rpc.
root 65 0.0 0.0 1812 68 ? S Mar02 0:00 /usr/sbin/rpc.
root 67 0.0 0.2 1172 260 ? S Mar02 0:00 /usr/sbin/cron
root 77 0.0 0.2 1048 316 ? S Mar02 0:00 /usr/sbin/apmd
root 79 0.0 0.1 1100 152 ? S Mar02 0:01 gpm
root 94 0.0 0.2 1396 280 ? S Mar02 0:00 /usr/sbin/auto
chris106 0.0 0.5 1820 680 tty1 S Mar02 0:08 -bash
root 108 0.0 0.0 1048 0 tty3 SW Mar02 0:00 [agetty]
root 109 0.0 0.0 1048 0 tty4 SW Mar02 0:00 [agetty]
root 110 0.0 0.0 1048 0 tty5 SW Mar02 0:00 [agetty]
root 111 0.0 0.0 1048 0 tty6 SW Mar02 0:00 [agetty]
[output cut]
Isso é que é quantidade de informaçăo! Basicamente foram incluídas informaçőes como qual o usuário iniciou o processo, quanto o processo está usando dos recursos do sistema (as colunas %CPU, %MEM, VSZ e RSS), e em qual data o processo foi iniciado. Obviamente, isso é uma grande quantidade de informaçăo que pode estar ŕ măo para um administrador de sistemas. Isso também traz ŕ tona outro ponto: a informaçăo exibida é limitada ŕ largura da tela o que năo permite que vocę a veja completamente. A opçăo -w irá forçar o ps a quebrar linhas longas.
Năo é a coisa mais linda, mas funciona. Agora vocę tem uma lista de informaçőes completa para cada processo. Ainda há mais informaçőes que podem ser mostradas para cada processo. Verifique a profunda página de manual do ps. Entretanto as opçőes mostradas acima săo as mais populares e serăo usadas com mais freqüęncia.
Em algumas ocasiőes, programas comportam-se mal e vocę precisará coloca-los "na linha". O programa para esse tipo de administraçăo é chamado kill(1), e pode ser usado para manipular processos de várias maneiras. O mais óbvio dos usos do kill é interromper um processo. Vocę precisará fazer isso se um programa se perder e utilizar uma grande quantidade de recursos do sistema, ou se vocę só estiver cansado de vę-lo em execuçăo.
Para interromper um processo vocę precisará saber seu PID ou seu nome. Para conseguir o PID utilize o comando ps que foi discutido na última seçăo. Por exemplo, para interromper o processo 4747, vocę deverá fazer o seguinte:
$ kill 4747
Perceba que vocę terá de ser o dono do processo para poder interrompę-lo. Isso é uma questăo de segurança. Se vocę tivesse permissăo para interromper processos iniciados por outros usuários, seria possível realizar uma porçăo de coisas maliciosas. É claro, o root pode interromper qualquer processo do sistema.
Há ainda outra variaçăo do comando kill chamada killall(1). Este programa faz exatamente o que diz: interrompe todos os processos que possuem determinado nome. Se vocę quisesse interromper todos os processos vim em execuçăo, vocę poderia digitar o seguinte comando:
$ killall vim
Todo e qualquer processo vim que vocę estiver executando será interrompido. Fazendo isto como usuário root irá interromper todos os processos vim em execuçăo, independente do usuário. Isso traz uma interessante maneira de derrubar todos usuários (incluindo vocę) do sistema:
# killall bash
Algumas vezes um simples kill năo é suficiente. Certos processos năo săo interrompidos com um kill. Vocę terá de usar uma forma mais potente. Se aquele PID 4747 pentelho năo responder ao seu kill, vocę poderá fazer o seguinte:
$ kill -9 4747
É quase certo que o processo 4747 será interrompido. Vocę pode fazer a mesma coisa com o killall. O que isso faz é enviar um sinal diferente para o processo. Um kill regular envia um sinal SIGTERM (terminar) para o processo, o qual diz que é para terminar o que estiver fazendo, fechar o que estiver utilizando e sair. kill -9 envia um sinal SIGKILL (interromper) para o processo, o que essencialmente o para. Năo é permitido ao processo fechar o que estiver utilizando e algumas vezes coisas ruins, como corrupçăo de dados, podem ocorrer com um SIGKILL. Há uma lista completa de sinais ŕ sua disposiçăo. Vocę pode obtę-la digitando:
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD
18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN
22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO
30) SIGPWR
O número deve ser usado para o kill, enquanto o nome menos o prefixo "SIG" pode ser usado com o killall. Aqui vai outro exemplo:
$ killall -KILL vim
Um último uso para o kill é reiniciar um processo. Enviando um SIGHUP irá fazer com que muitos processos releiam seus arquivos de configuraçăo. Isso é especialmente útil para fazer com que os processos releiam seus arquivos de configuraçăo recém editados.
Finalmente, há um comando que vocę pode usar para exibir informaçőes atualizadas sobre os processos em execuçăo no sistema. Esse comando é chamado top(1), e é iniciado assim:
$ top
Isto irá exibir uma tela cheia com informaçőes sobre os processos em execuçăo no sistema, bem como algumas informaçőes gerais sobre o próprio sistema. Isso inclui a carga média, número de processos, o status da CPU, informaçőes sobre memória livre e detalhes dos processos incluindo PID, usuário, prioridade, uso de CPU e memória, tempo de execuçăo e nome do programa.
6:47pm up 1 day, 18:01, 1 user, load average: 0.02, 0.07, 0.02
61 processes: 59 sleeping, 2 running, 0 zombie, 0 stopped
CPU states: 2.8% user, 3.1% system, 0.0% nice, 93.9% idle
Mem: 257992K av, 249672K used, 8320K free, 51628K shrd, 78248K buff
Swap: 32764K av, 136K used, 32628K free, 82600K cached
PID USER PRI NI SIZE RSS SHARE STAT LIB %CPU %MEM TIME COMMAND
112 root 12 0 19376 18M 2468 R 0 3.7 7.5 55:53 X
4947 david 15 0 2136 2136 1748 S 0 2.3 0.8 0:00 screenshot
3398 david 7 0 20544 20M 3000 S 0 1.5 7.9 0:14 gimp
4946 root 12 0 1040 1040 836 R 0 1.5 0.4 0:00 top
121 david 4 0 796 796 644 S 0 1.1 0.3 25:37 wmSMPmon
115 david 3 0 2180 2180 1452 S 0 0.3 0.8 1:35 wmaker
4948 david 16 0 776 776 648 S 0 0.3 0.3 0:00 xwd
1 root1 0 176 176 148 S 0 0.1 0.0 0:13 init
189 david 1 0 6256 6156 4352 S 0 0.1 2.4 3:16 licq
4734 david 0 0 1164 1164 916 S 0 0.1 0.4 0:00 rxvt
2 root0 0 0 0 0 SW 0 0.0 0.0 0:08 kflushd
3 root0 0 0 0 0 SW 0 0.0 0.0 0:06 kupdate
4 root0 0 0 0 0 SW 0 0.0 0.0 0:00 kpiod
5 root0 0 0 0 0 SW 0 0.0 0.0 0:04 kswapd
31 root0 0 340 340 248 S 0 0.0 0.1 0:00 kerneld
51 root0 0 48 48 32 S 0 0.0 0.0 0:00 dhcpcd
53 bin 0 0 316 316 236 S 0 0.0 0.1 0:00 rpc.portmap
57 root0 0 588 588 488 S 0 0.0 0.2 0:01 syslogd
Ele é chamado de top porque os programas que fazem uso intensivo da CPU serăo listados no topo. Uma observaçăo interessante é que o próprio top será listado primeiro em muitos sistemas inativos (e alguns ativos) por causa da utilizaçăo de CPU. Entretanto, o top é muito útil para determinar qual programa está se comportando mal e precisa ser interrompido.
Mas suponha que vocę só queira uma lista dos seus próprios processos, ou dos processos de algum outro usuário. Os processos que vocę quer ver podem năo estar entre os programas em execuçăo com maior consumo de CPU. A opçăo -u permite que vocę especifique um nome de usuário ou UID e monitore somente os processos pertencentes ŕquele UID.
$ top -u alan
PID USERPR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3622 alan13 0 11012 10m 6956 S 1.0 2.1 0:03.66 gnome-terminal
3739 alan13 0 1012 1012 804 R 0.3 0.2 0:00.06 top
3518 alan 9 0 1312 1312 1032 S 0.0 0.3 0:00.09 bash
3529 alan 9 0 984 984 848 S 0.0 0.2 0:00.00 startx
3544 alan 9 0 640 640 568 S 0.0 0.1 0:00.00 xinit
3548 alan 9 0 8324 8320 6044 S 0.0 1.6 0:00.30 gnome-session
3551 alan 9 0 7084 7084 1968 S 0.0 1.4 0:00.50 gconfd-2
3553 alan 9 0 2232 2232 380 S 0.0 0.4 0:00.05 esd
3555 alan 9 0 2552 2552 1948 S 0.0 0.5 0:00.10 bonobo-activati
3557 alan 9 0 2740 2740 2224 S 0.0 0.5 0:00.05 gnome-smproxy
3559 alan 9 0 6496 6492 5004 S 0.0 1.3 0:00.31 gnome-settings-
3565 alan 9 0 1740 1740 1440 S 0.0 0.3 0:00.28 xscreensaver
3568 alan 9 0 7052 7052 4960 S 0.0 1.4 0:02.28 metacity
3572 alan 9 0 11412 11m 7992 S 0.0 2.2 0:01.58 gnome-panel
3574 alan 9 0 12148 11m 8780 S 0.0 2.4 0:00.64 nautilus
3575 alan 9 0 12148 11m 8780 S 0.0 2.4 0:00.00 nautilus
3576 alan 9 0 12148 11m 8780 S 0.0 2.4 0:00.00 nautilus
Como vocę pode ver, atualmente estou executando X, top, um gnome-terminal (no qual estou escrevendo isto) e muitos outros processos relacionados ao ambiente gráfico X, os quais estăo tomando a maior parte do tempo da minha CPU. Isto é uma boa maneira de monitorar o quăo duro seus usuários estăo trabalhando no sistema.
O top também permite monitorar processos por seus PID, ignorando processos sem atividade e zumbis, e muitas outras opçőes. O melhor lugar para aprender a lidar com essas opçőes săo as páginas de manual para o top.
Ha Ha Ha Ha.... Eu sei o que vocę deve estar pensando." Eu năo sou um administrador de sistema! Eu năo quero mesmo ser um!"
O fato é que vocę é o administrador de qualquer computador no qual vocę possui a senha do usuário root. Pode ser seu desktop com um ou dois usuários, ou pode ser um grande servidor com várias centenas de usuários. Independente disto, vocę deverá saber como gerenciar usuários e como desligar o sistema de modo seguro. Estas tarefas parecem simples, mas elas tęm alguns caprichos que vocę deve ter em mente.
Como mencionado no capítulo 8, vocę năo deve usar normalmente seu sistema logado como root. Em vez disto, vocę deve criar uma conta de usuário normal para o uso diário e usar a conta do root apenas para tarefas de administraçăo do sistema. Para criar um usuário, vocę pode usar as ferramentas fornecidas pelo Slackware ou editar manualmente o arquivo de senhas.
O modo mais fácil de gerenciar usuários e grupos é com os scripts e programas fornecidos. O Slackware inclui os programas adduser, userdel(8), chfn(1), chsh(1), e passwd(1) para gerenciar usuários. Os comandos groupadd(8), groupdel(8), e groupmod(8) săo para gerenciar grupos. Com exceçăo de chfn, chsh, e passwd, esses programas săo executados apenas pelo root, e estăo, portanto, localizados em /usr/sbin. chfn, chsh, e passwd podem ser executados por qualquer um e estăo localizados em /usr/bin.
Usuários podem ser adicionados com o comando adduser. Iniciaremos pelo procedimento completo, mostrando todas as perguntas que săo solicitadas e uma breve descriçăo do que cada uma significa. A resposta padrăo está entre colchetes e pode ser adotada para quase todas as perguntas, a menos que vocę realmente queira mudar alguma coisa.
# adduser
Login name for new user []: jellyd
Este é o nome que o usuário usará para se logar. Tradicionalmente, login names possuem oito ou menos caracteres e todos minúsculos (vocę pode usar mais que oito caracteres, inclusive numérico, mas evite fazer isso a menos que vocę tenha uma boa razăo.)
Vocę pode fornecer o nome de login como um argumento do comando:
# adduser jellyd
No outro caso, depois de fornecer o nome de login, o comando adduser perguntará pelo ID do usuário:
User ID ('UID') [ defaults to next available ]:
O ID do usuário (UID) é quem realmente identifica os membros no Linux. Cada usuário tem um número único, começando em 1000 no Slackware. Vocę pode definir um UID para um novo usuário ou entăo deixar que o adduser designe para o usuário o próximo UID livre.
Initial group [users]:
Todos os usuários pertencem ao grupo users por padrăo. Vocę pode querer colocar o usuário novo em um grupo diferente, mas isto năo é recomendado a menos que vocę saiba o que está fazendo.
Additional groups (comma separated) []:
Esta pergunta permite vocę colocar o novo usuário em grupos adicionais. É possível para um usuário estar em vários grupos ao mesmo tempo. Isso é útil se vocę tem grupos específicos, por exemplo, modificar arquivos de web site, jogar, etc. Por exemplo, alguns site definem o grupo wheel como o único grupo que pode usar o comando su. Ou, como padrăo, a instalaçăo do Slackware usa o grupo sys para usuários autorizados a utilizarem a placa de som interna.
Home directory [/home/jellyd]
Os diretórios home padrăo săo colocados em /home. Se vocę usa um sistema muito grande, é possível que vocę tenha que mover os diretórios home para uma localizaçăo diferente (ou para várias localizaçőes). Esta etapa permite que vocę especifique onde será o diretório home do usuário.
Shell [ /bin/bash ]
bash é o shell padrăo no Slackware Linux e será adequado para a maioria das pessoas. Se seu novo usuário vem de um ambiente Unix, ele pode estar familiarizado com um shell diferente. Vocę pode mudar o shell dele nesse momento ou ele pode mudar mais tarde usando o comando chsh.
Expiry date (YYYY-MM-DD) []:
As contas podem ser configuradas para expirarem numa data específica. Por padrăo, năo há uma data limite. Vocę pode mudar isso se vocę desejar. Essa opçăo pode ser útil para pessoas executando um ISP (Provedor de Serviços de Internet) que querem fazer uma conta expirar após uma certa data, a menos que elas recebam o pagamento do próximo ano.
New account will be created as follows:
---------------------------------------
Login name: jellyd
UID: [ Next available ]
Initial group:users
Additional groups: [ None ]
Home directory: /home/jellyd
Shell: /bin/bash
Expiry date: [ Never ]
Isto é ... se vocę quiser desistir, tecle Control+C. Caso contrário, tecle ENTER para seguir em frente e criar a conta.
Nesse momento, vocę vę todas as informaçőes digitadas para a nova conta e tem a oportunidade de abortar a criaçăo da conta. Se vocę entrou com algo incorreto, pode teclar Control+C e iniciar novamente. Caso contrário, vocę pode teclar enter e a conta será criada.
Creating new account...
Changing the user information for jellyd Enter the new value, or press return for the default Full Name []: Jeremy Room Number []: Smith 130 Work Phone []: Home Phone []: Other []:
Todas essas informaçőes săo opcionais. Vocę năo tem que entrar com nenhuma dessas informaçőes se năo quiser, e o usuário pode mudar esses dados a qualquer hora usando o comando chfn. Entretanto, pode ser útil colocar pelo menos o nome completo e um número de telefone, no caso de vocę precisar entrar em contato com a pessoa em questăo.
Changing password for jellyd
Enter the new password (minimum of 5, maximum of 127 characters)
Please use a combination of upper and lower case letters and numbers.
New password:
Re-enter new password:
Password changed.
Account setup complete.
Vocę terá que entrar com uma senha para o novo usuário. Geralmente, se o usuário năo estiver fisicamente presente nesse momento, vocę apenas colocará uma senha padrăo e avisará o usuário para mudá-la para uma senha mais segura.
NOTA: Escolhendo uma senha: Ter uma senha segura é a primeira linha de defesa contra invasăo. Vocę năo quer ter uma senha de fácil deduçăo porque isto torna mais fácil alguém entrar em seu sistema. Uma senha ideal seria uma sequęncia aleatória de caracteres, incluindo letras maiúsculas e minúsculas, números e caracteres aleatórios. (Um caractere tab pode năo ser uma boa escolha dependendo em qual tipo de computador vocę estará logando.) Há muitos pacotes de softwares que geram senha aleatórias para vocę; procure na Internet por esses utilitários.
Em geral, use o bom senso: năo coloque uma senha que seja a data de aniversário de alguém, algo encontrado em sua mesa, ou qualquer coisa facilmente associada com vocę. Uma senha como "seguro1" ou qualquer outra senha que vocę ver impresso ou online também é ruim.
Remover usuários năo é uma tarefa complicada. Apenas execute userdel com o nome da conta para removę-la. Vocę deve verificar se o usuário năo está logado e se năo há processos do usuário em execuçăo. E mais, lembre que uma vez excluido o usuário, toda a informaçăo da senha do usuário terá sido apagada permanentemente.
# userdel jellyd
Este comando remove o usuário jellyd do seu sistema. O usuário é removido dos arquivos /etc/passwd, /etc/shadow, e /etc/group, mas năo remove o diretório home do usuário.
Se vocę deseja também remover o diretório home, vocę deve usar este comando:
# userdel -r jellyd
Desabilitar temporariamente uma conta será tratada na próxima seçăo sobre senhas, uma vez que uma mudança temporária envolve mudar a senha do usuário. Mudar outra informaçăo da conta é tratada na seçăo 12.1.3.
Os programas para adicionar e remover grupos săo bem simples. groupadd adicionará outra entrada no arquivos /etc/group com um ID de grupo único, enquanto groupdel removerá o grupo especificado. É possível editar o arquivo /etc/group para adicionar usuários em um grupo específico. Por exemplo, para adicionar um grupo chamado cvs:
# groupadd cvs
E removę-lo:
# groupdel cvs
O comando passwd muda as senhas modificando o arquivo /etc/shadow. Este arquivo contém todas as senhas do sistema em formato criptografado. Para mudar sua senha, vocę digitaria:
$ passwd
Changing password for chris
Old password:
Enter the new password (minumum of 5, maximum of 127 characters)
Please use a combination of upper and lower case letters and numbers.
New password:
Como se pode ver, vocę é solicitado para entrar com sua senha antiga. Ela năo aparecerá na tela quando vocę digitá-la, o mesmo ocorre quando vocę se loga. Entăo, vocę é solicitado para entrar com a nova senha. passwd realiza várias verificaçőes em sua nova senha e avisará se ela năo passar nas verficaçőes. Vocę pode ignorar esses avisos caso queira. Vocę será solicitado para entrar com sua nova senha por uma segunda vez para confirmá-la.
Se vocę é root, vocę também pode mudar a senha de outros usuários:
# passwd ted
Vocę entăo passará pelo mesmo procedimento acima, com exceçăo que vocę năo terá que digitar a senha antiga do usuário (um dos muitos benefícios de ser root...)
Se precisar, vocę também pode desabilitar temporiamente uma conta, e reabilitá-la mais tarde se for preciso. Desabilitar e reabilitar uma conta podem ser feitos com passwd. Para desabilitar uma conta, faça o seguinte como root:
# passwd -l david
Isto mudará a senha de david para algo que nunca coincida com qualquer valor criptografado. Vocę reabilita a conta usando:
# passwd -u david
Agora, a conta de david está de volta ao normal. Desabilitar uma conta pode ser útil se o usuário năo segue as regras que vocę definiu para seu sistema, ou se ele exportou uma cópia muito grande de xeyes(1) para seu desktop X.
Há dois tipos de informaçăo que os usuários podem mudar a qualquer hora: o shell e o finger. O Slackware Linux usa chsh (change shell) e chfn (change finger) para modificar esses valores.
Um usuário pode definir qualquer shell que está listado no arquivo /etc/shells. Para a maioria das pessoas, /bin/bash será adequado. Outros podem estar familiarizados com um shell encontrado nos seus sistemas, no trabalho ou na escola e desejam usar aquele que eles já conhecem. Para mudar seu shell, use chsh:
$ chsh
Password:
Changing the login shell for chris
Enter the new value, or press return for the default
Login Shell [/bin/bash]:
Depois de digitar sua senha, digite o caminho completo do novo shell. Primeiro, tenha certeza que ele está listado no arquivo /etc/shells(5). O usuário root pode mudar o shell de qualquer usuário executando chsh utilizando o nome do usuário como argumento.
A informaçăo de finger é a informaçăo opcional como nome completo, números de telefone e de sala. Estas informaçőes podem ser mudadas usando chfn, e segue o mesmo procedimento feito na criaçăo da conta. Como sempre, o usuário root pode mudar a informaçăo de finger de qualquer um.
Naturalmente, é possível adicionar, modificar e remover usuários e grupos sem usar os scripts e programas que vęm com o Slackware. Năo é muito difícil, embora depois de ler este processo, vocę provavelmente achará muito mais fácil usar os scripts. Entretanto, é importante conhecer como realmente a informaçăo de sua senha é armazenada, no caso de vocę precisar recuperar esta informaçăo e năo ter as ferramentas do Slackware disponível.
Primeiro, nós adicionaremos um novo usuário nos arquivos /etc/passwd(5), /etc/shadow(5) e /etc/group(5). O arquivo passwd contém algumas informaçőes sobre os usuários do seu sistema, mas (bastante estranho) năo tęm as senhas deles. Isto năo era assim, mas foi alterado tempos atrás por questőes de segurança. O arquivo passwd deve ser legível para todos os usuários, mas vocę năo deseja senhas criptografadas legíveis, pois intrusos poderiam usar as senhas criptografadas como ponto inicial para descriptografar as senhas dos usuários. Ao invés disto, as senhas criptografadas săo mantidas no arquivo shadow, que é legível apenas para o root, e a senha de todos aparecem no arquivo passwd simplesmente com um "x". O arquivo group lista todos os grupos e quem está em cada um deles.
Vocę pode usar o comando vipw para editar o arquivo /etc/passwd de modo seguro, e o comando vigr para editar o arquivo /etc/group também de modo seguro. Use vipw -s para editar o arquivo /etc/shadow. ("Modo seguro neste contexto significa que ninguém mais será capaz de modificar o arquivo que vocę está editando no momento. Se vocę é o único administrador do seu sistema, vocę provavelmente está em segurança, mas é melhor pegar bons hábitos no início.)
Vamos examinar o arquivo /etc/passwd e ver como adicionar um novo usuário. Uma típica entrada em passwd se parece como isto:
chris:x:1000:100:Chris Lumens,Room 2,,:/home/chris:/bin/bash
Cada linha corresponde a um usuário e os campos de cada linha săo separados pelo caracter dois pontos. Os campos săo o nome de login, senha criptografada (um "x" para todos em um sistema Slackware, sendo que o Slackware usa senhas mascaradas), ID do usuário, ID do grupo, informaçőes adicionais (separadas por vírgula), diretório home e o shell. Para adicionar um novo usuário manualmente, adicione uma nova linha no final do arquivo preenchendo as informaçőes apropriadas.
As informaçőes que vocę adicionar precisam atender alguns requisitos, ou seu novo usuário poderá ter problemas ao se logar. Primeiro, tenha certeza que o campo da senha é um x, e que o nome do usuário e seu ID sejam únicos. Atribua um grupo para o usuário, ou 100 (o grupo "users" no Slackware) ou seu grupo padrăo (use o número do grupo, năo o nome). Dę ao usuário um diretório home válido (que vocę criará mais tarde) e o shell (lembre-se, os shells válidos estăo listados em /etc/shells).
Em seguida, precisaremos adicionar uma entrada no arquivo /etc/shadow, que contém as senhas criptografadas. Uma entrada típica se parece com:
chris:$1$w9bsw/N9$uwLr2bRER6YyBS.CAEp7R.:11055:0:99999:7:::
Novamente, cada linha corresponde a uma pessoa, com os campos delimitados pelo caracter dois pontos. Os campos săo (em ordem) nome de login, senha criptografada, dias deste a época (01 de janeiro de 1970) que a senha foi mudada pela última vez, dias antes da senha poder ser alterada, dias depois que a senha deve ser alterada, dias que o usuário é notificado antes da senha expirar, dias depois da senha expirar que a conta é desabilidada, dias deste a época que a conta está desabilidada e um campo reservado.
Como vocę pode ver, a maioria dos campos săo para informaçőes de validade de contas. Se vocę năo está usando uma informaçăo deste, vocę precisa apenas preencher uns poucos campos com alguns valores em especial. Caso contrário, vocę precisará calcular e tomar decisőes antes de poder preencher esses campos. Para um novo usuário, apenas coloque algum lixo aleatório no campo de senha. Năo se preocupe se a senha está correta agora, porque vocę irá mudá-la em um minuto. O único caractere que vocę năo pode incluir no campo da senha é o dois pontos. Deixe o campo "dias desde que a senha foi alterada" em branco. Preencha com 0, 99999, e 7 como vocę viu no exemplo acima e deixe os outros campos em branco..
(Para aqueles que pensam que vendo minha senha criptograda acima acreditam que tęm uma brecha para entrar em meu sistema, entăo sigam em frente. Se vocę decifrar aquela senha, vocę saberá a senha para um teste de firewall do sistema. Isto é muito útil. :) )
Todos os usuário comuns săo membros do grupo "users" num sistema típicamente Slackware. Entretanto, se vocę deseja criar um novo grupo, ou adicionar o usuário em grupos adicionais, vocę precisará modificar o arquivo /etc/group. Aqui está uma típica entrada:
cvs::102:chris,logan,david,root
Os campos săo nome do grupo, senha do grupo, ID do grupo e membros do grupos, separados por vírgulas. Criar um novo grupo é simples como adicionar uma nova linha com um número de ID único e listar todos os usuários que vocę quer no grupo. Qualquer usuário que está no novo grupo e está logado terá que logar novamente para que as mudanças tenham efeito.
Neste ponto, pode ser uma boa idéia usar os comandos pwck e grpck para verificar se as mudanças que vocę fez săo consistentes. Primeiro, use pwck -r e grpck -r: a opçăo -r năo faz as alteraçőes, mas lista as alteraçőes que vocę teria feito se vocę executasse o comando sem aquela opçăo. Vocę pode usar a saída do comando para decidir se precisa modificar mais algum arquivo, executando pwck ou grpck sem a opçăo-r, ou simplesmente deixar as mudanças como estăo.
Neste ponto, vocę deve usar o comando passwd para criar uma senha apropriada para o usuário. Entăo, use o comando mkdir para criar o diretório home do novo usuário no local que vocę entrou no arquivo /etc/passwd e o comando chown para mudar o proprietário do novo diretório.
Remover um usuário é uma simples questăo de excluir todas as entradas que existem do usuário. Remova a entrada do usuário dos arquivos /etc/passwd e /etc/shadow, e remova o nome de login dos grupos no arquivo /etc/group. Se vocę desejar, apagar o diretório home, o arquivo de spool de mail (se eles existirem).
Remover grupos é similar: remova as entradas do arquivo /etc/group.
É muito importante que vocę desligue seu sistema apropriadamente. Simplesmente desligar pelo botăo de energia pode causar sérios estragos no sistema de arquivos. Enquanto o sistema está ligado, arquivos estăo em uso mesmo que vocę năo esteja fazendo nada. Lembre-se que há muitos processos rodando em segundo plano o tempo todo. Esses processos săo gerenciados pelo sistema e mantęm vários arquivos abertos. Quando o sistema é desligado pelo botăo de energia, esses arquivos năo săo fechados apropriadamente e podem ficar corrompidos. Dependendo de quais arquivos săo corrompidos, o sistema pode ficar completamente inutilizado! Em qualquer caso, vocę terá que passar por um processo longo de checagem do sistema de arquivos na próxima inicializaçăo.
NOTA: Se vocę configurou seu sistema com um sistema de arquivos com journalling, como ext3 ou reiserfs, vocę está parcialmente protegido contra estragos no sistema de arquivos, e a checagem do sistema de arquivos é mais curta se vocę usa um sistema de arquivo sem journalling, como ext2. Entretanto, esta segurança năo é desculpa para desligar seu sistema de modo inapropriado! Um sistema de arquivos com journalling é uma tentativa de proteger seus arquivos de eventos além de seu controle, năo contra sua própria indolęncia.
Em todo caso, quando vocę quiser reinicializar ou desligar seu computador, é importante fazę-lo corretamente. Há vários meios de se fazer isso; vocę pode usar o que achar mais divertido (ou menos trabalhoso). Sendo que desligar e reinicializar săo procedimentos similares, a maioria dos meios de desligar o sistema também podem ser aplicados para reinicializá-lo.
O primeiro método é através do comando shutdown(8), e é provavelmente o mais popular. shutdown pode ser usado para reinicializar ou desligar o sistema em um dado tempo e pode mostrar uma mensagem a todos os usuários logados no sistema dizendo que está sendo desligado.
O modo mais básico de desligar o computador é:
# shutdown -h now
Neste caso, năo será enviada uma mensagem personalizada para os usuários; eles verăo a mensagem padrăo de shutdown. "now" é o tempo que vocę quer desligar e o "-h" significa terminar o sistema. Năo é um modo muito amigável de se fazer em um sistema multiusuários, mas funciona adequadamente em seu computador de casa. Um método melhor em um sistema multiusuário é dar a todos um aviso antecipado:
# shutdown -h +60
Isto desligará o sistema em uma hora(60 minutos), que é adequado em um sistema multiusuário normal. Sistemas essenciais devem ter a sua hora de desligar agendada antecipadamente, e vocę deve colocar avisos sobre a hora de desligar em quaisquer lugares usados apropriadamente para notificaçőes do sistema (email, quadro de aviso, /etc/motd, ou qualquer outro).
Para reinicializar o sistema, usa-se o mesmo comando, mas substitui-se "-h" por "-r":
# shutdown -r now
Vocę pode usar a mesma notaçăo de tempo com shutdown -r que vocę usuaria com shutdown -h. Há muitas outras coisas que vocę pode fazer com o comando shutdown para controlar quando desligar ou reinicializar a máquina; veja a página de manual para mais detalhes.
O segundo modo de desligar ou reinicializar o computador é usar os comandos halt(8) e reboot(8). Como os nomes indicam, halt terminará imediatamente a operaçăo do sistema e reboot reinicializará o sistema. (reboot é na verdade apenas um link simbólico para o comando halt.) Eles săo executados como:
# halt
# reboot
Um meio de baixo nível de reinicializar ou desligar o sistema é usar diretamente o comando init. Todos os outros métodos săo simplesmente meios convenientes de usar init, mas vocę pode dizer diretamente ao init o que fazer usando telinit(8) . Usar telinit dirá ao init que nível de execuçăo (runlevel) acionar, o que fará um script especial ser executado. Este script matará ou ressusitará processos necessários para aquele nível de execuçăo. Isto funciona para reinicializar e desligar porque ambos săo níveis especiais de execuçăo.
# telinit 0
O nível de execuçăo 0 é o modo de desligar. Dizer ao init para entrar neste nível fará todos os processos serem terminados, o sistema de arquivos será desmontado e a máquina será desligada. Isto é um modo perfeitamente aceitável de desligar o sistema. Em muitos laptops e computadores desktops modernos, isso fará com que a máquina seja desligada.
# telinit 6
O nível de execuçăo 6 é o modo de reinicializaçăo. Todos os processos serăo terminados, o sistema de arquivo será desmontado e a máquina será reinicializada. Isto é um modo perfeitamente aceitável de reinicializar o sistema.
Para os curiosos, quando muda-se para os níveis de execuçăo 0 ou 6, seja usando shutdown, halt, ou reboot, o script /etc/rc.d/rc.6 é executado. (O script /etc/rc.d/rc.0 um link simbólico para /etc/rc.d/rc.6.) Vocę pode personalizar este arquivo a seu gosto -- mas esteja certo de testar suas mudanças cuidadosamente!
Há um último método de reinicializar o sistema. Todos os outros métodos requerem que vocę esteja logado como root. Entretanto, é possível reinicializar a máquina mesmo se vocę năo é o adminstrador, contanto que vocę tenha acesso físico ao teclado. Teclar Control+Alt+Delete (a "saudaçăo de tręs dedos") fará a máquina reinicializar imediatamente. (Por trás deste cenário, o comando shutdown é chamado para vocę quando usa Control+Alt+Delete.) Isto nem sempre funciona quando se está usando o X Windows -- vocę pode precisar usar Control+Alt+F1 (ou outra tecla de funçăo) para alternar para um terminal em modo texto antes.
Finalmente, o arquivo que efetivamente controla cada aspecto da inicializaçăo e do desligamento é o arquivo /etc/inittab(5). Em geral, vocę năo deve modificar este arquivo, mas ele pode dar a vocę noçőes de como algumas coisas funcionam. Como sempre, veja as páginas de manual para mais detalhes.
Uma rede consiste em vários computadores conectados entre si. A rede pode ser tăo simples quanto alguns computadores ligados em casa ou no escritório, ou tăo complicada quanto uma rede de uma grande universidade ou a Internet. Quando seu computador é parte de uma rede, vocę tem acesso a esses sistemas diretamente ou através de serviços como o correio eletrônico ou a web.
Existe uma variadade de programas para redes que vocę pode usar. Alguns săo úteis para realizar diagnósticos como verificar se a rede está funcionando corretamente. Outros (como leitores de e-mail e navegadores) săo úteis para trabalhar ou manter contato com outras pessoas.
O ping(8) envia um pacote ICMP ECHO_REQUEST para o host especificado. Se o host responde, vocę recebe o pacote ICMP de volta. Parece estranho? Bom, vocę pode "dar um ping" em um endereço IP para saber se a máquina está conectada. Se năo obtiver resposta, vocę sabe que alguma coisa está errada.
Aqui está um exemplo de conversa entre dois usuários Linux:
//Usuário A//: A máquina Loki está desligada de novo.
//Usuário B//: Vocę tem certeza?
//Usuário A//: Sim, eu tentei pingá-la, mas năo obtive resposta.
Săo circunstâncias como essas que fazem o ping ser um comando muito útil no dia a dia. Ele provę uma forma muito rápida de ver se uma máquina está ligada e conectada ŕ rede. A sintaxe básica é:
$ ping www.slackware.com
Existem, obviamente, várias opçőes que podem ser especificadas. Olhe a página de manual de ping(1) para maiores informaçőes.
O traceroute(8) do Slackware é uma ferramenta de diagnóstico de rede muito útil. traceroute mostra por quais hosts um pacote passa até chegar ao seu destino. Vocę pode ver quantos hosts tem do seu computador até o site do Slackware com esse comando:
$ traceroute www.slackware.com
Cada host vai ser mostrado, assim como o tempo de resposta de cada host. Aqui está um exemplo de saida do comando:
$ traceroute www.slackware.com
traceroute to www.slackware.com (204.216.27.13), 30 hops max, 40 byte packets
1 zuul.tdn (192.168.1.1) 0.409 ms 1.032 ms 0.303 ms
2 207.171.227.254 (207.171.227.254) 18.218 ms 32.873 ms 32.433 ms
3 border-sf-2-0-4.sirius.com (205.134.230.254) 15.662 ms 15.731 ms 16.142 ms
4 pb-nap.crl.net (198.32.128.20) 20.741 ms 23.672 ms 21.378 ms
5 E0-CRL-SFO-03-E0X0.US.CRL.NET (165.113.55.3) 22.293 ms 21.532 ms 21.29 ms
6 T1-CDROM-00-EX.US.CRL.NET (165.113.118.2) 24.544 ms 42.955 ms 58.443 ms
7 www.slackware.com (204.216.27.13) 38.115 ms 53.033 ms 48.328 ms
O traceroute é similar ao ping, já que o mesmo usa pacotes ICMP também. Existem várias opçőes que vocę pode especificar para o traceroute. Essas opçőes săo explicadas em detalhes na respectiva página de manual.
O Domain Name Service (abreviado por DNS) é o protocolo mágico que permite a seu computador converter nomes de domínio como www.slackware.com em endereços IP 64.57.102.34. Computadores năo podem rotear pacotes para www.slackware.com, mas eles podem rotear pacotes para o endereço IP desse domínio. Isso nos dá uma forma conveniente de lembrarmos de máquinas. Sem o DNS teríamos que manter um banco de dados mental de qual endereço IP pertence a qual computador, e assumindo que o endereço IP é sempre o mesmo. Claramente usar nomes para computadores é melhor, mas como nós mapeamos nomes em endereços IP?
O host(1) pode fazer isso por nós. host é usado para mapear nomes em endereços IP. É um utilitário muito rápido e simples, sem muitas funçőes.
$ host www.slackware.com
www.slackware.com is an alias for slackware.com.
slackware.com has address 64.57.102.34
Mas vamos supor que por alguma razăo nós queremos mapear um endereço IP para um nome de domínio; e entăo?
nslookup é um programa que tem resistido ao tempo. nslookup está depreciado e pode ser removido de lançamentos futuros. Năo existe nem mesmo uma página de manual para este programa.
$ nslookup 64.57.102.34
Note: nslookup is deprecated and may be removed from future releases.
Consider using the `dig' or `host' programs instead. Run nslookup with
the `-sil[ent]' option to prevent this message from appearing.
Server: 192.168.1.254
Address: 192.168.1.254#53
Non-authoritative answer:
www.slackware.com canonical name = slackware.com.
Name: slackware.com
Address: 64.57.102.34
O Domain Information Groper, dig(1) abreviando, é o programa que pega informaçőes DNS. dig pode pegar qualquer informaçăo de um servidor DNS incluindo reverse lookups, A, CNAME, MS, SP, e registros TXT. dig possui muitas opçőes de linha de comando e se vocę năo é familiar com eles, leia a extensiva página de manual da ferramenta.
$ dig @192.168.1.254 www.slackware.com mx
; <<>> DiG 9.2.2 <<>> @192.168.1.254 www.slackware.com mx
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 26362
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 2, ADDITIONAL: 2
;; QUESTION SECTION:
;www.slackware.com. IN MX
;; ANSWER SECTION:
www.slackware.com.76634 IN CNAME slackware.com.
slackware.com. 86400 IN MX 1 mail.slackware.com.
;; AUTHORITY SECTION:
slackware.com. 86400 IN NS ns1.cwo.com.
slackware.com. 86400 IN NS ns2.cwo.com.
;; ADDITIONAL SECTION:
ns1.cwo.com. 163033 IN A 64.57.100.2
ns2.cwo.com. 163033 IN A 64.57.100.3
;; Query time: 149 msec
;; SERVER: 192.168.1.254#53(192.168.1.254)
;; WHEN: Sat Nov 6 16:59:31 2004
;; MSG SIZE rcvd: 159
O exemplo acima deve dar uma idéia de como o dig funciona. "@192.168.1.254" especifica o servidor dns a ser usado. "www.slackware.com" é o nome de domínio que eu estou verificando, e "mx" é o tipo de verificaçăo que eu estou fazendo. A query acima me diz que quando enviar um e-mail para www.slackware.com ele será enviado na verdade, para mail.slackware.com.
O finger(1) irá retornar informaçőes sobre o usuário especificado. Vocę utiliza o finger em um username ou em um endereço de e-mail e ele irá tentar contactar o servidor necessário e retornar o username, escritório, número de telefone, e outras informaçőes. Aqui está um exemplo:
$ finger <johnc (a) idsoftware com>
O finger pode retornar o username, status de e-mail, número de telefones, e o conteúdo dos arquivos ".plan" e ".project". Claro que a informaçăo retornada varia conforme cada servidor finger. Aquele que está incluso no Slackware retorna as seguintes informaçőes por padrăo:
Os primeiros quatro itens podem ser configurados com o comando chfn. Ele guarda essas informaçőes no arquivo /etc/passwd. Para mudar a informaçăo no seu arquivo .plan ou .project, basta editar esses arquivos com seu editor de texto favorito. Esses arquivos precisam estar no seu diretório home e precisam ser chamados .plan e .project obrigatoriamente.
Muitos usuários utilizam finger na sua própria conta de uma máquina remota para ver rapidamente se possuem novos e-mails. Vocę também pode utilizá-lo para ver os planos de um usuário ou o seu projeto atual.
Como muitos comandos, finger possui opçőes. Olhe a página de manual dele para maiores informaçőes sobre opçőes que vocę pode usar.
Alguém uma vez disse que o telnet(1) tinha sido a coisa mais legal que já havia visto em computadores. A habilidade de logar remotamente e realizar tarefas em outro computador é o que separa o Unix e sistemas operacionais "Unix-like" de outros sistemas operacionais.
O telnet permite que vocę logue em um computador, assim como se vocę estivesse sentado em frente ao mesmo. Depois de ter seu usuário e senha verificados, vocę terá um prompt do shell. Depois disso, vocę pode fazer qualquer coisa que um console em modo texto permitir. Compor e-mail, ler grupo de notícias, mover arquivos, e assim por diante. Se vocę estiver rodando o X e fizer telnet para outra máquina, vocę pode rodar aplicativos do X no computador remoto e mostrar o resultado no seu computador.
Para logar em uma máquina remota, use a seguinte sintaxe:
$ telnet <hostname>
Se o host responder, vocę receberá o prompt de login. Digite seu usuário e sua senha. Pronto. Vocę agora possui uma shell. Para sair da sua sessăo telnet, use o comando exit ou o comando logout.
AVISO: telnetnăo encripta a informaçăo que transmite. Tudo é transmitido em texto puro, até mesmo senhas. Năo é recomendado usar telnet através da Internet. Para tal, considere usar o ssh (Secure Shell). Ele encripta todo o tráfego e está disponível gratuitamente.
Agora que nós convencemos vocę a năo utilizar o protocolo telnet para logar em uma máquina remota, nós iremos mostrar algumas outras utilidades do telnet.
Vocę também pode usar o telnet para conectar em um host em uma certa porta.
$ telnet <hostname> [port]
Isso pode ser bem útil quando vocę precisa rapidamente testar um certo serviço, e vocę precisa de total controle sobre os comandos, além de ver precisamente o que está acontecendo. Vocę pode testar interativamente ou usar um servidor SMTP, um servidor POP3, um servidor HTTP, etc. dessa forma.
Na próxima figura vocę verá como vocę pode usar telnet em um servidor HTTP na porta 80, e conseguir algumas informaçőes básicas dele:
Usando telnet em um servidor web
$ telnet store.slackware.com 80
Trying 69.50.233.153...
Connected to store.slackware.com.
Escape character is '^]'.
HEAD / HTTP/1.0
HTTP/1.1 200 OK
Date: Mon, 25 Apr 2005 20:47:01 GMT
Server: Apache/1.3.33 (Unix) mod_ssl/2.8.22 OpenSSL/0.9.7d
Last-Modified: Fri, 18 Apr 2003 10:58:54 GMT
ETag: "193424-c0-3e9fda6e"
Accept-Ranges: bytes
Content-Length: 192
Connection: close
Content-Type: text/html
Connection closed by foreign host.
$
Vocę pode fazer a mesma coisa para qualquer outro protocolo que seja de texto puro, desde que saiba em que porta conectar e quais săo seus comandos.
Hoje, o ssh desfruta da adoraçăo que o telnet desfrutou uma vez. ssh(1) nos permite realizar conexőes em uma máquina remota e executar programas como se vocę estivesse fisicamente presente; contudo, o ssh encripta todos os dados transferidos entre os dois computadores. Dessa forma, mesmo que outras pessoas interceptem a comunicaçăo, eles năo serăo capazes de entendę-la. Uma conexăo ssh típica está abaixo:
$ ssh carrier.lizella.net -l alan
The authenticity of host 'carrier.lizella.net (192.168.1.253)' can't be
established.
RSA key fingerprint is 0b:e2:5d:43:4c:39:4f:8c:b9:85:db:b2:fa:25:e9:9d.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'carrier.lizella.net' (RSA) to the list of
known hosts.
Password: password
Last login: Sat Nov 6 16:32:19 2004 from 192.168.1.102
Linux 2.4.26-smp.
alan@carrier:~$ ls -l MANIFEST
-rw-r--r-- 1 alan users 23545276 2004-10-28 20:04 MANIFEST
alan@carrier:~$ exit
logout
Connection to carrier.lizella.net closed.
Acima vocę pode perceber que eu estou fazendo uma conexăo ssh em carrier.lizella.net, e checando as permissőes do arquivo MANIFEST.
O correio eletrônico é uma das coisas mais populares que vocę pode fazer na Internet. Em 1998 descobriu-se que mensagens eletrônicas eram mais utilizadas que o correio normal. Ele é certamente muito comum e útil.
No Slackware, nós fornecemos um servidor de email padrăo, e muitos clientes de email. Todos os clientes discutidos abaixo săo utilizados em modo texto. Muitos dos usuários Windows podem ser contra isso, mas vocę descobrirá que um cliente utilizado em modo texto é muito conveniente, especialmente quando vocę está checando email remotamente. Năo tema pois existem diversos clientes gráficos como o Kmail do KDE. Se vocę deseja usar um desses, verifique o menu de ajuda dos mesmos.
O pine(1) năo é o elm. A Universidade de Washington criou o seu programa para ler emails e notícias da Internet e ao mesmo tempo ser um leitor fácil para seus estudantes. O pine é um dos clientes de email mais populares hoje em uso e está disponível para todos os sabores de Unix e até mesmo Windows.

Vocę verá um menu de comandos e uma linha de teclas de comando na parte de baixo da tela. Contudo o pine é um programa complexo, e nós năo iremos discutir todos os seus recursos neste texto.
Para ver o que está na sua caixa de entrada, digite i. Suas mensagens săo listadas com suas datas, autores e assuntos. Selecione a mensagem que vocę deseja e aperte enter para visualizá-la. Digitando r vocę poderá responder a mensagem. Após digitar a mensagem de resposta, digite Ctrl+X para enviá-la. Vocę pode digitar i para voltar ŕ lista de mensagens.
Se vocę deseja excluir a mensagem, digite d. Isso irá marcar a mensagem selecionada para exclusăo. O pine apaga as mensagens quando vocę sai do programa. O pine também permite que vocę guarde seus emails em pastas. Vocę pode obter a listagem das pastas pressionando a tecla l. Na listagem de mensagens, pressione s para salvá-la em outra pasta. Ele irá perguntar em qual pasta deve salvar a mensagem.
O pine oferece muitas, muitas funcionalidades; vocę definitivamente deve dar uma olhada na página de manual para maiores informaçőes. Ele irá conter as últimas informaçőes sobre o programa.
elm(1) é outro cliente de email em modo texto bastante popular. Apesar de năo possuir uma interface tăo amigável quanto o pine, está por aí há muito mais tempo.
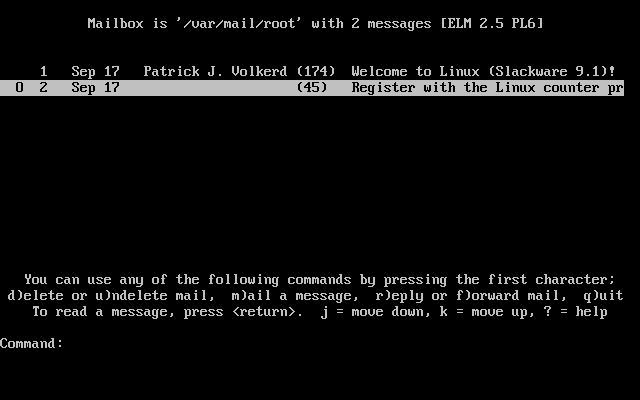
Por padrăo vocę está na sua caixa de entrada. As mensagens săo listadas com o número da mensagem, data, autor e assunto. Use as setas para selecionar a mensagem que deseja. Pressione Enter para ler a mensagem.
Para compor uma nova mensagem, pressione m na tela principal. A tecla d irá marcar a mensagem para exclusăo. E a tecla r irá responder a mensagem que vocę está atualmente lendo. Todas essas teclas săo mostradas na parte de baixo da tela com um prompt.
A página de manual apresenta o elm mais detalhadamente, entăo vocę provavelmente irá consultá-lo antes de utilizar o elm.
"Todos os clientes de email săo ruins. Este é apenas menos ruim". A interface original do mutt era baseada na interface do elm com recursos adicionais encontrados em outros clientes de email populares, resultando em um mutt híbrido.
Alguns dos recursos do mutt incluem:
Tela principal do Mutt
Se vocę está procurando por um cliente de email que irá permitir que vocę tenha total controle sobre tudo, entăo vocę irá gostar do mutt. Todas as configuraçőes padrăo podem ser customizadas, associaçőes de teclas mudadas. Se vocę quiser adicionar uma macro, vocę também pode.
Vocę provavelmente irá querer dar uma olhada na página de manual do muttrc, que irá explicar como configurar tudo isso. Ou dę uma olhada no exemplo de arquivo de configuraçăo muttrc.
nail(1) é um cliente de email de linha de comando. É muito primitivo e oferece quase nenhum recurso no que diz respeito ŕ interface com usuário. Contudo, mailx é útil para aquelas vezes em que vocę precisa rapidamente enviar alguma coisa, testando sua instalaçăo de MTA ou qualquer coisa parecida. Note que o Slackware cria um link simbólico para o nail em /usr/bin/mail e /usr/bin/mailx. Qualquer um desses tręs comandos executa o mesmo programa. De fato, vocę verá normalmente o nail sendo referenciado como mail.
A linha de comando básica é:
$ mailx <subject> <to-addr>
mailx lę o corpo da mensagem da entrada padrăo. Entăo vocę pode usar o cat em um arquivo como entrada padrăo para este comando para enviá-lo, ou vocę pode apenas digitar o texto e apertar Ctrl+D quando tiver acabado a mensagem.
Aqui está um exemplo de enviar por email o código fonte de um programa para outra pessoa:
$ cat randomfunc.c | mail -s "Here's that function" <asdf (a) example net>
A página de manual explica mais do que o nail pode fazer, entăo vocę provavelmente irá querer dar uma olhada nele antes de usá-lo
A primeira coisa que as pessoas pensam quando ouvem a palavra Internet é "navegar na internet". Em outras palavras, navegar em sites usando um navegador web. Esse é provavelmente de longe o uso mais popular da Internet para o usuário médio.
O Slackware fornece navegadores web que săo gráficos na série "XAP", bem como navegadores web em modo texto na série "N". Nós iremos dar uma rápida olhada nas opçőes mais comuns.
lynx(1) é um navegador web em modo texto. É uma forma bem rápida de olhar alguma coisa na Internet.
Para iniciar o lynx, apenas digite lynx no prompt:
$ lynx
Página inicial padrăo do Lynx
Vocę pode querer especificar um site para o lynx abrir:
$ lynx http://www.slackware.com
lynx exibe as teclas de comando e o que cada tecla faz na parte de baixo da tela. As setas para cima e para baixo movem através do documento, Enter seleciona o link destacado, e a seta da esquerda volta ŕ página anterior. Digitando d irá fazer o download do arquivo selecionado. O comando g traz o prompt de endereço, para vocę digitar uma URL para o lynx abrir.
Existem muitos outros comandos no lynx. Vocę pode consultar a página de manual ou digitar h para que a tela de ajuda apareça para maiores informaçőes.
Assim como no lynx, o links é um navegador em modo texto, onde vocę navega utilizando o teclado. Contudo, quando pressiona a tecla Esc, irá ativar um menu muito conveniente no topo da tela. Isso permite que o links seja muito fácil de usar, sem ter que aprender um monte de teclas de atalho. Pessoas que năo utilizam navegadores em modo texto todo dia irăo gostar deste recurso.
O links parece ter um suporte melhor para frames e tabelas, quando comparado ao lynx.
wget(1) é uma ferramenta de linha de comando que irá fazer o download de arquivos de uma URL específica. Como năo é na verdade um navegador web, o wget é usado principalmente para fazer o download de sites inteiros ou parte deles para visualizaçăo offline dos mesmos, ou para o download de arquivos de servidores HTTP ou FTP. A sintaxe básica é:
$ wget <url>
Vocę também pode passar opçőes. Por exemplo, a opçăo abaixo irá fazer o download do site do Slackware:
$ wget --recursive http://www.slackware.com
O wget irá criar um diretório chamado //www.slackware.com// e irá guardar os arquivos dentro dele, assim como o site o faz.
O wget também pode fazer o download de sites FTP; apenas especifique uma URL FTP ao invés de uma HTTP.
$ wget ftp://ftp.gnu.org/gnu/wget/wget-1.8.2.tar.gz
--12:18:16-- ftp://ftp.gnu.org/gnu/wget/wget-1.8.2.tar.gz
=> `wget-1.8.2.tar.gz'
Resolving ftp.gnu.org... done.
Connecting to ftp.gnu.org[199.232.41.7]:21... connected.
Logging in as anonymous ... Logged in!
==> SYST ... done. ==> PWD ... done.
==> TYPE I ... done. ==> CWD /gnu/wget ... done.
==> PORT ... done. ==> RETR wget-1.8.2.tar.gz ... done.
Length: 1,154,648 (unauthoritative)
100%[==================================>] 1,154,648 209.55K/s ETA 00:00
12:18:23 (209.55KB/s) - `wget-1.8.2.tar.gz' saved [1154648]
O wget tem muitas outras opçőes, o que o torna muito bom para scripts específicos para sites (como espelhamento e assim por diante). A página de manual deve ser consultado para mais informaçőes.
O FTP é o protocolo de transferęncia de arquivos. Ele permite que vocę envie e receba arquivos entre dois computadores. Existe o servidor FTP e o cliente FTP. Nós iremos falar sobre os clientes nesta seçăo. Para os curiosos, o "cliente" é vocę. O "servidor" é o computador que responde suas requisiçőes FTP e aceita o seu login. Vocę irá fazer o download de arquivos do servidor e irá fazer upload de arquivos para o servidor. O cliente năo pode aceitar conexőes FTP, ele pode apenas conectar ŕ servidores FTP.
Para conectar em um servidor FTP, simplesmente execute o comando ftp(1) e especifique o host:
$ ftp <hostname> [port]
Se o host estiver rodando um servidor FTP, ele irá pedir um username e um password. Vocę poderá logar como vocę mesmo ou como "anônimo" (anonymous). Sites FTP anônimos săo bastante populares para repositório de arquivos. Por exemplo, para fazer o download do Slackware Linux por FTP, vocę deve usar FTP anônimo.
Uma vez conectado, vocę estará no prompt ftp>. Existem comandos especiais para FTP, mas eles săo similares aos comandos padrăo. A lista seguinte mostra alguns dos comandos básicos e o que eles fazem:
Comandos ftp
| Comando | Funçăo |
| ls | Lista arquivos |
| cd <diretório> | Muda de diretório |
| bin | Define modo de transferęncia binário |
| ascii | Define modo de transferęncia ASCII |
| get <arquivo> | Faz o download de um arquivo |
| put <arquivo> | Faz o upload de um arquivo |
| hash | Liga/Desliga a impressăo de "#" para cada buffer transferido |
| tick | Mostra/Esconde contador de bytes |
| prom | Entra/Sai modo interativo para downloads |
| mget <arquivos> | Faz o download de um arquivo ou um grupo de arquivos; coringas săo permitidos |
| mput <arquivos> | Faz o upload de um arquivo ou um grupo de arquivos; coringas săo permitidos |
| quit | Sai do servidor FTP |
Vocę também pode usar os seguintes comandos, que săo auto-explicativos: chmod, delete, rename, rmdir. Para uma lista completa de todos os comandos e seus significados, apenas digite help ou ? e vocę verá a lista completa na sua tela.
FTP é um programa razoavelmente simples de ser usado, mas falta a interface que muitos de nós estăo acostumados hoje em dia. A página de manual discute algumas das opçőes de linha de comando do ftp(1).
ftp> ls *.TXT
200 PORT command successful.
150 Opening ASCII mode data connection for /bin/ls.
-rw-r--r-- 1 root 100 18606 Apr 6 2002 BOOTING.TXT
-rw-r--r-- 1 root 100 10518 Jun 13 2002 COPYRIGHT.TXT
-rw-r--r-- 1 root 100 602 Apr 6 2002 CRYPTO_NOTICE.TXT
-rw-r--r-- 1 root 100 32431 Sep 29 02:56 FAQ.TXT
-rw-r--r-- 1 root 100 499784 Mar 3 19:29 FILELIST.TXT
-rw-r--r-- 1 root 100 241099 Mar 3 19:12 PACKAGES.TXT
-rw-r--r-- 1 root 100 12339 Jun 19 2002 README81.TXT
-rw-r--r-- 1 root 100 14826 Jun 17 2002 SPEAKUP_DOCS.TXT
-rw-r--r-- 1 root 100 15434 Jun 17 2002 SPEAK_INSTALL.TXT
-rw-r--r-- 1 root 100 2876 Jun 17 2002 UPGRADE.TXT
226 Transfer complete.
ftp> tick
Tick counter printing on (10240 bytes/tick increment).
ftp> get README81.TXT
local: README81.TXT remote: README81.TXT
200 PORT command successful.
150 Opening BINARY mode data connection for README81.TXT (12339 bytes).
Bytes transferred: 12339
226 Transfer complete.
12339 bytes received in 0.208 secs (58 Kbytes/sec)
O ncftp(1) (pronunciado "Nik-F-T-P") é uma alternativa ao tradicional cliente ftp que vem com o Slackware. Ele é ainda um programa em modo texto, mas oferece algumas vantagens em relaçăo ao ftp, incluindo:
Por padrăo, ncftp irá tentar logar anonimamente ao servidor que vocę especificar. Vocę pode forçar o ncftp a apresentar o prompt de login com a opçăo "-u". Uma vez no sistema, vocę pode usar os mesmos comandos usados no ftp, vocę irá apenas notar uma interface melhor, que se parece mais com o bash.
ncftp /pub/linux/slackware > cd slackware-current/
Please read the file README81.TXT
it was last modified on Wed Jun 19 16:24:21 2002 - 258 days ago
CWD command successful.
ncftp ...ware/slackware-current > ls
BOOTING.TXT FAQ.TXT bootdisks/
CHECKSUMS FILELIST.TXT extra/
CHECKSUMS.asc GPG-KEY isolinux/
CHECKSUMS.md5 PACKAGES.TXT kernels/
CHECKSUMS.md5.asc PRERELEASE_NOTES pasture/
COPYING README81.TXT rootdisks/
COPYRIGHT.TXT SPEEKUP_DOCS.TXT slackware/
CRYPTO_NOTICE.TXT SPEEK_INSTALL.TXT source/
CURRENT.WARNING Slackware-HOWTO
ChangeLog.txt UPGRADE.TXT
ncftp ...ware/slackware-current > get README81.TXT
README81.TXT: 12.29 kB 307.07 kB/s
wall(1) é uma forma rápida de escrever uma mensagem para os usuários em um sistema. A sintaxe básica é:
$ wall [file]
Isso irá fazer com que o conteúdo do arquivo seja mostrado no terminal de todos os usuários atualmente logados no sistema. Se vocę năo especificar uma mensagem, wall irá ler da entrada padrăo, entăo vocę pode simplesmente digitar sua mensagem e no final digitar Ctrl+d.
wall năo possui muitos recursos, tirando o fato de servir para avisar a seus usuários que vocę está prestes a fazer alguma manutençăo séria no sistema, ou até mesmo reiniciá-lo, para que eles salvem seus trabalhos e façam logoff =)
O talk(1) permite que dois usuários conversem entre si. Ele divide a tela no meio, horizontalmente. Para requisitar um chat com outro usuário, use o comando:
$ talk <pessoa> [ttyname]

Se vocę especificar apenas o usuário, o talk assume que a requisiçăo é local, entăo apenas usuários locais săo requisitados. O nome do terminal é requerido se vocę deseja chamar um usuário em um terminal específico (se o usuário está logado em mais de um). A informaçăo requerida para a conversa pode ser obtida com o comando w(1).
O talk também pode chamar usuários em hosts remotos. Para o username vocę simplesmente especifica um endereço de email. talk irá tentar contactar aquele usuário remoto naquele host.
talk é um pouco limitado. Ele somente suporta dois usuários e é half-duplex.
ytalk(1) é uma reposiçăo do talk. Ele vem com o Slackware como sendo o comando ytalk. A sintaxe é similar, mas existem algumas diferenças:
$ ytalk <username>[#ttyname]
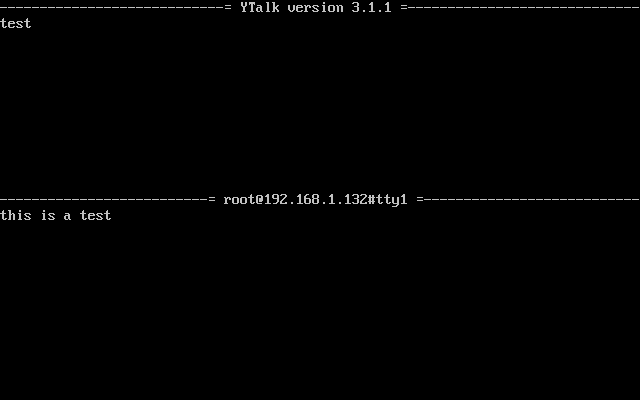
O usuário e o terminal săo especificados da mesma forma que no talk, com a diferença que vocę deve colocá-los juntos com o caractere (#).
ytalk oferece várias vantagens:
Se vocę é um administrador de servidores, vocę deve se certificar que a porta do ntalk está habilitada em /etc/inetd.conf. ytalk precisa disso para funcionar corretamente.
Segurança em um sistema é uma característica muito importante: ela pode prevenir que pessoas ataquem sua máquina, e também proteger dados sigilosos. Esse capítulo inteiro é dedicado a como proteger sua máquina Slackware contra script kiddies, crackers e outros ladrőes de informaçőes. Tenha em mente de que esse é só o começo de como proteger um sistema; segurança é um processo, năo um estado.
O primeiro passo após instalar o Slackware deve ser desabilitar todos os serviços que vocę năo vai precisar. Qualquer serviço pode ser um risco de segurança, entăo é importante deixar habilitado o mínimo de serviços possíveis (ou seja, só os que săo necessários). Os serviços săo iniciados a partir de duas ferramentas principais o inetd e os scripts de inicializaçăo (init scripts).
Muitos daemons que vem com o Slackware săo iniciados a partir do inetd(8). O inetd é um daemon que escuta em todas as portas usadas pelos serviços configurados para serem iniciados por ele e inicia uma estância do daemon relevante quando uma tentativa de conexăo é feita. Daemons iniciados pelo inetd podem ser desabilitados comentando-se a linha referente ao mesmo no arquivo /etc/inetd.conf. Para fazer isso, abra esse arquivo no seu editor de textos favorito (ex. vi) e vocę verá linhas similares a essa:
telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd
Vocę pode desabilitar esse serviço, e qualquer outro que năo seja necessário para vocę, comentado-os (ou seja, incluindo um # (sustenido) ao início da linha). A linha acima ficaria assim:
#telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd
Depois que o inetd for reiniciado, esse serviço estará desabilitado. Vocę pode reiniciar o inetd com o comando:
# kill -HUP $(cat /var/run/inetd.pid)
Os outros serviços iniciados durante o boot da máquina săo iniciados a partir dos scripts contidos em /etc/rc.d/. Esses podem ser desabilitados de duas maneiras: a primeira seria remover a permissăo de execuçăo do script de inicializaçăo desejado e a segunda seria comentar as linhas relevantes no script de inicializaçăo.
Por exemplo, o SSH é iniciado pelo seu próprio script /etc/rc.d/rc.sshd. Vocę pode desabilitá-lo usando:
# chmod -x /etc/rc.d/rc.sshd
Para os serviços que năo possuem seu próprio script de inicializaçăo, vocę precisará comentar as linhas relativas a eles em algum outro script de inicializaçăo para desabilitá-los. Por exemplo, o daemon portmap é iniciado pelas seguintes linhas do arquivo /etc/rc.d/rc.inet2:
# This must be running in order to mount NFS volumes.
# Start the RPC portmapper:
if [ -x /sbin/rpc.portmap ]; then
echo "Starting RPC portmapper: /sbin/rpc.portmap"
/sbin/rpc.portmap
fi
# Done starting the RPC portmapper.
Esse serviço pode ser desabilitado adicionando um # ao inicio das linhas que ainda năo começam com #, assim:
# This must be running in order to mount NFS volumes.
# Start the RPC portmapper:
#if [ -x /sbin/rpc.portmap ]; then
# echo "Starting RPC portmapper: /sbin/rpc.portmap"
# /sbin/rpc.portmap
#fi
# Done starting the RPC portmapper.
Essas mudanças apenas terăo efeito após um reboot ou mudando para o runlevel 3 ou 4. Vocę pode fazer isso digitando o seguinte em um console (vocę precisará se logar novamente após mudar para o runlevel 1):
# telinit 1
# telinit 3
O iptables é o programa de configuraçăo de filtros de pacotes para o Linux 2.4 e superior. O kernel 2.4 (2.4.5, para ser exato) foi introduzido no Slackware (como uma opçăo) na versăo 8.0 e tornou-se o padrăo no Slackware 8.1. Essa seçăo cobre apenas o básico de sua utilizaçăo e vocę pode acessar o site http://www.netfilter.org/ para mais detalhes. Esses comandos podem ser colocados no arquivo /etc/rc.d/rc.firewall, o qual deve ter permissăo de execuçăo para que essas regras tenham efeito na inicializaçăo. Note que comandos incorretos do iptables podem até mesmo te impedir de acessar sua própria máquina. A menos que vocę esteja 100% confiante de suas habilidades, sempre tenha certeza de que vocę tem acesso local a máquina.
A primeira coisa que a maior parte das pessoas devem fazer é configurar a politica padrăo para cada método de entrada para DROP:
# iptables -P INPUT DROP
# iptables -P FORWARD DROP
Quando tudo é barrado, vocę pode começar a liberar coisas. A primeira coisa a liberar é o trafego para seçőes que já estavam estabelecidas:
# iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
E para năo impedir qualquer aplicaçăo que use o endereço de loopback, é inteligente adicionar a seguinte regra:
# iptables -A INPUT -s 127.0.0.0/8 -d 127.0.0.0/8 -i lo -j ACCEPT
Essa regra permite qualquer tráfego para e a partir do endereço 127.0.0.0/8 (127.0.0.0 - 127.255.255.255) na interface de loopback (lo). Quando for criar regras, é uma boa idéia ser o mais específico possível, para ter cereza de que suas regras năo văo permitir inadvertidamente algo malicioso. Dito isso, regras que permitem pouco resultam em mais regras e mais digitaçăo.
O próximo passo seria permitir o acesso a serviços específicos que rodem em sua máquina. Se, por exemplo, vocę quisesse rodar um servidor web na sua máquina, vocę usaria uma regra similar a essa:
# iptables -A INPUT -p tcp --dport 80 -i ppp0 -j ACCEPT
Isso permitirá o acesso de qualquer máquina ŕ porta 80 da sua máquina através da interface ppp0. Vocę pode querer restringir o acesso a esse serviço para que apenas certas máquinas possam acessá-lo. Essa regra permite o acesso ao seu servidor web a partir do endereço 64.57.102.34:
# iptables -A INPUT -p tcp -s 64.57.102.34 --dport 80 -i ppp0 -j ACCEPT
Permitir o tráfego ICMP pode ser útil para efeitos de diagnóstico. Para fazer isso, vocę usuaria uma regra como essa:
# iptables -A INPUT -p icmp -j ACCEPT
Muitas pessoas também văo querer configurar o serviço de Traduçăo de Endereços de Rede (Network Address Translation - NAT) em suas máquinas que atuem como gateway, para que outras máquinas na sua rede possam acessar a Internet através dela. Vocę pode usar a seguinte regra para fazer isso:
# iptables -t nat -A POSTROUTING -o ppp0 -j MASQUERADE
Vocę também precisará habilitar o IP forwarding. Vocę pode fazer isso temporariamente, usando o seguinte comando:
# echo 1 > /proc/sys/net/ipv4/ip_forward
Para habilitar o IP forwarding de uma forma permanente (ou seja, para que a mudança seja mantida após o reboot), vocę precisará abrir o arquivo /etc/rc.d/rc.inet2 em seu editor de textos favorito e mudar a seguinte linha:
IPV4_FORWARD=0
...para isso:
IPV4_FORWARD=1
Para mais informaçőes sobre NAT, veja o NAT HOWTO.
Os tcpwrappers controlam o acesso aos daemons de acordo com a aplicaçăo, e năo de acordo com o IP. Isso pode trazer uma camada extra de segurança quando controles de acesso por IP (ex. Netfilter) năo estăo funcionando corretamente. Por exemplo, se vocę recompilar o kernel mas esquecer de incluir o suporte ao iptables, sua proteçăo no nível de IP falhará mas os tcpwrappers ainda o ajudarăo a proteger o seu sistema.
Os acessos aos serviços protegidos pelos tcpwrappers podem ser controlados usando os arquivos /etc/hosts.allow e /etc/hosts.deny.
A maioria das pessoas poderăo ter uma única linha em seus arquivos /etc/hosts.deny para barrar o acesso a todos os daemons como padrăo. Essa linha ficaria assim:
ALL : ALL
Quando isso é feito, vocę pode se concentrar em permitir o acesso a serviços para máquinas, domínios, ou faixas de IP específicos. Isso pode ser feito no arquivo /etc/hosts.allow, que segue o mesmo formato.
Muitas pessoas começariam aceitando todas as conexőes do localhost. Isso pode ser feito da seguinte forma:
ALL : 127.0.0.1
Para permitir o acesso ao SSHd a partir dos endereços 192.168.0.0/24, vocę poderá usar qualquer uma das duas regras a seguir:
sshd : 192.168.0.0/24 sshd : 192.168.0.
Também é possível restringir o acesso a máquinas em certos domínios. Isso pode ser feito usando a seguinte regra (note que isso se apoia na veracidade da entrada de DNS reverso para a máquina que está conectando, logo eu năo recomendaria seu uso em máquinas conectadas a Internet):
sshd : .slackware.com
Sempre que um problema de segurança afeta o Slackware, um email é mandado a todos os assinantes da lista através do endereço <slackware-security (a) slackware com>. Relatórios săo enviados sobre vulnerabilidades em qualquer parte do Slackware, menos as relativas aos pacotes contidos no /extra ou no /pasture. Esses emails de notificaçăo de segurança incluem detalhes sobre como obter as versőes atualizadas dos pacotes do Slackware ou work-arounds, se existirem.
Informaçőes sobre como se inscrever nas listas de email do Slackware podem ser encontradas na Seçăo 2.7.
Sempre que săo liberados pacotes atualizados para uma versăo do Slackware (normalmente para corrigir um problema de segurança, no caso de versőes do Slackware já liberadas), eles săo colocados no diretório /patches. O caminho completo para esses patches vai depender do mirror que vocę estiver utilizando, mas terăo a seguinte forma /caminho/para/slackware-x.x/patches/.
Antes de instalar esses pacotes, é uma boa idéia verificar o md5sum do pacote. O md5sum(1) é um utilitário de linha de comando que cria uma "chave" matemática "única" para o arquivo. Se um único bit do arquivo tiver sido modificado, ele gerará um valor diferente de md5sum para o arquivo.
$ md5sum package-<ver>-<arch>-<rev>.tgz
6341417aa1c025448b53073a1f1d287d package-<ver>-<arch>-<rev>.tgz
Vocę deverá comparar esse valor com o valor contido no arquivo CHECKSUMS.md5 na raiz do diretório slackware-$VERSION (também contido no diretório /patches para os patches) ou no email da lista slackware-security para o pacote em questăo.
Se vocę tiver um arquivo com os valores md5sum nele, vocę pode usa-lo como fonte dos md5sum com a opçăo -c do comando md5sum.
# md5sum -c CHECKSUMS.md5
./ANNOUNCE.10_0: OK
./BOOTING.TXT: OK
./COPYING: OK
./COPYRIGHT.TXT: OK
./CRYPTO_NOTICE.TXT: OK
./ChangeLog.txt: OK
./FAQ.TXT: FAILED
Como vocę pode ver, qualquer arquivo com o md5sum correto é listado como <quote>OK</quote> enquanto os arquivos que estăo com o md5sum incorreto săo listados como "FAILED". (Sim, isso foi um insulto a sua inteligęncia. Porque vocę mexeu comigo?)
O gzip(1) é o programa de compressăo da GNU. Ele recebe um arquivo e entăo o comprime. Seu uso básico é como a seguir:
$ gzip nome_do_arquivo
O nome do arquivo resultante será nome_do_arquivo.gz// e ele geralmente será menor que o arquivo de entrada. Observe que nome_do_arquivo será substituído por nome_do_arquivo.gz. Isto significa que nome_do_arquivo năo existirá mais, somente existirá sua cópia comprimida. Arquivos texto regulares serăo bem compactados, enquanto que imagens jpeg, arquivos mp3 e outros arquivos como estes năo serăo tăo compactados, pois eles já estăo em um formato compactado. Esta forma básica de usar o programa de compressăo mantém um balanceamento entre o tamanho final do arquivo e o tempo de compressăo. A compressăo máxima pode ser obtida da seguinte maneira:
$ gzip -9 nome_do_arquivo
Desta maneira a compressăo do arquivo será mais lenta, mas o arquivo resultante será tăo pequeno quanto ogzip é capaz de comprimí-lo. Usando valores mais baixos na opçăo do comando, a compressăo será mais rápida, mas o arquivo năo será tăo compactado.
Para descomprimir arquivos compactados com o gzip podem ser usados dois comandos, que săo na verdade um mesmo programa. gzip irá descomprimir qualquer arquivo com um extensăo reconhecida. As extensőes reconhecidas săo: .gz, -gz, .z, -z, .Z, ou -Z. A primeira maneira é executar gunzip(1) sobre um arquivo, da seguinte forma:
$ gunzip nome_do_arquivo.gz
Isto irá deixar, no diretório corrente, uma versăo descomprimida do arquivo de entrada, e a extensăo .gz será retirada do nome do arquivo. gunzip é de fato parte do gzip e é idęntico a gzip -d. Dessa forma, gzip é geralmente pronunciado gunzip, uma vez que o nome soa mais legal assim. :^)
O bzip2(1) é um programa de compressăo alternativo instalado no Slackware Linux. Ele utiliza um algoritmo de compressăo diferente do utilizado em gzip, o que resulta em algumas vantagens e algumas desvantagens. A principal vantagem em favor de bzip2 é o tamanho do arquivo compactado. bzip2 quase sempre irá comprimir melhor que gzip. Em alguns casos, isto pode resultar em arquivos dramaticamente menores. Isto pode ser uma grande vantagem para pessoas com conexőes lentas. Também lembre-se que, ao copiar um programa de um servidor FTP público, é, em geral, uma boa regra de etiqueta na Internet pegar arquivos .bz2 em vez de arquivos .gz, já que isto resulta em uma menor sobrecarga, ajudando assim as generosas pessoas que hospedam o servidor.
A desvantagem de bzip2 é que ele utiliza mais recursos de processamento do que o gzip. Isto significa que descomprimir um arquivo com bzip2 geralmente será mais demorado e utilizará mais o processador do que o gzip o faria. Na escolha de um programa de compressăo a ser usado, vocę precisa considerar o tempo de compressăo e o tamanho do arquivo compactado e determinar o que é mais importante.
O uso de bzip2 é quase idęntico ao uso de gzip, de maneira que năo será gasto muito tempo discutindo isso. Como gunzip, bunzip2 é idęntico a bzip2 -d. A principal diferença na prática é que bzip2 usa a extensăo .bz2.
$ bzip2 //nome_do_arquivo//
$ bunzip2 //nome_do_arquivo.bz2//
$ bzip2 -9 //nome_do_arquivo//
tar(1) é o arquivador em fita da GNU (as fitas já foram a principal mídia para armazenar grandes volumes de dados!). Neste contexto, arquivar significar agrupar e comprimir um conjunto de arquivos para transferęncia ou armazenamento. O tar recebe como entrada vários arquivos ou diretórios e cria um único grande arquivo, também chamado de pacote. Isto lhe permite comprimir uma árvore de diretório inteira, o que é impossível apenas utilizando gzip ou bzip2. O tar tem muitas opçőes de linha de comando, que săo explicadas na página de manual correspondente. Esta seçăo irá abordar apenas os casos mais comuns de uso do tar.
O uso mais comum para o tar é extrair (descomprimir e desagrupar) um pacote que vocę copiou de um servidor WEB ou FTP. A maioria desses pacotes terăo a extensăo .tar.gz. Um pacote é comumente conhecido como um tarball. Isto significa que vários arquivos foram agrupados utilizando-se o tar e entăo compactados com o gzip. Vocę também poderá encontrar tais pacotes com a extensăo .tar.Z. Esta extensăo significa a mesma coisa, mas é geralmente encontrada em sistemas Unix mais antigos. Por outro lado, vocę pode encontrar um pacote com a extensăo .tar.bz2 em algum lugar. O código fonte do kernel (núcleo do sistema operacional) é distribuído desta forma, pois o pacote resultante é menor. Como vocę pode ter imaginado, esse pacote resulta de vários arquivos compactados com o bzip2 e agrupados com o tar. Vocę pode obter todos os arquivos neste pacote utilizando o tar com alguns parâmetros. Para se desempacotar um tarball utiliza-se a opçăo -z como parâmetro, o que significa que o gunzip será utilizado para descomprimir os arquivos. A maneira mais comum para descomprimir e separar os arquivos de tais pacotes é a seguinte:
$ tar -xvzf nome_do_arquivo.tar.gz
Săo absolutamente poucas opçőes. Entăo o que elas significam? A opçăo -x significa extrair. Ela é importante, uma vez que diz exatamente para o tar o que fazer com o arquivo de entrada. Neste caso, nós dividiremos o pacote separando de volta os arquivos que foram agrupados. O -v significa ser detalhado, ao invés de ser resumido. Dessa forma, serăo listados todos os arquivos que estăo sendo desagrupados. É perfeitamente aceitável năo usar esta opçăo se ela for algo que lhe incomoda. De outra forma, vocę poderia usar -vv para a execuçăo ser muito mais detalhada e listar ainda mais informaçőes sobre cada arquivo sendo extraído. A opçăo -z diz ao tar para primeiro descomprimir o pacote nome_do_arquivo.tar.gz com o gunzip. E finalmente, a opçăo -f indica ao tar que a próxima seqüencia de caracteres na linha de comando representa o nome do arquivo sobre o qual ele executará as operaçőes.
Existem algumas outras maneiras de se escrever este comando. Em sistemas mais antigos carentes de uma cópia decente do GNU tar, vocę pode encontrá-lo expresso assim:
$ gunzip nome_do_arquivo.tar.gz | tar -xvf -
Este comando irá descomprimir o arquivo e enviar a saída para o tar. Uma vez que o gzip escreverá sua saída na saída padrăo se assim lhe for inidicado, este comando escreverá o arquivo descompactado na saída padrăo. O redirecionamento (|) entăo envia esta saída para o tar para desagrupamento. O - indica para o comando operar sobre a entrada padrăo. Ele irá desagrupar o fluxo de dados que receber do gzip, escrevendo a saída no disco.
Outra maneira de escrever o primeiro comando é retirando-se o traço que vem antes das opçőes, como a seguir:
$ tar xvzf nome_do_arquivo.tar.gz
Vocę também pode encontrar um pacote compactado com bzip2. A versăo do tar que vem com o Slackware Linux pode manipular esses pacotes assim como os compridos com gzip. Ao contrário da opçăo -z, vocę deve usar -j:
$ tar -xvjf nome_do_arquivo.tar.bz2
É importante notar que o tar colocará os arquivos extraídos no diretório corrente. Entăo, se vocę tem um pacote em /tmp que vocę quer extrair no seu diretório pessoal, existem poucas opçőes. Primeiro, poderia-se mover o pacote para o seu diretório pessoal e entăo executar o tar sobre ele. Segundo, vocę poderia especificar o caminho para o pacote na linha de comando. Terceiro, vocę pode usar a opçăo -C para explodir o pacote em um determinado diretório.
$ cd $HOME
$ cp /tmp/nome_do_arquivo.tar.gz .
$ tar -xvzf nome_do_arquivo.tar.gz
$ cd $HOME
$ tar -xvzf /tmp/nome_do_arquivo.tar.gz
$ cd /
$ tar -xvzf /tmp/nome_do_arquivo.tar.gz -C $HOME
Todos os comandos acima săo equivalentes. Em cada caso, os arquivos do pacote săo extraídos em seu diretório pessoal e o pacote original compactado permanecerá em seu lugar inicial.
Sendo assim, o que adiante ser capaz de extrair estes pacotes se vocę năo é capaz de criar um deles? Bem, o comando tar também cuida disso. Na maioria dos casos isto é tăo fácil quanto remover a opçăo -x e substituí-la pela opçăo -c.
$ tar -cvzf nome_do_arquivo.tar.gz .
Neste comando, a opçăo -c diz ao tar para agrupar os arquivos criando um pacote, enquanto que a opçăo -z executa o gzip sobre o pacote para comprimí-lo. nome_do_arquivo.tar.gz será o nome do pacote que vocę quer criar.
Năo é sempre necessário especificar a opçăo -f, mas de qualquer maneira é uma boa prática fazę-lo. Sem isso, o comando tar envia sua saída para a saída padrăo, o que é geralmente desejável para redirecionamento da saída do tar para outro programa, como a seguir.
$ tar -cv . | gpg --encrypt
Este comando cria um pacote năo compactado que agrupa o conteúdo do diretório corrente e entăo redireciona esse pacote para o gpg que criptografa e comprime o pacote, fazendo com que seja praticamente impossível sua leitura por outra pessoa além daquela que conhece a chave secreta.
Por fim, existem dois utilitários que podem ser usados em arquivos zip. Estes arquivos săo muito comuns no mundo Windows, de maneira que o Linux tem programas para lidar com eles. O arquivo de compressăo é denominado zip(1), e o de descompressăo é denominado unzip(1).
$ zip teste *
Isto criará o arquivo teste.zip, que irá conter todos os arquivos do diretório corrente. O zip adicionará a extensăo .zip automaticamente, de forma que năo há necessidade de incluí-la no nome do arquivo. Vocę também pode recursivamente comprimir os subdiretórios existentes:
$ zip -r teste *
Bem como, descomprimir arquivos também é fácil.
$ unzip teste.zip
Isto irá extrair todos os arquivos e diretórios no arquivo teste.zip.
Os utilitários zip tęm várias opçőes avançadas para criar pacotes que podem se extrair automaticamente, excluir arquivos, controlar o tamanho do arquivo compactado, mostrar o que acontecerá e muito mais. Veja as páginas de manual dos comandos zip e unzip para descobrir como usar essas opçőes.
O vi(1) é o programa editor de texto padrăo do Unix, e apesar de que dominá-lo năo seja tăo essencial quanto já foi, é ainda algo que vale a pena. Há algumas versőes (ou clones) do vi disponíveis, incluindo vi, elvis,vile, e o vim.
Ao menos um destes está disponível em qualquer versăo do Unix, assim como no Linux. Todas estas versőes incluem os mesmos recursos e comandos básicos, logo, aprender a usar um clone deve facilitar o aprendizado de outro. Com a variedade de editores de texto inclusos nas distribuiçőes do Linux e variantes do Unix atualmente, muitas pessoas năo utilizam mais o vi. De qualquer maneira, ele permanece sendo o editor de texto mais universal do Unix e sistemas derivados. Dominar o vi significa que vocę nunca mais se sentará diante de uma máquina Unix e năo se sentirá confortável com pelo menos um poderoso editor de texto.
O vi inclui diversos recursos como o destaque de sintaxe, formataçăo de código, um poderoso mecanismo de busca e substiuiçăo, macros e outros. Estes recursos o fazem especialmente atrativo para programadores, desenvolvedores web e afins. Administradores de sistema văo apreciar a possível automaçăo e integraçăo com o shell.
No Slackware Linux, a versăo padrăo do vi disponível é o elvis. Outras versőes - incluindo o vim e o gvim - estăo disponíveis se vocę tiver os pacotes apropriados instalados. O gvim é uma versăo gráfica do vim que inclui barras de tarefas, menus destacáveis e caixas de diálogo.
O vi pode ser iniciado a partir da linha de comando de várias maneiras. A mais simples dela é apenas:
$ vi
Uma sessăo do vi.
Isto irá iniciar o vi com um buffer vazio. Neste ponto, vocę verá uma tela com quase nada escrito. O vi está agora no modo de comando, esperando alguma açăo sua. Para uma discussăo dos diversos modos do vi, veja a seçăo 16.2. Para finalizar a sessăo e sair do vi, digite o seguinte:
:q
Assumindo que năo tenha havido modificaçőes no arquivo, este comando irá fechar o vi. Se houve modificaçőes, este comando irá adverti-lo e lhe dizer como ignorá-las. Ignorar modificaçőes usualmente significa anexar um ponto de exclamaçăo após o q resultando em:
:q!
O ponto de exclamaçăo usualmente significa forçar alguma açăo. Nós discutiremos esta e outras combinaçőes mais adiante.
Vocę também pode inciar o vi com um arquivo pré-existente. Por exemplo, o arquivo /etc/resolv.conf poderia ser aberto da seguinte maneira:
$ vi /etc/resolv.conf
E finalmente, o vi pode ser iniciado em uma linha particular de um arquivo. Isto é especialmente útil para programadores quando uma mensagem de erro inclui a linha na qual houve o erro. Por exemplo, vocę poderia iniciar o vi na linha 47 do arquivo /usr/src/linux/init/main.c da seguinte maneira:
$ vi +47 /usr/src/linux/init/main.c
O vi mostrará o arquivo especificado e irá colocar o cursor na linha especificada. No caso em que vocę especificar uma linha que esteja após o final do arquivo, o vi colocará o cursor na última linha. Isto é especialmente útil para programadores, pois eles podem pular exatamente para o local no arquivo no qual ocorreu um erro, sem ter que procurar por ele.
O vi opera em vários modos, que săo usados para cumprir várias tarefas. Quando vocę inicia o vi, vocę é colocado dentro do modo de comando. Deste ponto, vocę pode lançar diversos comandos para manipular texto, mover-se pelo arquivo, salvar, sair, e alternar entre os outros modos. A ediçăo de texto é feita em modo de inserçăo. Vocę pode rapidamente alternar entre os modos com uma variedade de combinaçőes de teclas, que săo explicadas abaixo.
Ao entrar no vi vocę é primeiramente colocado no modo de comando. A partir deste modo, vocę năo pode digitar texto ou editar algo que já esteja na tela diretamente. Entretanto, vocę pode manipular o texto, pesquisar, fechar, salvar, carregar novos arquivos e muito mais. O texto que segue será apenas uma introduçăo ao modo de comando. Para uma descriçăo dos vários comandos, veja seçăo 16.7.
Provavelmente o comando mais usado no modo de comando é a alternaçăo para o modo de inserçăo. Isto é feito pressionando-se a tecla i. O cursor muda de formato, e "-- INSERT --" é mostrado no inferior da tela (note que isto năo acontece em todos os clones do vi). De lá, todas os caracteres digitados săo enviados ao buffer corrente e săo mostrados na tela. Para voltar ao modo de comando, pressione a tecla ESCAPE.
O modo de comando é também usado ao mover-se pelo arquivo. Em alguns sistemas, vocę pode usar as setas do teclado para mover-se. Em outros sistemas, vocę pode precisar usar as teclas hjkl. Aqui está uma simples listagem de como as teclas săo usadas para mover-se pelo arquivo:
| h | move-se um caractere ŕ esquerda |
| j | move-se para um caractere abaixo |
| k | move-se para um caractere acima |
| l | move-se um caractere ŕ direita |
Simplesmente pressione uma tecla para mover-se. Como vocę verá posteriormente, estas teclas podem ser combinadas com um número para mover-se de forma mais eficiente.
Muitos dos comandos que vocę usará no modo de comando iniciam-se com dois-pontos. Por exemplo, para sair, teclamos :q, como explicado anteriormente. Os dois-pontos simplesmente indicam que trata-se de um comando, enquanto que a letra q diz ao vi para encerrar a sessăo e sair. Outros comandos săo formados por um número opcional, seguido por uma letra. Estes comandos năo tem dois-pontos antes deles, e geralmente săo usados para manipular o texto.
Por exemplo, para apagarmos uma linha de um arquivos digitamos dd. Isto irá remover a linha na qual está o cursor. Lançando o comando 4dd diria ao vi para remover a linha na qual está o cursor e as 3 seguintes. Em geral, o número diz ao vi quantas vezes executar o comando dado.
Vocę pode combinar um número com as teclas de movimento para mover-se por vários caracteres de uma só vez. Por exemplo, 10k moveria o cursor 10 linhas acima na tela.
O modo de comando também pode ser usado para copiar e colar, inserir texto e ler outros arquivos no buffer corrente. Para copiar um trecho do texto usamos a tecla y (y vem da palavra inglesa yank, que em portugues significa "arrancar", "extrair"). Para copiarmos a linha corrente teclamos yy, e este comando pode ser prefixado com um número para extrair mais linhas. Entăo, mova-se para o local para o qual o texto extraido deve ser copiado e pressione a tecla p. O texto é colado na linha posterior ŕ linha corrente.
Para cortar uma parte do texto digitamos dd, e a tecla p pode ser usada para colar o texto recortado novamente no arquivo. Ler texto de outro arquivo é um procedimento simples. Apenas digite :r, seguido por um espaço e o nome do arquivo que contém o texto a ser inserido. O conteúdo do arquivo será colado no buffer corrente na linha após a que se encontra o cursor. Os clones mais sofisticados do vi também contém complementaçăo de nome de arquivo similiar ŕ do shell.
O uso final que será mostrado é a pesquisa. O modo de comando permite pesquisas simples, assim como comandos complicados de busca e substituiçăo que usufruem de uma poderosa versăo de expressőes regulares. Uma completa discussăo sobre expressőes regulares está além do escopo deste capítulo, logo, esta seçăo cobrirá somente simples meios de pesquisa.
Uma simples busca é feita pressionando-se a tecla /, seguida do texto pelo qual vocę está procurando. O vi irá fazer a pesquisa do ponto em que está o cursor até o fim do arquivo, parando no momento em que a pesquisa for satisfeita. Note que buscas inexatas irăo fazer com que o vi pare. Por exemplo, uma busca por "the" irá fazer com que o vi pare em "then", "therefore", e em outras palavras. Isto acontece porque todas estas palavras contęm o trecho de pesquisa "the".
Após o vi encontrar o primeiro termo que casa com o termo de pesquisa, vocę pode continuar pesquisando pelo termo simplesmente pressionando a tecla / seguida de um enter. Vocę também pode pesquisar se o termo de pesquisa existe em algum trecho anterior ŕ localizaçăo do cursor substituindo a barra pelo caractere ?. Por exemplo, para procurar por "the" em algum ponto anterior ao cursor, digitamos ?the.
A inserçăo e substituiçăo de texto é feita no modo de inserçăo. Como discutido anteriormente, vocę pode ir para o modo de inserçăo pressionando a tecla i no modo de comando. Entăo, todo o texto que vocę digita é enviado ao buffer corrente. Pressionar a tecla ESCAPE lhe levará ao modo de comando.
A substituiçăo de texto pode ser feita de algumas maneiras. Da linha de comando, pressionando-se a tecla r permitirá que vocę substitua um caractere que está sob o cursor. Apenas digite o novo caractere e ele substituirá o caractere que está sob o cursor pelo caractere digitado. Vocę será entăo imediatamente mandado devolta ao modo de comando. Pressionando-se a tecla R vocę poderá substituir quantos caracteres vocę quiser. Para sair deste modo de substituiçăo, apenas tecle ESCAPE para retornar ao modo de comando.
Ainda há outra maneira de se alternar entre o modo de inserçăo e o de substituiçăo. Pressionando-se a tecla INSERT a partir do modo de comando, vocę será levado ao modo de inserçăo. Uma vez que vocę se encontra no modo de inserçăo, a tecla INSERT servirá como uma tecla de alternância entre o modo de inserçăo e substituiçăo. Ao pressioná-la pela primeira vez vocę estará no modo de substituiçăo. Pressionando-a novamente vocę será enviado ao modo de inserçăo.
O vi permite que vocę abra arquivos a partir do modo de comando assim como se especifica a abertura de um arquivo pela linha de comando. Para abrir o arquivo /etc/lilo.conf:
:e /etc/lilo.conf
Se vocę tiver feito alteraçőes no buffer corrente que năo tenham sido salvas, o vi irá reclamar. Vocę ainda pode abrir o arquivo sem salvar o buffer corrente digitando :e!, seguido de um espaço e do nome do arquivo. Em geral, as advertęncias do vi podem ser suprimidas adicionando-se um ponto de exclamaçăo no final do comando.
Se vocę quiser reabrir o arquivo corrente, vocę pode fazę-lo simplesmente digitando e!. Isto é particularmente útil caso vocę tenha bagunçado o arquivo de alguma maneira e queira reabri-lo.
Alguns clones do vi (por exemplo, o vim) permitem que múltiplos buffers sejam abertos ao mesmo tempo. Por exemplo, para abrir o arquivo 09-vi.sgml que está no meu diretório home enquanto outro arquivo está aberto, eu poderia digitar:
:split ~/09-vi.sgml
O novo arquivo é exibido na metade superior da tela, e o arquivo que já estava aberto é exibido na metade inferior da tela. Há vários comandos para manipulaçăo da tela dividida, e muitos destes comandos lembram o Emacs O melhor lugar para procurar por estes comandos seria a página de manual do seu clone do vi. Note que muitos clones năo suportam a idéia de divisăo de tela, entăo vocę pode năo estar apto a utilizá-la.
Há algumas maneiras de se salvar arquivos no vi. Se vocę quiser salvar o buffer corrente para o arquivo bah, vocę poderia digitar:
:w bah
Uma vez que vocę tenha salvado o arquivo pela primeira vez, para salvá-lo novamente basta digitar :w. Qualquer alteraçăo será gravada no arquivo. Após vocę ter salvado o arquivo, vocę é jogado de volta para dentro do modo de comando. Se vocę quiser salvar o arquivo e encerrar o vi (uma operaçăo muito comum), vocę podeira digitar :wq. Que diz ao vi para salvar o buffer corrente para o arquivo e encerrar a sessăo, voltando ao shell.
Se por acaso, vocę quiser salvar um arquivo cujas permissőes sejam apenas de leitura, vocę poderia fazę-lo adicionando um ponto de exclamaçăo após o comando de gravaçăo, da seguinte forma:
:w!
Entretanto, haverá casos em que vocę năo poderá gravar no arquivo (por exemplo, caso vocę esteja tentando editar um arquivo que seja de outro usuário). Quando isto acontecer, o vi irá lhe dizer que năo foi possível salvar o arquivo. Se vocę realmente quiser editar o arquivo, vocę terá que editá-lo como usuário root ou (de preferęncia) como o usuário dono do arquivo.
Uma maneira de encerrar o vi é através do comando :wq, que irá salvar o buffer corrente para o arquivo antes de encerrar a sessăo. Vocę também pode encerrar a sessăo sem salvar as alteraçőes feitas no arquivo com o comando :q ou (mais comum) com o comando :q!. A segunda maneira é utilizada quando vocę tiver modificado o arquivo, mas năo desejar salvar as alteraçőes feitas.
Pode acontecer da sua máquina ou o vi travarem. Entretanto, ambos elvis e o vim tentam minimizar os danos. Ambos os editores salvam ocasionalmente o buffer aberto para um aquivo temporário. Este arquivo é usualmente nomeado de forma similar ao arquivo aberto, mas com um ponto no início do nome. Isto faz com que o arquivo seja oculto.
Este arquivo temporário é removido uma vez que o editor é encerrado sob condiçőes normais. Isto significa que a cópia temporária existirá para o caso de haver algum problema. Quando vocę voltar a editar o arquivo novamente, vocę será questionado sobre qual açăo tomar. Na maioria dos casos, uma larga quantia do seu trabalho năo salvo pode ser recuperada. O elvis também lhe enviará um e-mail informando da existęncia de uma cópia de backup.
O seu clone do vi pode ser configurado de várias maneiras.
Uma variedade de comandos podem ser dados no modo de comando para configurar o vi do jeito que vocę gosta. Dependendo do seu editor, vocę pode habilitar recursos para facilitar a programaçăo (como o destaque de sintaxe, auto-identaçăo, e outros mais), configurar macros para automatizar tarefas, habilitar substituiçőes textuais, e muito mais.
Quase todos estes comandos podem ser colocados dentro de um arquivo de configuraçăo no seu diretório home. No elvis seria o arquivo .exrc, enquanto que no vim seria o arquivo .vimrc. A maioria dos comandos de configuraçăo que podem ser digitados no modo de comando, podem ser colocados no arquivo de configuraçăo. Isto inclui informaçőes de configuraçăo, substituiçőes textuais, macros, e mais.
A discussăo de todas essas opçőes e as diferenças entre os editores é um assunto muito complicado. Para maiores informaçőes, verifique a página de manual ou o site do seu editor vi predileto. Alguns editores (como o vim) possuem uma extensa documentaçăo dentro do editor que pode ser acessada com o comando :help, ou algo similar. Vocę também pode checar o livro da O'Reilly chamado Learning the //vi Editor// escrito por Lamb e Robbins.
Muitos programas comuns do Linux carregarăo um arquivo texto no vi por padrăo. Por exemplo, ao se editar as tarefas agendadas do sistema (crontabs) será iniciado o vi por padrăo. Se vocę năo gosta do vi e gostaria que outro editor fosse iniciado ao invés dele, tudo o que vocę precisa fazer é setar a variável de ambiente VISUAL para o editor de sua preferęncia. Para maiores informaçőes sobre como setar variáveis de ambiente, veja a seçăo chamada Variáveis de Ambiente no capítulo 8. Se vocę deseja ter certeza de que o seu editor será o padrăo toda vez que vocę logar-se, adicione sete a variável VISUAL dentro dos seus arquivos .bash_profile ou .bashrc.
Esta seçăo é uma referęncia rápida aos comandos mais comuns do vi. Alguns destes já foram discutidos anteriormente no capítulo, enquanto outros năo.
Movimento
| Operaçăo | Tecla |
| esquerda, abaixo, acima, direita | h, j, k, l |
| Para o fim da linha | $ |
| Para o início da linha | ^ |
| Para o fim do arquivo | G |
| Para o início do arquivo | :1 |
| Para a linha 47 | :47 |
Editando
| Operaçăo | Tecla |
| Removendo uma linha | dd |
| Removendo cinco linhas | 5dd |
| Substituindo um caractere | r |
| Removendo um caractere | x |
| Removendo dez caracteres | 10x |
| Defazer a última açăo | u |
| Unir linhas atual e seguintes | J |
| Substituir velho por novo, globalmente | %s'velho'novo'g |
Localizando
| Operaçăo | Tecla |
| Procurar por asdf | /asdf |
| Procurar atrás por asdf | ?asdf |
| Repetir a última busca para frente | / |
| Repetir a última busca para trás | ? |
| Repetir a última busca, na mesma direçăo | n |
| Repetir a última busca, na direçăo oposta | N |
Salvando e Saindo
| Operaçăo | Tecla |
| Sair | :q |
| Sair sem salvar | :q! |
| Salvar e sai | :wq |
| Salvar, sem sair | :w |
| Recarregar o arquivo atualmente aberto | :e! |
| Salvar o buffer para um arquivo asdf | :w asdf |
| Abrir o arquivo hejaz | :e hejaz |
| Ler o arquivo asdf dentro do buffer | :r asdf |
| Ler a saída do comando ls dentro do buffer | :r !ls |
Enquanto o vi (juntamente com seus clones) é sem dúvida o editor mais presente em sistemas derivados do Unix, O Emacs vem em segundo lugar. Ao invés de usar diferentes "modos", como o vi, ele utiliza combinaçőes das teclas Control e Alt para dar comandos, da mesma forma que vocę pode usar combinaçőes das teclas Control e Alt em um outro processador de textos e em muitas outras aplicaçőes afim de executar certas funçőes. (Apesar de ser notável que os comandos raramente se correspondem; entăo enquanto muitas aplicaçőes modernas utilizam Ctrl C / X/ V para copiar, recortar e colar, o Emacs utiliza teclas diferentes e atualmente um mecanismo um tanto quanto diferente para isto.)
Também diferentemente do vi, que é um (excelente) editor e nada mais, o Emacs é um programa com quase infinitas capacidades. O Emacs é (em sua maior parte) escrito em linguagem Lisp, que é uma linguagem de programaçăo muito poderosa que tem a característica peculiar de que todo programa escrito nela é automaticamente um compilador Lisp em si. Isto significa que o usuário pode estender o Emacs, e de fato escrever programas inteiramente novos no Emacs.
Como resultado disto, o Emacs năo é mais somente um editor. Há muitos pacotes adicionais para o Emacs disponíveis (o código fonte do programa vem com o programa) que provęem todas as espécies de funcionalidades. Muitos destas săo relacionados ŕ ediçăo de texto, que é dentre todas as demais, a tarefa básica do Emacs mas que năo se limitam a isto. Existem por exemplo alguns programas de planilhas eletrônicas para o Emacs, base de dados, jogos, clientes de e-mail e notícias (sendo o Gnus o mais famoso deles), etc.
Existem duas versőes principais do Emacs: O GNU Emacs (que é a versăo que vem com o Slackware) e o XEmacs. O último năo é uma versăo do Emacs para rodar sob o X. De fato, ambos Emacs e XEmacs rodam no console assim como sob o X. O XEmacs foi iniciado como um projeto para limpar e arrumar o código fonte do Emacs. Atualmente, ambas as versőes estăo sendo ativamente desenvolvidas, e há de fato muita interaçăo entre os dois times de desenvolvimento. Para o capítulo presente, é indiferente se vocę usa o Emacs ou o XEmacs, as diferenças entre eles năo săo relevantes para o usuário final.
O Emacs pode ser inciado no shell simplesmente digitando-se emacs. Se vocę estiver rodando o X, o Emacs irá (normalmente) surgir com sua própria janela, usualmente com uma barra de menu no topo, onde vocę pode encontrar as funçőes mais importantes. Na inicializaçăo, o Emacs irá primeiramente mostrar uma mensagem de boas vindas, e entăo após alguns segundos ele irá jogá-lo no *scratch* buffer. (veja seçăo 17.2).
Vocę também pode iniciar o Emacs com um arquivo existente digitando
$ emacs /etc/resolv.conf
Isto fará com que o Emacs carregue o arquivo especificado quanto inciar, pulando a mensagem de boas vindas.
Como mencionado acima, o Emacs utiliza combinaçőes das teclas Control e Alt para comandos. A convençăo usual é escrever estes com C letra e M- letra, respectivamente. Entăo C x significa Control x, e M- x significa Alt x. (A letra M- é usada ao invés de A porque originalmente năo existia a tecla Alt e sim a tecla Meta. A tecla Meta desapareceu dos teclados dos computadores, e no Emacs a tecla Alt tomou entăo a sua funçăo.)
Muitos comandos do Emacs consistem de sequęncias e combinaçőes de teclas. Por exemplo, C x C c (que é Control x seguida de Control c) encerra o Emacs, C x C ssalva o arquivo atual. Mantenha em mente que C x C b năo é o mesmo que C x b. A primeira significa Control x seguida de Control b, enquanto a segunda significa Control x seguida apenas de 'b'.
No Emacs, o conceito de buffers é essencial. Todo arquivo que vocę abre é carregado em seu próprio buffer. Além disto, o Emacs possui alguns buffers especiais, que năo contém um arquivo, mas săo usados para outras coisas. Tais buffers especiais usualmente tęm um nome que começa e termina com um asterisco. Por exemplo, o buffer que o Emacs mostra quando é primeiramente inciado, é o tăo famoso *scratch* buffer.
No *scratch* buffer, vocę pode digitar texto normalmente, mas o texto que é digitado năo é salvo quando o Emacs é fechado.
Há um outro buffer especial sobre o qual vocę precisa saber, e este é o minibuffer. Este buffer consiste de apenas uma linha, e está sempre na tela: ele é a última linha da janela do Emacs, abaixo da barra de status para o buffer em uso. O minibuffer é onde o Emacs mostra mensagens para o usuário, e é também o lugar onde os comandos, que requerem alguma entrada do usuário, săo executados. Por exemplo, quando vocę abre um arquivo, o Emacs irá perguntar pelo nome do arquivo no minibuffer. A Mudança de um buffer para outro pode ser feita com o comando C x b. Isto irá questioná-lo sobre o nome de um buffer (o nome de um buffer é geralmente o nome do arquivo que vocę está editando nele), é dado uma escolha padrăo, que é normalmente o nome do buffer no qual vocę esteve antes de ter mudado para, ou criado, o buffer atual. Vocę será mandado para este buffer padrăo caso pressione a tecla Enter.
Se vocę deseja ir para outro buffer que năo seja o padrăo sugerido pelo Emacs, basta que vocę digite o nome do buffer desejado. Note que vocę pode usar a tăo famosa tecla Tab para fazer a completaçăo de nome aqui: digite as primeiras letras do nome do buffer e pressione a tecla Tab; O Emacs irá entăo completar o nome do buffer. A completaçăo com a tecla Tab funciona em todas as partes do Emacs em que ela faça sentido.
Vocę pode obter uma lista dos buffers abertos pressionando-se C x C b. Este comando irá usualmente dividir a tela em duas, mostrando o buffer no qual vocę estava trabalhando na metade superior da tela, e o novo buffer chamado *Buffer List* na metade inferior da tela. Este buffer contém uma lista de todos os buffers, seus tamanhos e modos, e os arquivos, se houver algum que aqueles buffers listados estejam visitando. Vocę pode sair desta tela dividida digitando C x 1.
Nota: Sob o X, a lista de buffers também está disponível no menu Buffer na barra de menu.
Todo buffer no emacs tem a si associado, um modo. Este modo é muito diferente da idéia de modos do vi: um modo lhe diz em que tipo de buffer vocę se encontra. Por exemplo, existe o modo texto (text-mode) para arquivos normais de texto, porém existem também modos tais como o modo c (c-mode) para ediçăo de programas escritos em C, modo sh (sh-mode) para ediçăo de shell scripts, modo latex (latex-mode) para ediçăo de arquivos latex, modo mail (mail-mode) para ediçăo de e-mail, notícias, mensagens e etc. Um modo provę customizaçőes e funcionalidades especiais que săo úteis para o tipo de arquivo que vocę está editando. Também é possível para um modo, a redefiniçăo de teclas e comandos. Por exemplo, no modo texto, a tecla Tab simplesmente pula para a próxima tabulaçăo e pára, mas em muitos modos de linguagens de programaçăo, a tecla Tab identa a linha atual de acordo com a pronfundidade do bloco no qual a linha se encontra.
Os modos mencionados acima săo chamados de modos principais. Cada buffer tem exatamente um modo principal. Adicionalmente, um buffer pode ter um ou mais modos secundários. Um modo secundário provę recursos adicionais que podem ser úteis para certas tarefas de ediçăo. Por exemplo, se vocę pressiona a tecla INSERT, vocę invoca o modo de subscriçăo (overwrite-mode), que faz o que vocę supőe que faça. Há também um modo de auto preenchimento (auto-fill-mode), que é útil em combinaçăo com o modo texto (text-mode) ou com o modo latex (latex-mode): ele fará com que cada linha que vocę digita seja automaticamente embalada, uma vez que a linha alcance um certo número de caracteres. Sem o modo de auto preenchimento (auto-fill-mode), vocę teria que digitar M- q para preencher um parágrafo. (Que vocę pode também utilizar para reformatar um parágrafo após ter editado algum texto e ele tenha deixado de ser preenchido.)
Para abrir um arquivo no Emacs, digite:
C-x C-f
O Emacs irá lhe perguntar o nome do arquivo que vocę deseja abrir, preechendo algum caminho padrăo para vocę (que é usualmente ~/). Após vocę digitar o nome do arquivo que deseja abrir (vocę também pode usar aqui a tecla Tab para completar) e pressionar a tecla ENTER , o Emacs irá abrir o arquivo em um novo buffer e mostrar este buffer na tela.
Nota: O Emacs irá automaticamente criar um novo buffer, ele năo irá carregar o arquivo no buffer atual.
Para criar um novo arquivo no Emacs, vocę năo pode apenas ir digitando algo. Vocę primeiramente deve criar um buffer para ele, e dar um nome para o arquivo. Vocę faz isso digitando C x C f e digitando um nome para o arquivo, exatamente como se vocę estivesse abrindo um arquivo existente. O Emacs irá notar que o arquivo cujo nome vocę digitou năo existe, e criará um novo buffer e informar a criaçăo de um novo arquivo (New file) no minibuffer.
Quando vocę digita C x C f e entăo entra com um nome de um diretório ao invés de um nome de arquivo, o Emacs irá criar um novo buffer no qual vocę irá encontrar uma lista de todos os arquivos existentes naquele diretório. Vocę pode mover o cursor para o arquivo que vocę está procurando e digitar, e o Emacs irá abrí-lo. (Há de fato muitas outras açőes que pode tomar aqui, tais como apagar, renomear e mover arquivos, etc. O Emacs está agora no dired-mode, que é basicamente um simples gerenciador de arquivos.)
Quando vocę estiver digitado C-x C-fe derepente mudar de idéia, vocę pode digitar C-g para cancelar a açăo. C-g funciona em quase todo lugar que vocę desejar cancelar uma açăo ou comando que vocę estiver iniciado mas que năo queira terminar.
Quando vocę tiver aberto um arquivo, vocę obviamente poderá mover-se ele com o cursor. As teclas do cursor e PgUp, PgDn fazem o que vocę possa supor. Home e End pulam para o início e final da linha. (Em versőes mais antigas, elas podem pular para o início e fim do buffer.) Entretanto, há também a combinaçăo das teclas Control e Meta (Alt) para mover o cursor. Porque vocę năo precisa mover suas măos para outra parte do teclado para utilizá-las, elas săo muito mais facilmente acessíveis uma vez que vocę se acostume com elas. Os mais importantes comandos semelhantes estăo listados na tabela abaixo.
Comandos Básicos de Ediçăo
| Comando* | Resultado** |
| C-b | volta um caractere |
| C-f | avança um caractere |
| C-n | vai para a linha abaixo |
| C-p | vai para a linha acima |
| C-a | vai para o início da linha |
| C-e | vai para o fim da linha |
| M-b | vai para a palavra anterior |
| M-f | vai para a palavra seguinte |
| M-} | vai para o parágrafo seguinte |
| M-{ | vai para o parágrafo anterior |
| M-a | vai para a sentença anterior |
| M-e | vai para a sentença seguinte |
| C-d | apaga o caractere sob o cursor |
| M-d | apagar até o fim da palavra atual |
| C-v | abaixa uma tela (assim como a tecla., PgDn) |
| M-v | sobe uma tela (assim como a tecla., PgUp) |
| M-< | vai para o início do buffer |
| M-> | vai para o fim do buffer |
| C-_ | desfaz a última alteraçăo (pode ser repetido); note que vocę realmente tem que digitar Shift Control hyphen para isto. |
| C-k | apaga até o fim da linha atual |
| C-s | efetua uma busca ŕ frente do cursor até o fim do arquivo |
| C-r | efetua uma busca anteriormente ao cursor até o início do arquivo |
Note que muitos comandos com a tecla Meta săo paralelos aos comandos com a tecla Control exceto pelo fato de que eles operam em amplas unidades: enquanto C-f avança um caractere, M-f avança em uma palavra inteira, etc.
Também note que M-<** e M-> requerem que vocę digite Shift Alt comma e Shift Alt dot respectivamente, desde que < e > estejam ligadas Shift comma e Shift dot.(A menos é claro que vocę tenha um teclado em condiçőes diferentes (layout), do teclado padrăo US.)
Note que C k apagar (apaga, como é freqüentemente chamada) todo o texto após o cursor até o fim da linha, porém năo apaga a linha em si (por exemplo, năo apaga a indicaçăo de nova linha). Ele apenas apaga a linha se năo houver texto após o cursor. Em outras palavras, para apaga uma linha completamente, vocę tem que posicionar o cursor no início e pressionar C k duas vezes: uma para apaga o texto na linha e uma para apagar a linha em si.
Para salvar um arquivo, vocę deve digitar
C-x C-s
O Emacs năo irá lhe solicitar um nome para o arquivo, o buffer atual apenas será salvo para o arquivo que foi carregado inicialmente nele. Se vocę deseja salvar o seu texto em outro arquivo, digite
C-x C-w
Quando vocę salva o arquivo pela primeira vez nesta sessăo, o Emacs irá normalmente salvar a antiga versăo do seu arquivo em uma cópia de segurança (arquivo de backup), que possui o mesmo nome acompanhado de um sinal de til (~): entăo se vocę está editando um arquivo //cars.txt//, o Emacs criará uma cópia de segurança chamada //cars.txt~//. Esta cópia de segurança é uma cópia do arquivo que vocę abriu. Enquanto vocę estiver trabalhando, o Emacs irá regularmente criar automaticamente uma cópia do trabalho que vocę está fazendo, para um arquivo nomeado com sinais de hash: #cars.txt#. Esta cópia de segurança é apagada quando vocę salva o arquivo com C-x C-s. Quando vocę tesiver finalizado a ediçăo de um arquivo, vocę poderá matar o buffer que contém o arquivo digitado
C-x k
O Emacs irá perguntar a vocę qual buffer vocę deseja matar, com o buffer atual como padrăo, o qual vocę pode selecionar simplesmente pressionando a tecla ENTER. Se vocę năo estiver salvado seu arquivo ainda, o Emacs irá lhe perguntar se realmente deseja matar o buffer.
Quando vocę estiver terminado todo o trabalho com o Emacs, vocę poderá digitar
C-x C-c
Este comando encerra o Emacs. Se vocę estiver arquivos năo salvos, o Emacs irá lhe dizer isto, e pedir para que vocę os salve, um por vez. Se vocę responder năo para algum destes, o Emacs irá lhe solicitar uma confirmaçăo final e entăo sair.
Um pacote de software é um conjunto de arquivos que estăo prontos para que vocę possa instalar. Quando vocę faz o download de um código fonte, vocę precisa configurar, compilar, e instalar tudo manualmente. Um pacote de software já está pronto para vocę utilizar. Tudo o que vocę precisa fazer é instalar o pacote. Outras características do uso de pacotes de softwares săo a facilidade na remoçăo e atualizaçăo do pacote, se vocę assim o desejar. Slackware possui programas para vocę gerenciar seus pacotes. Vocę pode instalar, remover, atualizar, criar, e examinar o conteúdo de um pacote muito facilmente.
Existe um mito sobre o gerenciador de Pacotes da Red Hat, e que o slackware năo possui nenhuma ferramenta de gerenciamento de Pacotes. Isto simplesmente năo é verdade, pois o Slackware possui uma ferramenta de gerenciamento de pacotes antes mesmo do RedHat existir. Năo possui tantas característics como um rpm (ou como um pacote deb), o pkgtool e seus programas derivados săo tăo bons quanto os instaladores de pacotes rpm. A verdade é que o pkgtool năo faz nenhuma verificaçăo de dependęncia.
Aparentemente muitas pessoas da comunidade Linux acham que a definiçăo do gerenciamento de pacotes é a de verificar dependęncias. Isto é muito simples e năo é o caso, no Slackware certamente vocę năo terá isso. Isso năo significa que os pacotes do Slackware năo possuem dependęncias, mas o gerenciador de pacotes năo verifica se existe uma dependęncia. Gerenciamento de dependęncia é responsabilidade do Administrador de Sistemas, e isso năo cabe a nós resolver.
Antes de aprender os utilitários de pacotes do Slackware, vocę precisa se familiarizar com o formato do pacote do Slackware. No Slackware, um pacote é simples como um arquivo tar compactado com gzip. Os pacotes săo feitos para serem extraídos no diretório raiz.
Veja um programa fictício como um exemplo de um pacote do Slackware:
./
usr/
usr/bin/
usr/bin/makehejaz
usr/doc/
usr/doc/makehejaz-1.0/
usr/doc/makehejaz-1.0/COPYING
usr/doc/makehejaz-1.0/README
usr/man/
usr/man/man1
usr/man/man1/makehejaz.1.gz
install/
install/doinst.sh
O pacote será extraído no diretório raíz na instalaçăo. Um registro do pacote é adicionado no banco de dados de pacotes onde conterá informaçőes sobre o pacote e será utilizado para atualizar ou remover o pacote posteriormente.
Informaçőes sobre o subdiretório install/. Este é um diretório especial que contém um script de pós-instalaçăo chamado doinst.sh. Se o sistema encontrar esse arquivo no pacote, ele será executado após a instalaçăo do pacote.
Outros scripts podem ser adicionados no pacote mas serăo discutidos com maiores detalhes logo em seguida.
Existem quatro utilitários principais para o gerenciamento de pacotes. Eles săo responsáveis pela instalaçăo, remoçăo e atualizaçăo dos pacotes.
pkgtool(8) é um programa em formato de menu que permite instalar e remover pacotes. O menu principal é exibido na figura abaixo.
Menu Principal do Pkgtool
A instalaçăo é realizada a partir do diretório atual, outro diretório, ou a partir de disquetes. Basta simplesmente selecionar o tipo de instalaçăo que o pkgtool irá procurar pacotes válidos para serem instalados no local selecionado.
Vocę também pode visualizar uma lista de todos os pacotes instalados como é mostrado na figura abaixo.
Modo de visualizaçăo Pkgtool
Caso vocę desejar remover algum pacote, escolha a opçăo remover e entăo serăo apresentados todos os pacotes instalados cada um com um checklist. Selecione os pacotes que deseja remover e entăo selecione OK. O pkgtool removerá os pacotes.
Alguns usuários preferem o utilitário em linha de comando. Entretanto, deve-se notar que cada linha de comando oferece muito mais opçőes. Além disso, a capacidade para atualizar pacotes somente é possível através de utilitários de linha de comando.
O installpkg(8) permite instalar um novo pacote no sistema. A sintaxe é mostrada abaixo:
# installpkg opçőes nome_pacote
Tręs opçőes podem ser utilizadas com o installpkg. Porém somente uma opçăo pode ser utilizada por vez.
Opçőes do installpkg
| Opçăo | Descriçăo |
| -m | Executa o makepkg no diretório atual. |
| -warn | Mostra o que aconteceria se vocę instalar o pacote especificado. Isto é útil para sistemas em produçăo assim vocę pode ver exatamente o que aconteceria antes de instalar algo. |
| -r | Instala todos os pacotes recursivamente a partir do diretório atual. Pode-se utilizar coringas nos nomes dos pacotes, usando uma máscara para instalar pacotes recursivamente. |
Caso vocę especifique antes a variável de ambiente ROOT installpkg, utilizará o caminho especificado. Isso é útil na configuraçăo de novos drives para o seu diretório raiz. Eles serăo montados tipicamente em /mnt ou em algum outro lugar diferente de /.
O banco de dados com os pacotes instalados é armazenado em /var/log/packages. O registro é um arquivo texto, sendo um para cada pacote. Se o pacote possui um script de pós-instalaçăo, este é escrito em /var/log/scripts/.
Vocę também pode especificar multiplos pacotes ou utilizar coringas no nome do pacote. O installpkg năo o avisará em caso de reinstalaçăo do pacote existente. Simplesmente instalará o novo pacote sobre o pacote antigo. Caso vocę queira remover com toda a segurança os arquivos antigos do pacote enterior vocę deverá utilizar o comando upgradepkg.
O removepkg(8) permite remover os pacotes instalados no sistema. A sintaxe é mostrada abaixo:
# removepkg option package_name
Quatro opçőes podem ser utilizadas com o removepkg. Porém somente uma opçăo pode ser utilizada por vez.
Opçőes do removepkg
| Opçăo | Açăo |
| -copy | É criado uma árvore de diretórios do pacote preservando o pacote original enquanto é removido. |
| -keep | Săo criados arquivos temporários durante a remoçăo. Possuem a finalidade de debug. |
| -preserve | O pacote é removido, mas uma cópia é realizada para preservar o pacote durante a remoçăo. |
| -warn | Exibe informaçőes sobre a remoçăo do pacote. |
Se vocę passar a variável de ambiente ROOT antes do removepkg, tal caminho será utilizado como diretório raiz. Isso é útil na configurarçăo de novos drives para o seu diretório raiz. Eles serăo montados tipicamente em /mnt ou em algum outro lugar diferente de /.
O removepkg procura os pacotes instalados e somente remove os arquivos referentes ao pacote que vocę especificou. Também irá procurar por um script de pós-instalaçăo para o pacote especificado e removerá os links simbólicos que foram criados pelo pacote.
Durante o processo de remoçăo, um status é mostrado. Após a remoçăo, o registro no banco de dados de pacote é movido para o arquivo /var/log/removed_pacotes e o script de pós-instalaçăo é movido para /var/log/removed_scripts.
Assim como o installpkg, vocę pode espeficicar os pacotes pelo nome ou utilizando os coringas para o nome do pacote.
O upgradepkg(8) atualiza um pacote instalado do Slackware package. A sintaxe é mostrada abaixo:
# upgradepkg nome_do_pacote
ou
# upgradepkg nome_pacote_antigo %nome_novo_pacote
O upgradepkg primeiro instala o novo pacote e em seguida remove o pacote antigo. Assim os arquivos antigos năo ficarăo no sistema. Caso o nome do pacote tenha sido alterado, utilize a sintaxe do sinal de porcentagem para informar o pacote antigo (aquele que está instalado) e o novo pacote (aquele que vocę está atualizando). Se vocę passar a variável de ambiente ROOT antes do upgradepkg, tal caminho será utilizado como diretório raiz. Isso é útil na configuraçăo de novos drives para o seu diretório raiz. Eles serăo montados tipicamente em /mnt ou em algum outro lugar diferente de /.
O upgradepkg năo é livre de falhas. Vocę sempre deverá realizar um backup dos seus arquivos de configuraçăo. Caso eles sejam removidos ou substituídos, vocę terá uma cópia dos arquivos originais caso necessite de algum reparo no sistema.
Assim como o installpkg e removepkg, vocę pode espeficicar os pacotes pelo nome ou utilizando os coringas para o nome do pacote.
Atualmente o Gerenciador de Pacotes da Red Hat é o sistema mais popular. Muitos softwares săo distribuídos no formato RPM. Mas este formato năo é o nosso padrăo, nós năo recomendamos que as pessoas confiem neles. Entretanto, algumas coisas só estăo disponíveis em pacotes RPM (até mesmo o código fonte).
Nós temos um programa que converte pacotes RPM em nosso formato padrăo .tgz. Isto é realizado, extraíndo o pacote (talvez com o explodepkg) para um diretório temporário e examinando o seu conteúdo.
rpm2tgz é o programa utilizado para criar um pacote Slackware com a extensăo .tgz enquanto que rpm2targz cria um arquivo com a extensăo .tar.gz.
Criar um pacote para o Slackware pode ser uma tarefa fácil ou difícil. Năo será especificado um método para a construçăo de um pacote. O único requisito para um pacote é ser um arquivo gzipado e, se houver algum script de pós-instalaçăo, este deve estar no arquivo /install/doinst.sh.
Se vocę é interessado em criar pacotes para o seu sistema ou para a rede que vocę gerencia, vocę deverá dar uma olhada nos diversos build scripts na árvore fonte do Slackware. Existem diversos métodos que podem ser utilizados para criar pacotes.
O explodepkg(8) faz a mesma coisa que o installpkg para extrair os arquivos do pacote, porém năo instala e năo registra o pacote no banco de dados. Apenas extrai os arquivos no diretório atual.
Se vocę verificar a árvore de fontes do Slackware, vocę verá que pode-se utilizar o comando para alicerçar os pacotes. Estes pacotes possuem um esqueleto que criará o pacote final. Ele contém todos os nomes de arquivos (tamanho-zero), permissőes, e donos. O build script criará um pacote a partir do diretório fonte do pacote .
O makepkg(8) cria um pacote válido para o Slackware a partir do diretório atual. Ele buscará na árvore de diretório por links simbólicos, adicionará e criará um script de pós-instalaçăo durante a criaçăo do pacote. Avisará por arquivos de tamanho zero na sua árvore de pacotes.
Este comando é usado após vocę criar sua árvore de pacotes.
Pacotes Slackware săo criados de muitas maneiras diferentes de acordo com a necessidade. Nem todos os pacotes săo criados pelos próprios programadores que os criaram. Muitos compilam com opçőes que năo săo inclusas nos pacotes do Slackware. Caso necessite de alguma funcionalidade da qual o pacote năo foi compilado, vocę deverá criar seu próprio pacote. Felizmente para muitos pacotes do Slackware, vocę pode encontrar scripts SlackBuild no código fonte do pacote.
Mas o que é um script SlackBuild? Scripts SlackBuild săo shell scripts executáveis que vocę executa como root para configurar, compilar, e criar pacotes Slackware. Vocę pode modificar os scripts e criar seus pacotes Slackwares com sua necessidades específicas.
O programa de configuraçăo do Slackware gerencia a instalaçăo dos pacotes no seu sistema. Existem arquivos que dizem ao programa de configuraçăo quais pacotes devem ser instalados, quais săo opcionais, e quais săo selecionados por padrăo pelo programa de configuraçăo.
Um tagfile está no diretório do primeiro conjunto de software e é chamado de tagfile. Ele lista os pacotes daquele disco em particular e o status, que pode ser:
Status das Opçőes do Tagfile
| Opçăo | Característica |
| ADD | O pacote é necessário para a execuçăo necessária do sistema |
| SKP | O pacote será automaticamente pulado |
| REC | O pacote năo é necessário, mas recomendado |
| OPT | O pacote é opcional |
O formato é simples:
nome_pacote: status
Um pacote por linha. As tagfiles originais de cada pacote săo armazenadas como um tagfile.org. Dessa forma, caso bagunce o seu, vocę pode restaurar o original.
Muitos administradores preferem escrever seus próprios tagfiles e recomeçar o instalador selecionando full. O programa da instalaçăo irá ler os tagfiles e executará a instalaçăo de acordo com seus índices. Caso vocę utilize REC ou OPT, uma caixa de diálogo será apresentada ao usuário perguntando se quer ou năo um pacote específico. Recomenda-se que vocę utilize ADD e SKP ao escrever tagfiles para automatizar instalaçăo.
Certifique-se apenas que seus tagfiles foram gravados no mesmo lugar que os originais. Ou vocę pode especificar um tagfile customizado, criado de acordo com as suas necessidades.
O ZipSlack é uma versăo especial do Slackware Linux. Ele é uma versăo já instalada do Slackware que está pronta para rodar a partir da sua partiçăo DOS ou Windows. É uma instalaçăo básica, e năo tem todos os recursos do Slackware.
O ZipSlack tem esse nome porque é distribuído em um grande arquivo .ZIP. Usuários de DOS e Windows provavelmente terăo mais familiaridade com esse tipo de arquivo. Eles săo arquivos compactados. O arquivo do ZipSlack contém tudo que vocę precisa para utilizar o Slackware.
É importante notar que o ZipSlack é significativamente diferente de uma instalaçăo normal. Apesar de funcionarem da mesma maneira e terem os mesmos programas, o público alvo e a suas funçőes săo diferentes. As principais vantagens e desvantagens do ZipSlack săo discutidas abaixo.
Uma última dica, vocę deve sempre consultar a documentaçăo incluída no diretório do ZipSlack. Ela contém as últimas informaçőes relativas a instalaçăo, boot e uso do produto.
Obter o ZipSlack é fácil. Se vocę comprou a caixa de CDs oficial do Slackware, entăo vocę já tem o ZipSlack. Apenas encontre o CD que contém o diretório zipslack e coloque-o no seu drive de CD-ROM. Esse CD costuma ser o terceiro ou o quarto disco, mas sempre confie mais nas etiquetas do que nessa documentaçăo já que o disco em que ele está pode mudar.
Se vocę quiser fazer o download do ZipSlack, vocę deve primeiro vistar nossa página Get Slack para obter as últimas informaçőes referentes a downloads:
http://www.slackware.com/getslack
O ZipSlack faz parte de todas as versőes do Slackware. Localize a versăo que vocę quer e vá para o diretório da mesma no FTP. A última versăo pode ser encontrada no seguinte endereço:
ftp://ftp.slackware.com/pub/slackware/slackware/
Vocę encontrará o ZipSlack no subdiretório /zipslack. Ele é distribuído como um grande arquivo .ZIP ou em partes do tamanho de um disquete. As partes estăo no diretório /zipslack/split.
Năo fique apenas com os arquivos .ZIP. Vocę também pode fazer o download da documentaçăo e qualquer imagem de boot que estiver no diretório do ZipSlack.
Após ter feito o download dos componentes necessários, vocę precisará extrair o arquivo .ZIP. Assegure-se que está usando um descompactador 32-bit. O tamanho e os nomes dos arquivos săo muito grandes para um descompactador de 16-bit. Exemplos de descompactadores 32-bit săo o WinZip e o PKZIP para Windows.
O ZipSlack é desenvolvido para ser descompactado no diretório raiz de uma unidade (tal como C: ou D:). Um diretório \LINUX onde estará a instalaçăo do Slackware será criado. Vocę também encontrará os arquivos necessários para iniciar (bootar) o sistema nesse diretório.
Após descompactar os arquivos, vocę terá um diretório \LINUX na unidade que vocę escolheu (nós usaremos C: a partir de agora).
Há varias maneiras de se bootar o ZipSlack. A mais comum é usar o arquivo LINUX.BAT para bootar o sistema a partir do DOS (ou a partir do modo DOS do Windows 9x). Esse arquivo deve ser editado para refletir seu sistema antes de utilizá-lo.
Comece abrindo o arquivo //C:\LINUX\LINUX.BAT // em seu editor de textos favorito. No topo do arquivo vocę verá um grande comentário. Ele explica o que vocę precisa editar nesse arquivo (e também o que fazer se vocę estiver bootando atravé de um Zip drive externo). Năo se preocupe se vocę năo entender o paramętro <literal>root=</literal>. Há vários exemplos, sinta-se a vontade para escolher um e testá-lo. Se năo funcionar, vocę pode editar o arquivo novamente, comentar a linha que vocę usou, e escolher outra.
Após habilitar a linha que vocę quiser, removendo a palavra rem do começo da linha, salve o arquivo e saia do editor de textos. Reboot sua máquina em modo DOS.
Um prompt do DOS no Windows 9x NĂO é suficiente.
Digite C:\LINUX\LINUX.BAT para bootar o sistema.
Se tudo correr bem, vocę deverá ver um prompt de login.
Logue como root, sem senha. Vocę provavelmente vai querer definir uma senha para root, assim como adicionar uma conta para vocę. A partir desse ponto vocę pode consultar outras seçőes desse livro sobre a utilizaçăo do sistema.
Se vocę năo conseguir bootar o sistema usando o arquivo LINUX.BAT, vocę deverá consultar o arquivo C:\LINUX\README.1ST incluso sobre outras formas de boot.
Ambiente gráfico
Uma interface gráfica para o usuário (GUI - Graphical User Interface) que é executado sobre o sistema de janelas X e provę as funcionalidades dos aplicativos instalados, interface coerente entre programas e componentes, gerenciadores de janelas e arquivos, etc. Um passo a frente de um simples gerenciador de janelas.
Área de troca (Swap)
Espaço do disco rígido que é utilizado pelo kernel como uma memória RAM virtual. É mais lento que a memória RAM, mas como espaço em disco é mais barato, a área de troca (swap) pode ser mais abundante. A área de troca é útil para o kernel manter dados năo muito utilizados e como opçăo quando a memória RAM está sendo toda utilizada.
Arquivo oculto (Dot file)
No Linux, os nomes de arquivos ocultos começam com um ponto ('.').
Biblioteca
Uma coleçăo de funçőes que podem ser compartilhadas entre programas.
Carregador dinâmico
Quando programas săo compilados no Linux, eles geralmente usam pedaços de código (funçőes) de bibliotecas externas. Quando estes programas executam, estas bibliotecas devem ser encontradas e as funçőes requeridas devem ser carregadas na memória. Esta é a funçăo do carregador dinâmico.
Código fonte
O código (mais ou menos) legível aos humanos com o qual a maioria dos programas săo escritos. Códigos fontes săo compilados em código binário.
Comandos internos do interpretador de comandos
Um comando do interpretador de comandos, ao invés de ser fornecido por um programa externo. Por exemplo, o bash tem o comando interno cd.
Compilar
Converter um código fonte em código binário.
Conjunto de ferramentas GUI
Um conjunto de ferramentas GUI, é uma coleçăo de bibliotecas que permite ao programador, a partir de códigos, desenhar componentes gráficos como barras de rolagem, checkboxes, etc. e construir uma interface gráfica. O conjunto de ferramentas GUI usado por um programa, geralmente define seu aspecto.
Conta
Todas informaçőes de um usuário, incluindo login, senha, informaçőes para o finger, UID, GID e diretório base. Criar uma conta é adicionar um usuário e criar suas definiçőes.
Daemon
Um programa designado para exectar em segundo plano e, sem a intervençăo de usuários, desempenha uma tarefa específica (geralmente provendo um serviço).
Darkstar
O hostname padrăo do Slackware; seu computador terá o nome de darkstar se vocę năo especificar outro. Um dos computadores de desenvolvimento de Patrick Volkerding, nomeado depois de Dark Star, uma música de Grateful Dead
Diretório base
O diretório base home de um usuário é o diretório em que o usuário é colocado imediatamente após registrar-se no sistema. Os usuários tem permissőes totais é, mais ou menos, um reino livre em seu diretório base.
Diretório raíz
Representado por /, o diretório raíz existe no topo do sistema de arquivos, com todos os outros diretórios se ramificando abaixo dele em uma árvore de arquivos.
Diretório de trabalho
O diretório em que um programa se considera estar enquanto está executando.
Disco de inicializaçăo
Um disquete contendo um sistema operacional (no nosso caso, o kernel do Linux) com o qual é possível iniciar um computador.
Disco raíz (rootdisk)
O disco (geralmente fixo) no qual o diretório raíz está armazenado.
Disco suplementar
No Slackware, é um disquete usado durante a instalaçăo que năo contém nem o kernel (que está no disco de inicializaçăo), nem o sistema de arquivos raiz (que está no disco raiz), mas contem arquivos adicionais necessários como módulos para rede ou suporte para PCMCIA.
DNS
Domain Name Service (Sistema de Nomes de Domínios). Um sistema que traduz nomes para endereços numéricos em uma rede de computadores.
Dotted quad
Formato do endereço IP, é assim chamado pois consiste em quatro números (na faixa decimal 0-255) separados por pontos.
Drivers de dispositivos
Um pedaço de código no kernel que controla diretamente uma parte do hardware.
Entrada padrăo (stdin)
A entrada de dados padrăo do Unix. Dados podem ser redirecionados ou concatenados para a stdin dos programas, vindos de qualquer fonte.
Época
Um período da história; em Unix, a Época começa ŕs 00:00:00 UTC Janeiro 1, 1970. Esta é considerada a alvorada do tempo pelo Unix e sistemas operacionais Unix-like, e todas outras datas săo calculadas em relaçăo a esta.
Framebuffer
Um tipo de dispositivo gráfico; no Linux, geralmente se refere ao programa framebuffer, o qual provę uma interface framebuffer padrăo para as aplicaçőes enquanto mantém drivers específicos ocultos. Esta camada de abstraçăo libera os programas de falarem com vários drivers de dispositivos.
FTP
O protocolo de transferęncia de arquivos (File Transfer Protocol). FTP é um método bastante utilizado para transferir dados entre computadores.
Gateway
Um computador que repassa dados de uma rede para outra.
Gerenciador de janelas
Um programa gráfico (ambiente X) que provę uma interface gráfica além do simples desenho retangular do Sistema de janelas X. Gerenciadores de janelas geralmente provęem barras de título, menus para os programas em execuçăo, etc.
GID
Identificador de grupo (Group IDentifier). O GID é um número único atribuído a um grupo de usuários.
Grupo
Usuários em Unix pertencem a grupos, que podem conter vários usuários e săo utilizados para controles de acessos mais generalizados, que é bem mais prático que dar permissőes para cada usuário individualmente.
GUI
Interface gráfica do usuário (Graphical User Interface). Uma interface de programas que utiliza elementos gráficos como botőes, barras de rolagem, janelas, etc. ao invés de somente entrada e saída de textos.
HOWTO
Um documento descrevendo como fazer (how to) algo, como configurar um firewall ou gerenciar usuários e grupos. Existe uma vasta coleçăo deste tipo de documento disponível no projeto de documentaçăo Linux (LDP - Linux Documentation Project).
HTTP
O protocolo de transferęncia de hiper-texto (HyperText Transfer Protocol). HTTP é o protocolo primário, no qual, a World Wide Web (WWW) opera.
ICMP
Protocolo de controle de mensagens na Internet (Internet Control Message Protocol). Um protocolo muito básico, utilizado geralmente para pings.
Interface de Rede
Uma representaçăo virtual de um dispositivo de rede, provido pelo kernel. Interfaces de rede permitem usuários e programas comunicarem com dispositivos de rede.
Interpretador de comandos (shell)
Os interpretadores de comandos provęem uma interface de linha de comando para o usuário. Quando vocę estiver olhando para uma tela em modo texto, vocę está em um interpretador de comandos.
LILO
O carregador do Linux (LInux LOader). O LILO é o gerenciador de inicializaçăo (boot) mais utilizado com o Linux.
Link simbólico
Um arquivo especial que simplesmente aponta para a localidade de um outro arquivo. Links simbólicos săo usados para evitar duplicaçăo de dados quando é necessário ter um determinado arquivo em vários locais.
LOADLIN
LOADLIN é um programa que é executado no MS-DOS ou Windows e inicializa um sistema Linux. É geralmente usado em computadores com múltiplos sistemas operacionais (incluindo Linux e DOS/Windows, é claro).
MBR
O registro mestre de inicializaçăo (Master Boot Record). Um espaço reservado no disco rígido onde estăo armazenadas as informaçőes sobre o que fazer durante a inicializaçăo. LILO e outros gerenciadores de inicializaçăo podem ser gravados aqui.
Módulo do kernel
Um pedaço do código do kernel, geralmente um tipo de driver, que pode ser carregado ou descarregado da memória separadamente do corpo principal do kernel. Módulos săo úteis para atualizar drivers ou testar configuraçőes do kernel, porque eles podem ser carregados e descarregados sem reiniciar.
MOTD
Mensagem do dia (Message Of The Day). O motd (armazenado no Linux em /etc/motd) é um arquivo de texto que é exibido a todos usuários durante seu registro no sistema (login). Tradicionalmente, é utilizado pelo administrador de sistemas como um quadro de avisos para se comunicar com os usuários.
Motif
Um conjunto de ferramentas de programaçăo popularmente utilizado em muitos programas X antigos.
NFS
O sistema de arquivo de rede (Network FileSystem). NFS permite montar sistemas de arquivos remotos como se fossem locais, provendo assim, um método transparente de compartilhamento de arquivos.
Nó de Dispositivo (Device Node)
Um tipo de arquivo especial no sistema de arquivos /dev que representa um componente de hardware para o sistema operacional.
Nome de domínio
O nome DNS de um computador, excluindo seu hostname.
Núcleo (Kernel)
O coraçăo do sistema operacional. O núcleo é a parte que provę controle básico de processos e interfaces com o hardware do computador.
Octal
Sistema de números de Base-8, com dígitos de 0-7.
Pacote de programas
Um programa e os arquivos a ele associados, empacotados e comprimidos em um único arquivo, junto com os scripts ou informaçőes necessárias para ajudar no gerenciamento da instalaçăo, atualizaçăo e remoçăo destes arquivos.
Pacote de senhas Shadow
O pacote de senhas shadow permite que senhas criptografadas sejam escondidas dos usuários, enquanto o resto das informaçőes do arquivo /etc/passwd permanecem visíveis para todos. Isto ajuda a prevenir ataques de brute-force para quebrar senhas.
Pager
Um programa gráfico (X) que permite aos usuários visualisar e alternar entre várias áreas de trabalho.
Partiçăo
Uma divisăo do disco rígido. Sistemas de arquivos residem sobre as partiçőes.
Ponto de montagem
Um diretório vazio em um sistema de arquivos onde um outro sistema de arquivos pode ser montado ou anexado.
PPP
Protocolo Ponto-a-Ponto (Point-to-Point Protocol). PPP é utilizado principalmente para conectar, via modem, a um provedor de serviços de Internet (ISP - Internet Service Provider).
Primeiro plano
Um programa que aceita entrada de um terminal é dito que está sendo executado em primeiro plano.
Processo
Um programa em execuçăo.
Processo suspenso
Um processo que foi congelado até que seja morto ou reiniciado.
Programa wrapper
Um programa cuja a única finalidade é executar outros programas, mas que as vezes muda seu comportamento alterando seus ambientes ou filtrando sua entrada.
Runlevel
O estado geral do sistema, definido pelo init. Runlevel 6 significa reíniciar o computador (reboot), runlevel 1 é o modo monousuário, runlevel 4 é o login em modo gráfico, etc. Existem 6 runlevels disponíveis em um sistema Slackware.
Saída padrăo (stdout)
A saída padrăo de informaçőes no Unix. Textos normais de saída săo reportados na stdout, que é separada das mensagens de erro, reportadas na stderr, e podem ser concatenadas ou redirecionadas para a stdin de outros programas ou para um arquivo.
Saída padrăo de erro (stderr)
O padrăo Unix para reportar erros. Os programas reportam qualquer mensagem de erro na stderr, desta forma esta pode ser separa de uma saída normal.
Seçăo Man
Páginas no padrăo de manuais online do Unix (man) săo agrupadas em seçőes para facilitar referęncias. Todas as páginas sobre programaçăo em C estăo na seçăo 3, páginas sobre administraçăo de sistemas estăo na seçăo 5, etc.
Segundo plano (Background)
Qualquer processo que esteja executando e năo aceite entradas ou controles do terminal é dito que está sendo executado em segundo plano.
Séries de programas
Uma coleçăo de pacotes de softwares relacionados no Slackware. Todos os pacotes do KDE estăo na série kde, pacotes de rede estăo na série n, etc.
Serviço
O compartilhamento de informaçőes e/ou dados entre programas ou computadores de um único servidor para múltiplos clientes. HTTP, FTP, NFS, etc. săo serviços.
Servidor de nomes
Um servidor de informaçőes DNS. Servidores de nomes traduzem nomes DNS em endereços IP numéricos.
Servidor X
Um programa no Sistema de Janelas X que faz a interface com o hardware gráfico e abriga os programas gráficos que estăo em execuçăo.
Shell seguro (SSH - Secure SHell)
Um método encriptado (assim seguro) de se conectar remotamente a um computador. Muitos programas de shell seguro estăo disponíveis; ambos cliente e servidor săo necessários.
Sinal
Programas Unix podem comunicar uns com os outros através de simples sinais, os quais săo enumerados e geralmente possuem significados específicos. kill -l listará os sinais disponíveis.
Sistema de arquivos
Uma representaçăo dos dados armazenados onde arquivos de dados săo mantidos organizados em diretórios. O sistema de arquivos é a forma de representaçăo, mais próxima da universal, de dados armazenados em discos (tanto fixos como removíveis).
Sistema de janelas X
Interface gráfica com suporte a rede usada na maioria dos sistemas operacionais Unix-like, incluindo o Linux.
SLIP
Protocolo de interface de linha serial (Serial Line Interface Protocol). SLIP é um protocolo similar ao PPP e é utilizado para conectar duas máquinas via interface serial.
Sub-rede
Uma faixa de endereços IP que é parte de uma faixa maior. Por exemplo, 192.168.1.0 é uma sub-rede de 192.168.0.0 (onde 0 é uma mascara indefinida); é, na verdade, a sub-rede .1.
Superbloco
No Linux as partiçőes săo definidas em blocos. Um bloco possui 512 bytes. O superbloco săo os primeiros 512 bytes de uma partiçăo.
Tabela de roteamento
Um conjunto de informaçőes que o kernel utiliza para rotear dados ao redor da rede. Possui informaçőes como: onde está o seu gateway default, qual interface de rede está conectada a determinada rede, etc.
Tagfile
Um arquivo usado pelo programa de configuraçăo (setup) do Slackware durante a instalaçăo, o qual descreve um conjunto de pacotes a serem instalados.
Terminal
Uma interface homem-máquina que consiste de pelo menos uma tela (ou tela virtual) e de algum método de entrada de dados (geralmente um teclado).
Terminal virtual
O uso de programas para simular múltiplos terminais enquanto utiliza um simples conjunto de dispositivos de entrada/saída (teclado, monitor, mouse). Um conjunto especial de teclas, ao serem pressionadas, alterna entre os terminais virtuais a partir de um único terminal físico.
UID
Identificador de usuário (User IDentifier). Um número único que identifica um usuário no sistema. UIDs săo usados pela maioria dos programas ao invés dos nomes de usuário, uma vez que números săo mais fáceis de manejar; nomes de usuário geralmente săo usados somente quando o usuário precisa ver as coisas acontecendo.
Variável de ambiente
Uma variável configurada no shell do usuário que pode ser referenciada pelo usuário ou por programas executados por este usuário nesta shell. Variáveis de ambiente săo geralmente utilizadas para armazenar preferęncias e parâmetros padrăo.
VESA
Associaçăo de padrőes eletrônicos de video (Video Electronics Standards Association). O termo VESA é geralmente usado para denotar um padrăo especificado por esta associaçăo. Atualmente todos os adaptadores de vídeo modernos săo compatíveis com VESA.
GNU GENERAL PUBLIC LICENSE
Version 2, June 1991 Copyright (C) 1989, 1991 Free Software Foundation, Inc. 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
The licenses for most software are designed to take away your freedom to share and change it. By contrast, the GNU General Public License is intended to guarantee your freedom to share and change free software--to make sure the software is free for all its users. This General Public License applies to most of the Free Software Foundation's software and to any other program whose authors commit to using it. (Some other Free Software Foundation software is covered by the GNU Library General Public License instead.) You can apply it to your programs, too.
When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for this service if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs; and that you know you can do these things.
To protect your rights, we need to make restrictions that forbid anyone to deny you these rights or to ask you to surrender the rights. These restrictions translate to certain responsibilities for you if you distribute copies of the software, or if you modify it.
For example, if you distribute copies of such a program, whether gratis or for a fee, you must give the recipients all the rights that you have. You must make sure that they, too, receive or can get the source code. And you must show them these terms so they know their rights.
We protect your rights with two steps: (1) copyright the software, and (2) offer you this license which gives you legal permission to copy, distribute and/or modify the software.
Also, for each author's protection and ours, we want to make certain that everyone understands that there is no warranty for this free software. If the software is modified by someone else and passed on, we want its recipients to know that what they have is not the original, so that any problems introduced by others will not reflect on the original authors' reputations.
Finally, any free program is threatened constantly by software patents. We wish to avoid the danger that redistributors of a free program will individually obtain patent licenses, in effect making the program proprietary. To prevent this, we have made it clear that any patent must be licensed for everyone's free use or not licensed at all.
The precise terms and conditions for copying, distribution and modification follow.
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
These requirements apply to the modified work as a whole. If identifiable sections of that work are not derived from the Program, and can be reasonably considered independent and separate works in themselves, then this License, and its terms, do not apply to those sections when you distribute them as separate works. But when you distribute the same sections as part of a whole which is a work based on the Program, the distribution of the whole must be on the terms of this License, whose permissions for other licensees extend to the entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest your rights to work written entirely by you; rather, the intent is to exercise the right to control the distribution of derivative or collective works based on the Program.
In addition, mere aggregation of another work not based on the Program with the Program (or with a work based on the Program) on a volume of a storage or distribution medium does not bring the other work under the scope of this License.
The source code for a work means the preferred form of the work for making modifications to it. For an executable work, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the executable. However, as a special exception, the source code distributed need not include anything that is normally distributed (in either source or binary form) with the major components (compiler, kernel, and so on) of the operating system on which the executable runs, unless that component itself accompanies the executable.
If distribution of executable or object code is made by offering access to copy from a designated place, then offering equivalent access to copy the source code from the same place counts as distribution of the source code, even though third parties are not compelled to copy the source along with the object code.
- You are not required to accept this License, since you have not signed it. However, nothing else grants you permission to modify or distribute the Program or its derivative works. These actions are prohibited by law if you do not accept this License. Therefore, by modifying or distributing the Program (or any work based on the Program), you indicate your acceptance of this License to do so, and all its terms and conditions for copying, distributing or modifying the Program or works based on it.
- Each time you redistribute the Program (or any work based on the Program), the recipient automatically receives a license from the original licensor to copy, distribute or modify the Program subject to these terms and conditions. You may not impose any further restrictions on the recipients' exercise of the rights granted herein. You are not responsible for enforcing compliance by third parties to this License.
- If, as a consequence of a court judgment or allegation of patent infringement or for any other reason (not limited to patent issues), conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot distribute so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not distribute the Program at all. For example, if a patent license would not permit royalty-free redistribution of the Program by all those who receive copies directly or indirectly through you, then the only way you could satisfy both it and this License would be to refrain entirely from distribution of the Program.
If any portion of this section is held invalid or unenforceable under any particular circumstance, the balance of the section is intended to apply and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any patents or other property right claims or to contest validity of any such claims; this section has the sole purpose of protecting the integrity of the free software distribution system, which is implemented by public license practices. Many people have made generous contributions to the wide range of software distributed through that system in reliance on consistent application of that system; it is up to the author/donor to decide if he or she is willing to distribute software through any other system and a licensee cannot impose that choice.
This section is intended to make thoroughly clear what is believed to be a consequence of the rest of this License.
- If the distribution and/or use of the Program is restricted in certain countries either by patents or by copyrighted interfaces, the original copyright holder who places the Program under this License may add an explicit geographical distribution limitation excluding those countries, so that distribution is permitted only in or among countries not thus excluded. In such case, this License incorporates the limitation as if written in the body of this License.
- The Free Software Foundation may publish revised and/or new versions of the General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Program specifies a version number of this License which applies to it and "any later version", you have the option of following the terms and conditions either of that version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of this License, you may choose any version ever published by the Free Software Foundation.
- NO WARRANTY
BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
- IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
END OF TERMS AND CONDITIONS
If you develop a new program, and you want it to be of the greatest possible use to the public, the best way to achieve this is to make it free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest to attach them to the start of each source file to most effectively convey the exclusion of warranty; and each file should have at least the "copyright" line and a pointer to where the full notice is found.
//<one line to give the program's name and a brief idea of what it does.> Copyright (C) <year> <name of author> //
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA//
Also add information on how to contact you by electronic and paper mail.
If the program is interactive, make it output a short notice like this when it starts in an interactive mode:
''' Gnomovision version 69, Copyright (C) year name of author
Gnomovision comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it under certain conditions; type `show c' for details. '''
The hypothetical commands `show w' and `show c' should show the appropriate parts of the General Public License. Of course, the commands you use may be called something other than `show w' and `show c'; they could even be mouse-clicks or menu items--whatever suits your program.
You should also get your employer (if you work as a programmer) or your school, if any, to sign a "copyright disclaimer" for the program, if necessary. Here is a sample; alter the names:
Yoyodyne, Inc., hereby disclaims all copyright interest in the program
`Gnomovision' (which makes passes at compilers) written by James Hacker.
<signature of Ty Coon>, 1 April 1989
Ty Coon, President of Vice
This General Public License does not permit incorporating your program into proprietary programs. If your program is a subroutine library, you may consider it more useful to permit linking proprietary applications with the library. If this is what you want to do, use the GNU Library General Public License instead of this License.
| Author | Contribution |
| David Cantrell | Co-author of first edition. |
| Alan Hicks | Project Organizer, lead author of second edition. |
| Logan Johnson | Co-author of first edition. |
| Keith Keller | Wrote the wireless networking section. |
| Joost Kremers | Contributed the Emacs chapter. |
| Chris Lumens | Co-author of first edition. |
| Jurgen Philippaerts | Updated the Basic Networking Commands chapter. |
| David G. Sizemore | Updated the Introduction |
| Murray Stokely | Wrote the Preface, index, and prepared the book for print publication |
| Simon Williams | Contributed the Emacs chapter. |
| Diogo Leal (estranho) | Traduçăo | Revisăo | Site |
| Bruno T. Russo (BrunoRusso) | Traduçăo | Revisăo | Site |
| Ellington Santos | Revisăo | Repositório SVN | |
| Artur Souza (MoRpHeUz) | Traduçăo | Revisăo | |
| Thiago Diniz | Traduçăo | Revisăo | |
| José Luiz Moquenco de Figueiredo (zecafig) | Traduçăo | Revisăo | |
| Waldemar Silva Júnior (wsjunior) | Traduçăo | Revisăo | |
| Joăo Carlos de Oliveira Coutinho (BitDesigner) | Traduçăo | Revisăo | |
| Raphael Bastos (chemonz) | Compilaçăo | ||
| Gabriel Favaro | Traduçăo | Revisăo | |
| Rodrigo Amorim Ferreira | Traduçăo | Revisăo | |
| Tiago T3 | Traduçăo | Revisăo | |
| Neumar Malheiros | Traduçăo | Revisăo | |
| Gabriel Marrocos Magalhăes (Manda_Chuva) | |||
| Ariel | |||
| Jairo | |||
| Lucas | |||
| Frederico |
Agradecemos muito a todos que contribuiram indiretamente, fazendo com que este projeto fosse possível